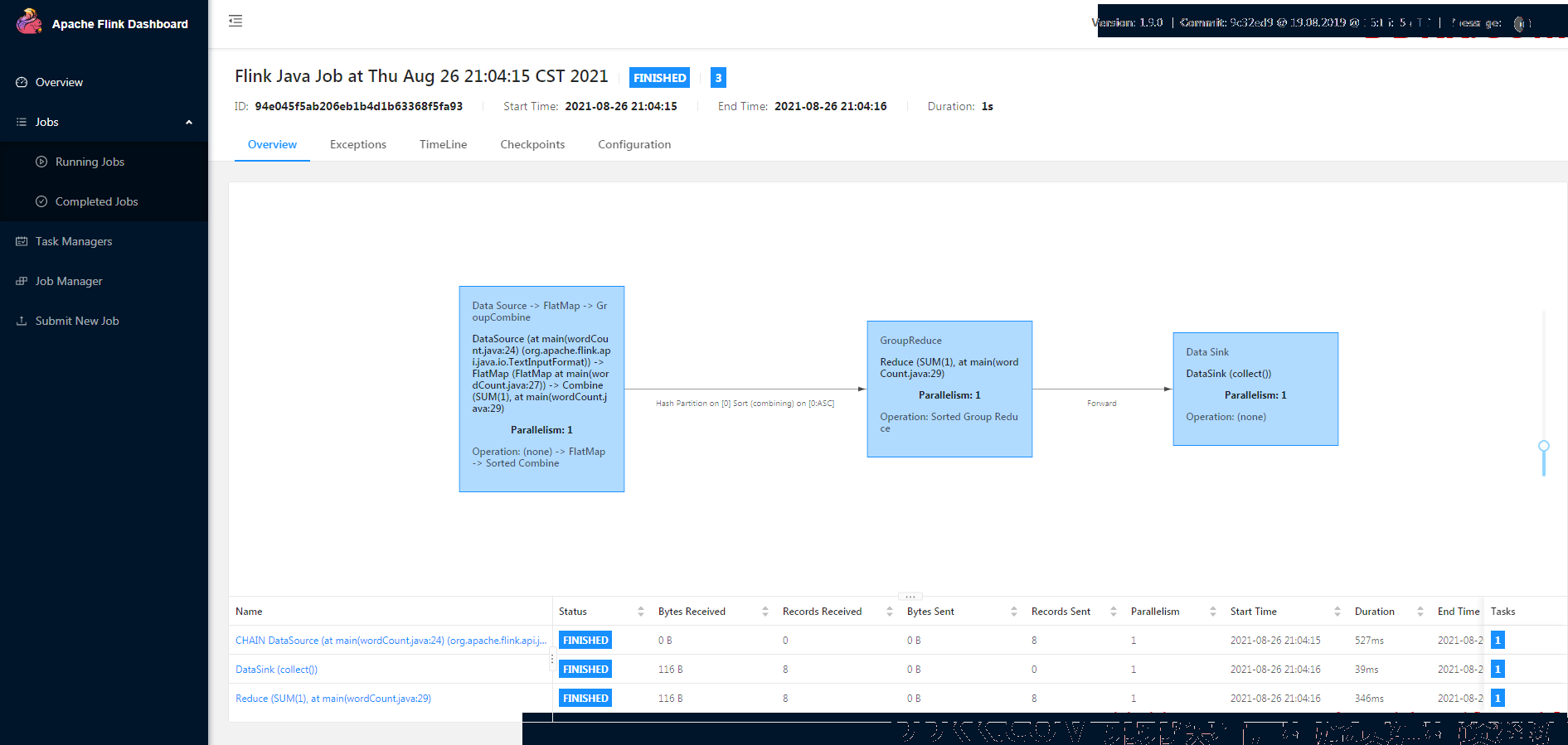
07、Flink 基础 - 通过Web UI执行jar文件
环境准备
本地Windows环境已安装Flink 1.9.0版本。
一、准备代码
1.1 maven准备
配置Flink的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.9.0</version>
</dependency>
1.2 Java代码准备
还是以大家耳熟能详的wordCount程序为例
package com.zqs.study.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.util.Collector;
/*
