25、Flink 基础 - 时间语义和Watermark
一、Flink中的时间语义
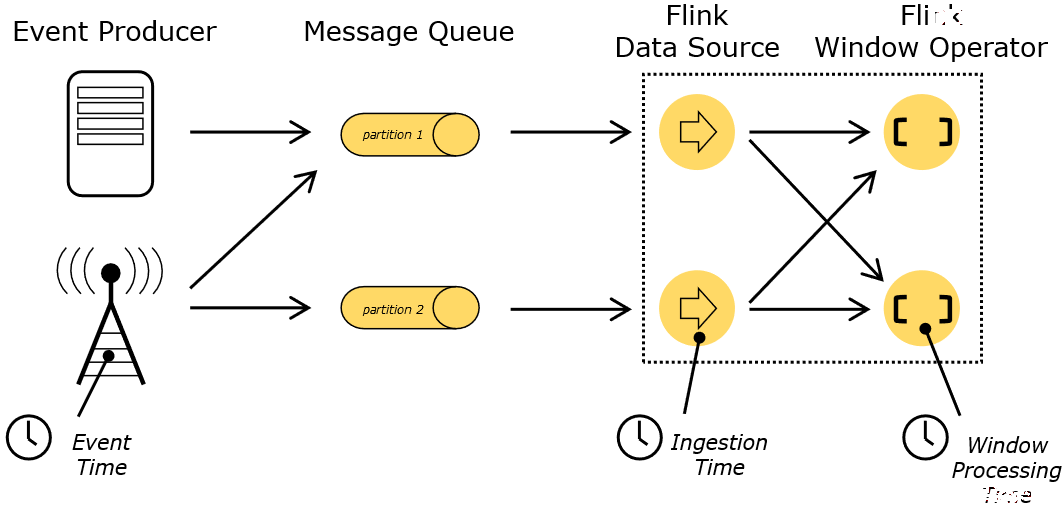
1、 EventTime:事件创建时间;
2、 IngestionTime:数据进入Flink的时间;
3、 ProcessingTime:执行操作算子的本地系统时间,与机器相关;
Event Time是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
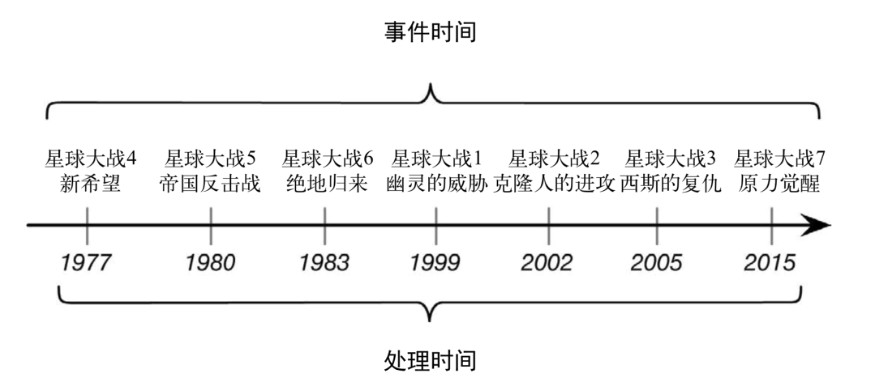
不同的时间语义有不同的应用场合
我们往往更关心事件事件(Event Time)
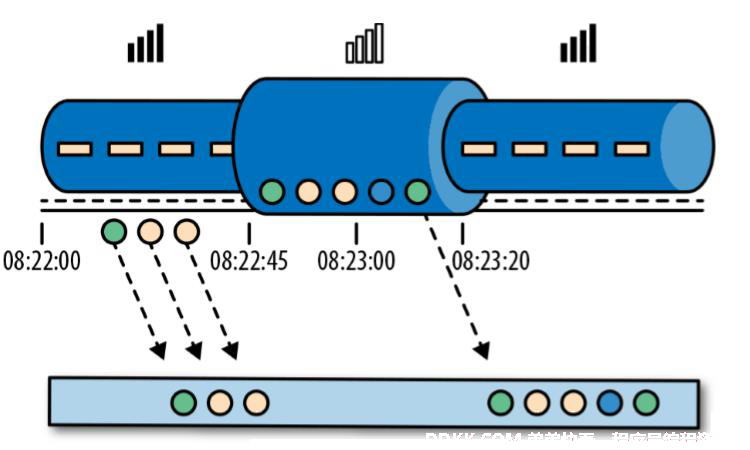
这里假设玩游戏,两分钟内如果过5关就有奖励。用户坐地铁玩游戏,进入隧道前已经过3关,在隧道中又过了2关。但是信号不好,后两关通关的信息,等到出隧道的时候(8:23:20)才正式到达服务器。
如果为了用户体验,那么应该按照Event Time处理信息,保证用户获得游戏奖励。
Event Time可以从日志数据的时间戳(timestamp)中提取
2017-11-02 18:27:15.624 INFO Fail over to rm
二、EventTime的引入
在Flink的流式处理中,绝大部分的业务都会使用eventTime,一般只在eventTime无法使用时,才会被迫使用ProcessingTime或者IngestionTime。
(虽然默认环境里使用的就是ProcessingTime,使用EventTime需要另外设置)