* @remark Flink的第一个wordCount程序
*/
public class wordCount {
public static void main(String[] args) throws Exception{
//创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//从文件中读取数据
String inputPath = "C:\\Users\\Administrator\\IdeaProjects\\FlinkStudy\\src\\main\\java\\com\\zqs\\study\\flink\\hello.txt";
DataSet<String> inputDataSet = env.readTextFile(inputPath);
// 对数据集进行处理,按空格分词展开,转换成(word, 1)二元组进行统计
DataSet<Tuple2<String, Integer>> resultSet = inputDataSet.flatMap(new MyFlatMapper())
.groupBy(0) // 按照第一个位置的word分组
.sum(1); // 将第二个位置上的数据求和;
resultSet.print();
//env.execute();
//env.execute("Word Count Example");
}
//自定义类,实现FlatMapFunction接口
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//按空格分词
String[] words = value.split(" ");
//遍历所有word,包成二元组输出
for (String word : words) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
二、打包
我这边是直接package了,一般步骤是clean、complie、test、package
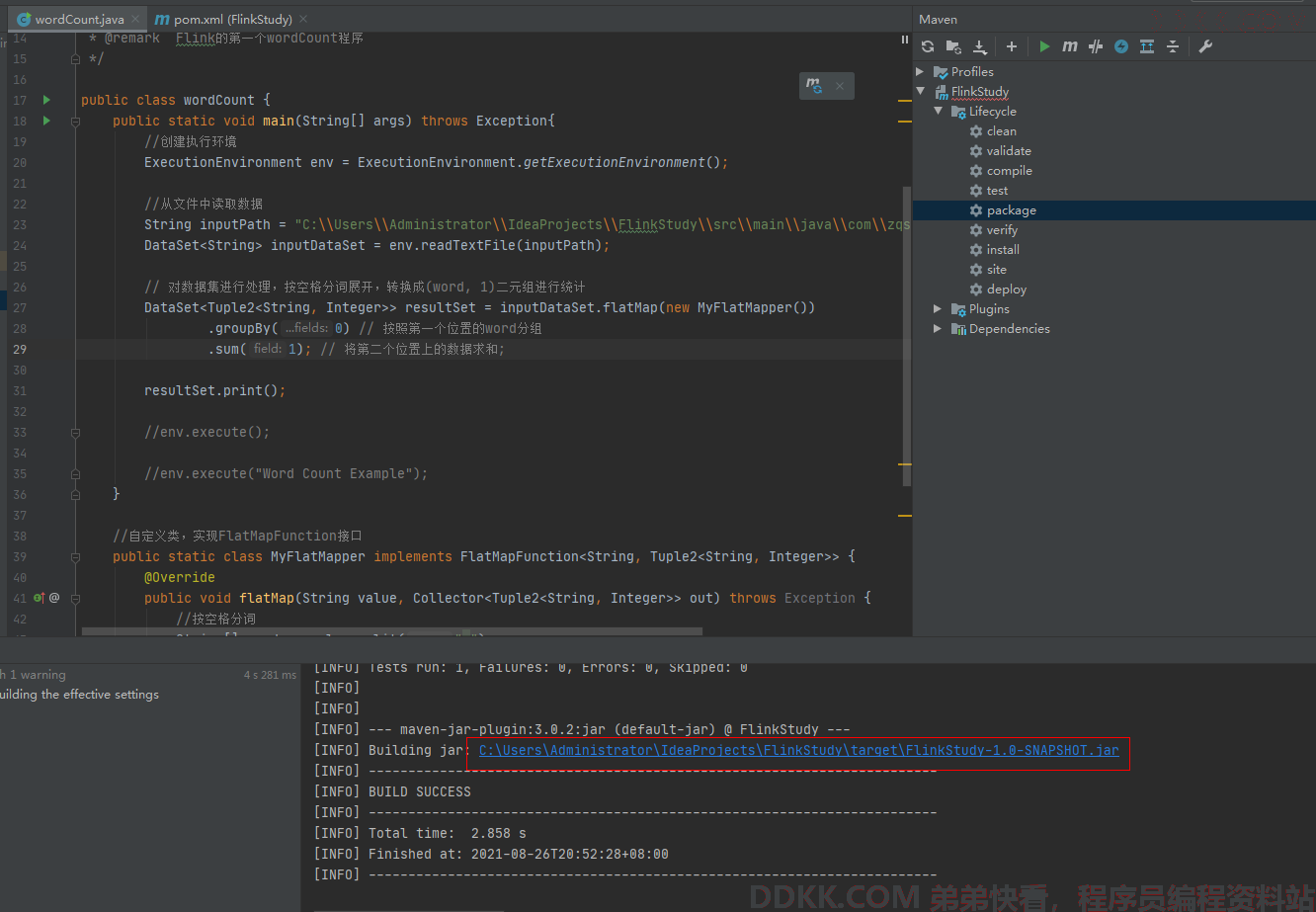
如下截图是打包生成的文件路径
三、通过Web UI执行jar文件
3.1 上传文件
选择"Submit New Job"后,选择"Add New"
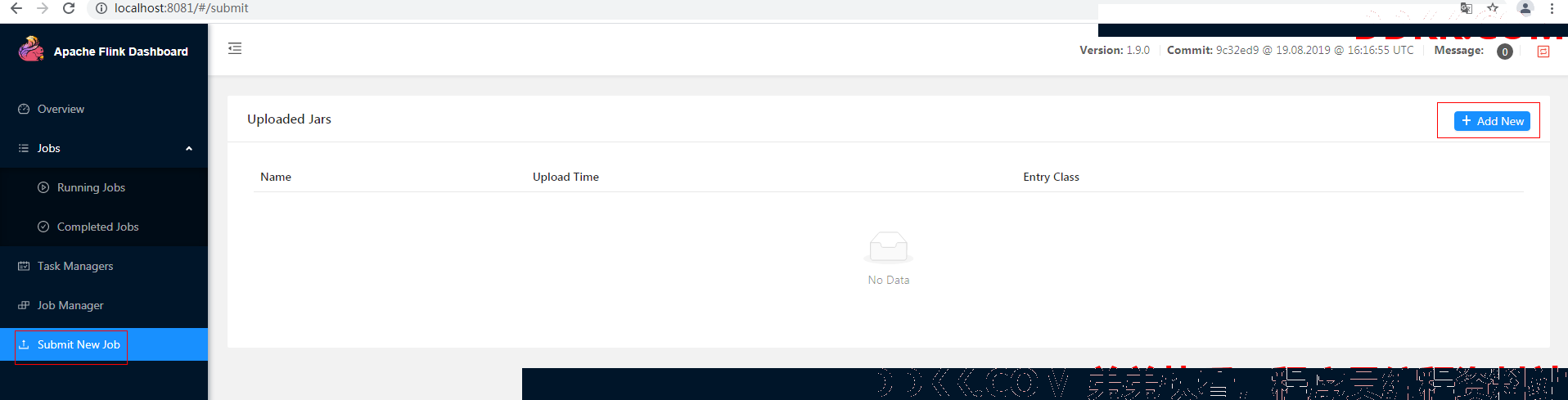
选中第二步打包生产的jar文件
如下提示上传成功
但是要注意的是,我们只是把jar文件是上传到服务器上,而并没有开始执行
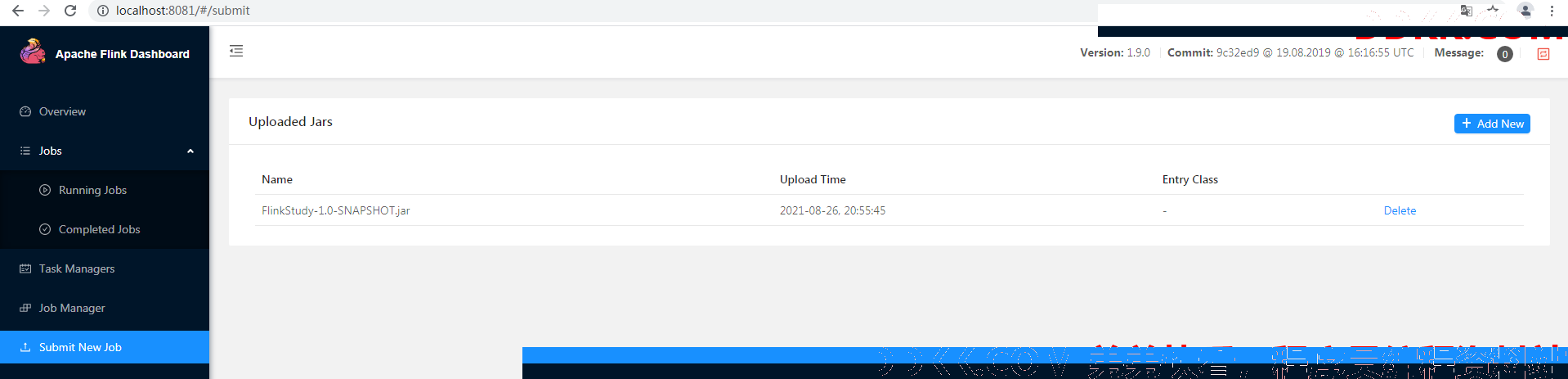
双击界面上的jar文件,可以看到有参数
Entry class 我们需要运行的class的完整路径
Parallelism 并行度
Program Arguments Java程序中的自定义变量
Savepoint Path Savepoint保存的路径
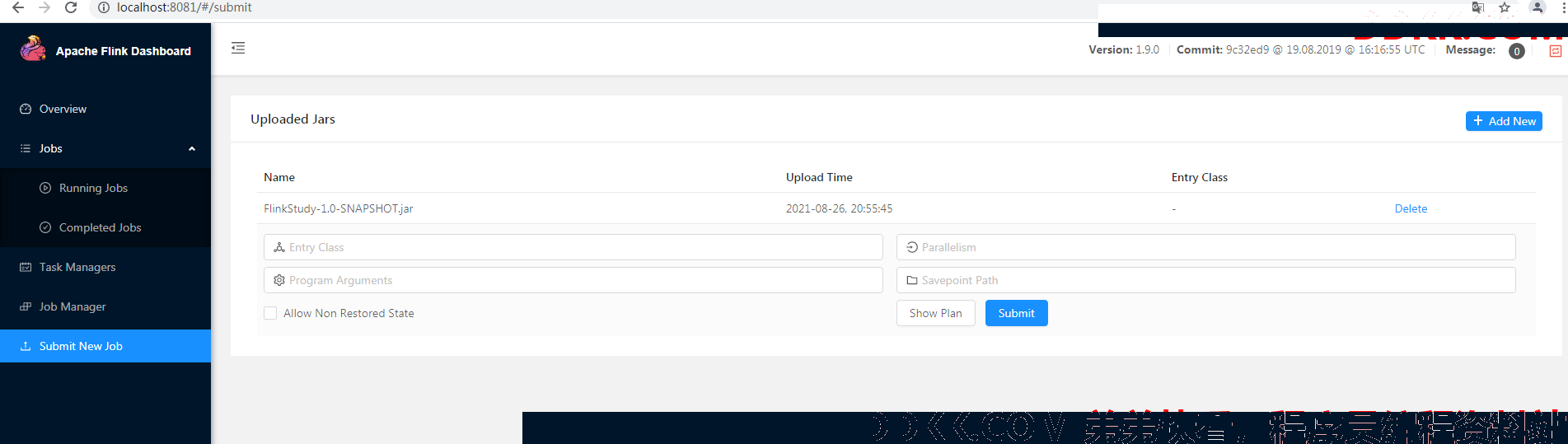
我们直接输入class名称,其余的默认,点击Submit
程序开始执行
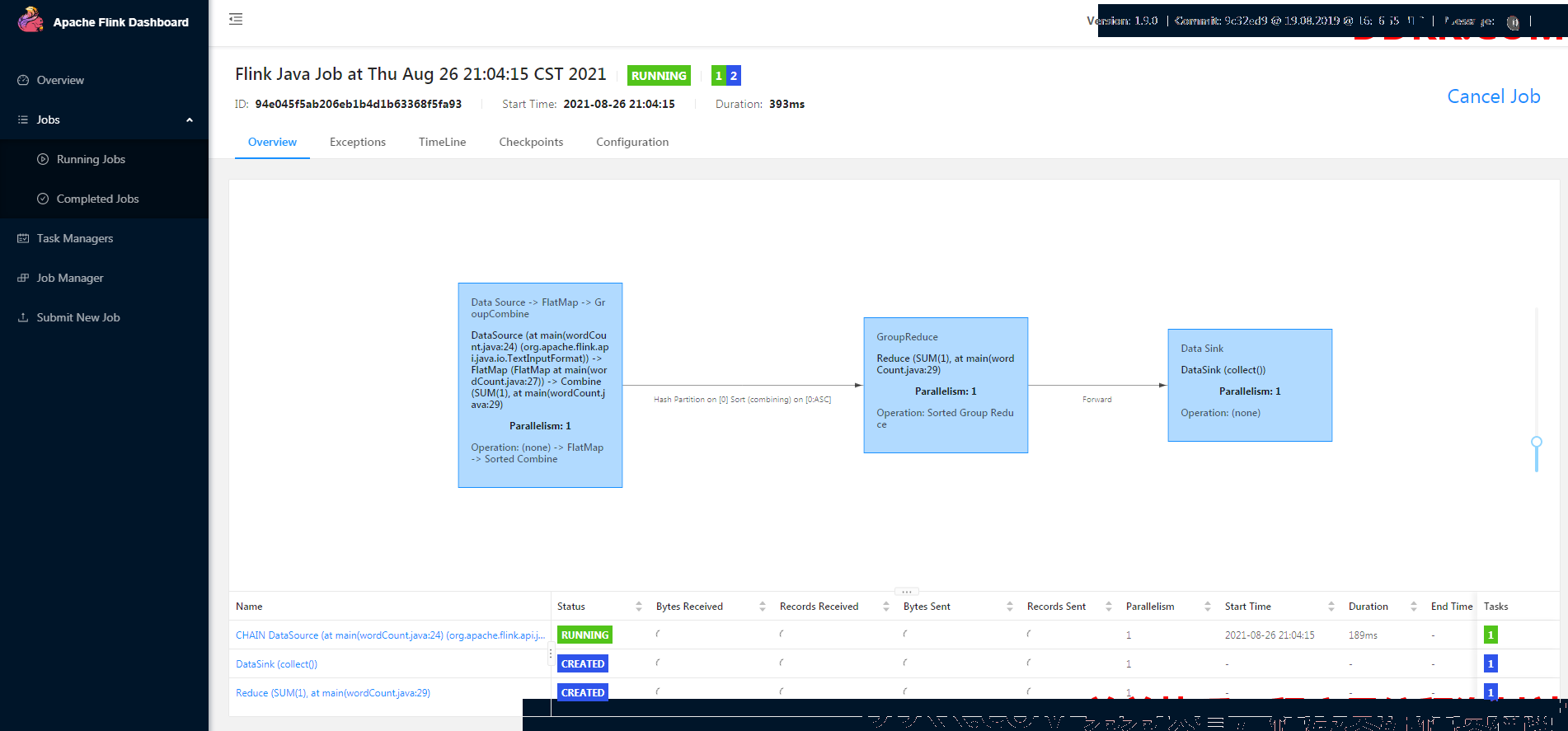
等待一会儿,执行成功