如果要使用EventTime,那么需要引入EventTime的时间属性,引入方式如下所示:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从调用时刻开始给env创建的每一个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
注:具体的时间,还需要从数据中提取时间戳。
三、 Watermark
3.1 概念
Flink对于迟到数据有三层保障,先来后到的保障顺序是:
1、 WaterMark=>约等于放宽窗口标准;
2、 allowedLateness=>允许迟到(ProcessingTime超时,但是EventTime没超时);
3、 sideOutputLateData=>超过迟到时间,另外捕获,之后可以自己批处理合并先前的数据;
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
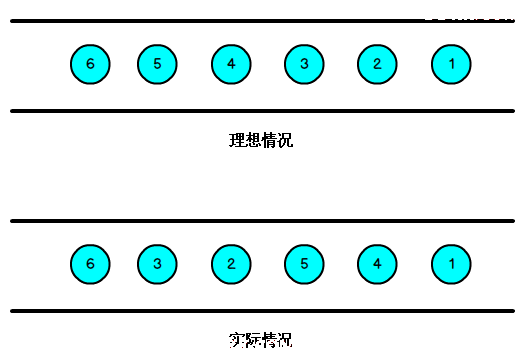
那么此时出现一个问题,一旦出现乱序,如果只根据eventTime决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是Watermark。
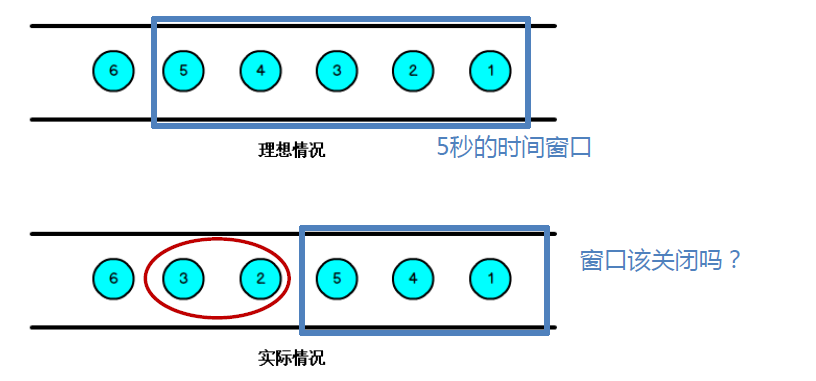
1、 当Flink以EventTime模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子;
(比如5s一个窗口,那么理想情况下,遇到时间戳是5s的数据时,就认为[0,5s)时间段的桶bucket就可以关闭了。) 2、 实际由于网络、分布式传输处理等原因,会导致乱序数据的产生;
3、 乱序数据会导致窗口计算不准确;
(如果按照前面说法,获取到5s时间戳的数据,但是2s,3s乱序数据还没到,理论上不应该关闭桶)
怎样避免乱序数据带来的计算不正确?
遇到一个时间戳达到了窗口关闭时间,不应该立即触发窗口计算,而是等待一段时间,等迟到的数据来了再关闭窗口
1、 Watermark是一种衡量EventTime进展的机制,可以设定延迟触发;
2、 Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现;
3、 数据流中的Watermark用于表示”timestamp小于Watermark的数据,都已经到达了“,因此,window的执行也是由Watermark触发的;
4、 Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime-t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime–t,那么这个窗口被触发执行;
Watermark = maxEventTime-延迟时间t 5、 watermark用来让程序自己平衡延迟和结果正确性;
watermark可以理解为把原本的窗口标准稍微放宽了一点。(比如原本5s,设置延迟时间=2s,那么实际等到7s的数据到达时,才认为是[0,5)的桶需要关闭了)
有序流的Watermarker如下图所示:(延迟时间设置为0s)
此时以5s一个窗口,那么EventTime=5s的元素到达时,关闭第一个窗口,下图即W(5),W(10)同理。
3.2 Watermark的特点
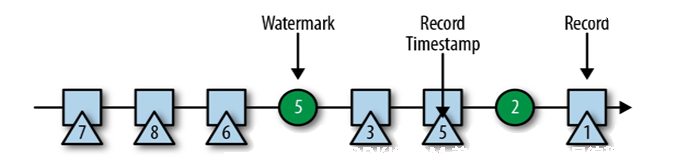
1、 watermark是一条特殊的数据记录;
2、 watermark必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退;
3、 watermark与数据的时间戳相关;
3.3 Watermark的传递
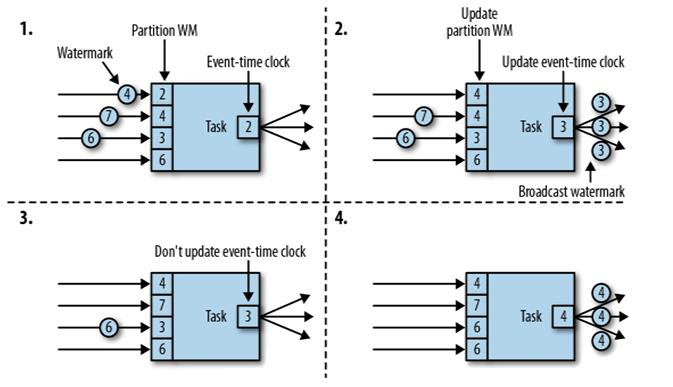
1、 图一,当前Task有四个上游Task给自己传输WaterMark信息,通过比较,只取当前最小值作为自己的本地Event-timeclock,上图中,当前Task[0,2)的桶就可关闭了,因为所有上游中2s最小,能保证2s的WaterMark是准确的(所有上游Watermark都已经>=2s)这时候将Watermark=2广播到当前Task的下游;
2、 图二,上游的Watermark持续变动,此时Watermark=3成为新的最小值,更新本地Task的event-timeclock,同时将最新的Watermark=3广播到下游;
3、 图三,上游的Watermark虽然更新了,但是当前最小值还是3,所以不更新event-timeclock,也不需要广播到下游;
4、 图四,和图二同理,更新本地event-timeclock,同时向下游广播最新的Watermark=4;
3.4 Watermark的引入
watermark的引入很简单,对于乱序数据,最常见的引用方式如下:
dataStream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.milliseconds(1000)) {
@Override
public long extractTimestamp(element: SensorReading): Long = {
return element.getTimestamp() * 1000L;
}
});
Event Time的使用一定要指定数据源中的时间戳。否则程序无法知道事件的事件时间是什么(数据源里的数据没有时间戳的话,就只能使用Processing Time了)。
我们看到上面的例子中创建了一个看起来有点复杂的类,这个类实现的其实就是分配时间戳的接口。Flink暴露了TimestampAssigner接口供我们实现,使我们可以自定义如何从事件数据中抽取时间戳。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置事件时间语义 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<SensorReading> dataStream = env.addSource(new SensorSource()) .assignTimestampsAndWatermarks(new MyAssigner());
MyAssigner有两种类型:
1、 AssignerWithPeriodicWatermarks;
2、 AssignerWithPunctuatedWatermarks;
以上两个接口都继承自TimestampAssigner。
TimestampAssigner
AssignerWithPeriodicWatermarks
周期性的生成 watermark:系统会周期性的将 watermark 插入到流中
默认周期是200毫秒,可以使用 ExecutionConfig.setAutoWatermarkInterval() 方法进行设置
升序和前面乱序的处理 BoundedOutOfOrderness ,都是基于周期性 watermark 的。
AssignerWithPunctuatedWatermarks
没有时间周期规律,可打断的生成 watermark(即可实现每次获取数据都更新watermark)
3.5 Watermark的设定
1、 在Flink中,Watermark由应用程序开发人员生成,这通常需要对相应的领域有一定的了解;
2、 如果Watermark设置的延迟太久,收到结果的速度可能就会很慢,解决办法是在水位线到达之前输出一个近似结果;
3、 如果Watermark到达得太早,则可能收到错误结果,不过Flink处理迟到数据的机制可以解决这个问题;
一般大数据场景都是考虑高并发情况,所以一般使用周期性生成Watermark的方式,避免频繁地生成Watermark。
注:一般认为Watermark的设置代码,在里Source步骤越近的地方越合适。
四、 测试代码
4.1 测试Watermark和迟到数据
这里设置的Watermark的延时时间是2s,实际一般设置和window大小一致。
代码:
package org.flink.window;
import org.flink.beans.SensorReading;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;
/**
* @remark : 测试Watermark和迟到数据
*/
public class WindowTest4_EventTimeWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.getConfig().setAutoWatermarkInterval(100);
// socket文本流
DataStream<String> inputStream = env.socketTextStream("10.31.1.122", 7777);
// 转换成SensorReading类型,分配时间戳和watermark
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
})
// 升序数据设置事件时间和watermark
// .assignTimestampsAndWatermarks(new AscendingTimestampExtractor<SensorReading>() {
// @Override
// public long extractAscendingTimestamp(SensorReading element) {
// return element.getTimestamp() * 1000L;
// }
// })
// 乱序数据设置时间戳和watermark
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(2)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTimestamp() * 1000L;
}
});
OutputTag<SensorReading> outputTag = new OutputTag<SensorReading>("late") {
};
// 基于事件时间的开窗聚合,统计15秒内温度的最小值
SingleOutputStreamOperator<SensorReading> minTempStream = dataStream.keyBy("id")
.timeWindow(Time.seconds(15))
.allowedLateness(Time.minutes(1))
.sideOutputLateData(outputTag)
.minBy("temperature");
minTempStream.print("minTemp");
minTempStream.getSideOutput(outputTag).print("late");
env.execute();
}
}
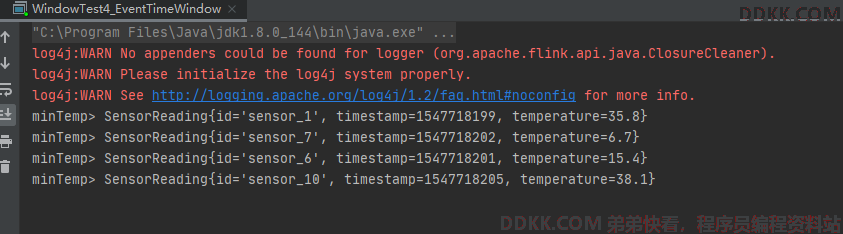
启动远程nc服务,查看结果:
nc -lk 7777
输入:
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,36.3
sensor_1,1547718211,34
sensor_1,1547718212,31.9
sensor_1,1547718212,31.9
sensor_1,1547718212,31.9
sensor_1,1547718212,31.9
输出:
4.2 分析
4.2.1 计算窗口起始位置Start和结束位置End
从TumblingProcessingTimeWindows类里的assignWindows方法,我们可以得知窗口的起点计算方法如下: 窗 口 起 点 s t a r t = t i m e s t a m p − ( t i m e s t a m p − o f f s e t + W i n d o w S i z e ) 窗口起点start = timestamp - (timestamp -offset+WindowSize) % WindowSize 窗口起点start=timestamp−(timestamp−offset+WindowSize) 由于我们没有设置offset,所以这里start=第一个数据的时间戳1547718199-(1547718199-0+15)%15=1547718195
计算得到窗口初始位置为Start = 1547718195,那么这个窗口理论上本应该在1547718195+15的位置关闭,也就是End=1547718210
@Override
public Collection<TimeWindow> assignWindows(
Object element, long timestamp, WindowAssignerContext context) {
final long now = context.getCurrentProcessingTime();
if (staggerOffset == null) {
staggerOffset =
windowStagger.getStaggerOffset(context.getCurrentProcessingTime(), size);
}
long start =
TimeWindow.getWindowStartWithOffset(
now, (globalOffset + staggerOffset) % size, size);
return Collections.singletonList(new TimeWindow(start, start + size));
}
// 跟踪 getWindowStartWithOffset 方法得到TimeWindow的方法
public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) {
return timestamp - (timestamp - offset + windowSize) % windowSize;
}
4.2.2 计算修正后的Window输出结果的时间
测试代码中Watermark设置的maxOutOfOrderness最大乱序程度是2s,所以实际获取到End+2s的时间戳数据时(达到Watermark),才认为Window需要输出计算的结果(不关闭,因为设置了允许迟到1min)
所以实际应该是1547718212的数据到来时才触发Window输出计算结果。
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(2)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTimestamp() * 1000L;
}
});
// BoundedOutOfOrdernessTimestampExtractor.java
public BoundedOutOfOrdernessTimestampExtractor(Time maxOutOfOrderness) {
if (maxOutOfOrderness.toMilliseconds() < 0) {
throw new RuntimeException(
"Tried to set the maximum allowed "
+ "lateness to "
+ maxOutOfOrderness
+ ". This parameter cannot be negative.");
}
this.maxOutOfOrderness = maxOutOfOrderness.toMilliseconds();
this.currentMaxTimestamp = Long.MIN_VALUE + this.maxOutOfOrderness;
}
@Override
public final Watermark getCurrentWatermark() {
// this guarantees that the watermark never goes backwards.
long potentialWM = currentMaxTimestamp - maxOutOfOrderness;
if (potentialWM >= lastEmittedWatermark) {
lastEmittedWatermark = potentialWM;
}
return new Watermark(lastEmittedWatermark);
}
4.3.3 为什么上面输入中,最后连续四条相同输入,才触发Window输出结果?
1、 Watermark会向子任务广播;
我们在map才设置Watermark,map根据Rebalance轮询方式分配数据。所以前4个输入分别到4个slot中,4个slot计算得出的Watermark不同(分别是1547718199-2,1547718201-2,1547718202-2,1547718205-2) 2、 Watermark传递时,会选择当前接收到的最小一个作为自己的Watermark;
前4次输入中,有些map子任务还没有接收到数据,所以其下游的keyBy后的slot里watermark就是Long.MIN_VALUE(因为4个上游的Watermark广播最小值就是默认的Long.MIN_VALUE)
并行度4,在最后4个相同的输入,使得Rebalance到4个map子任务的数据的currentMaxTimestamp都是1547718212,经过getCurrentWatermark()的计算(currentMaxTimestamp-maxOutOfOrderness),4个子任务都计算得到watermark=1547718210,4个map子任务向4个keyBy子任务广播watermark=1547718210,使得keyBy子任务们获取到4个上游的Watermark最小值就是1547718210,然后4个KeyBy子任务都更新自己的Watermark为1547718210。 3、 根据Watermark的定义,我们认为>=Watermark的数据都已经到达由于此时watermark>=窗口End,所以Window输出计算结果(4个子任务,4个结果);
3.7 窗口起始点和偏移量
时间偏移一个很大的用处是用来调准非0时区的窗口,例如:在中国你需要指定一个8小时的时间偏移。