21、Flink 基础 - Sink之Kafka
备注: Flink 1.9.0
一、Sink概述
Flink没有类似于spark中foreach方法,让用户进行迭代的操作。虽有对外的输出操作都要利用Sink完成。最后通过类似如下方式完成整个任务最终输出操作。
官方提供了一部分的框架的sink。除此以外,需要用户自定义实现sink。
二、Sink之Kafka
2.1 将文本文件数据写入Kafka
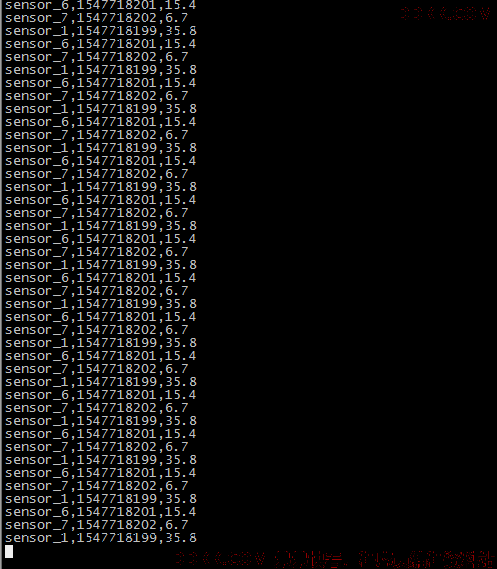
sensor.txt
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,36.3
sensor_1,1547718209,32.8
sensor_1,1547718212,37.1
代码:
package org.zqs.kafka;
import java.io.*;
import java.util.Properties;
import java.util.Random;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
public class Producer2 {
public static String topic = "sensor4";//定义主题
public static void main(String[] args) throws IOException {
Properties p = new Properties();
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.31.1.124:9092,10.31.1.125:9092,10.31.1.126:9092");//kafka地址,多个地址用逗号分割
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(p);
try {
//读取文件内容
String filename = "C:\\Users\\Administrator\\IdeaProjects\\SparkStudy\\src\\main\\resources\\sensor.txt";
FileInputStream file = new FileInputStream(filename);
//指定字符缓冲输入流
BufferedInputStream bis = new BufferedInputStream(file);
byte[] bys = new byte[1024];
int len;
while ((len = bis.read(bys)) != -1) {
//一次读取一个字节数组
String msg = new String(bys, 0, len);
System.out.println(msg);
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, msg);
kafkaProducer.send(record);
}
bis.close();
}
catch (Exception e) {
e.getStackTrace();
} finally {
kafkaProducer.close();
}
}
}
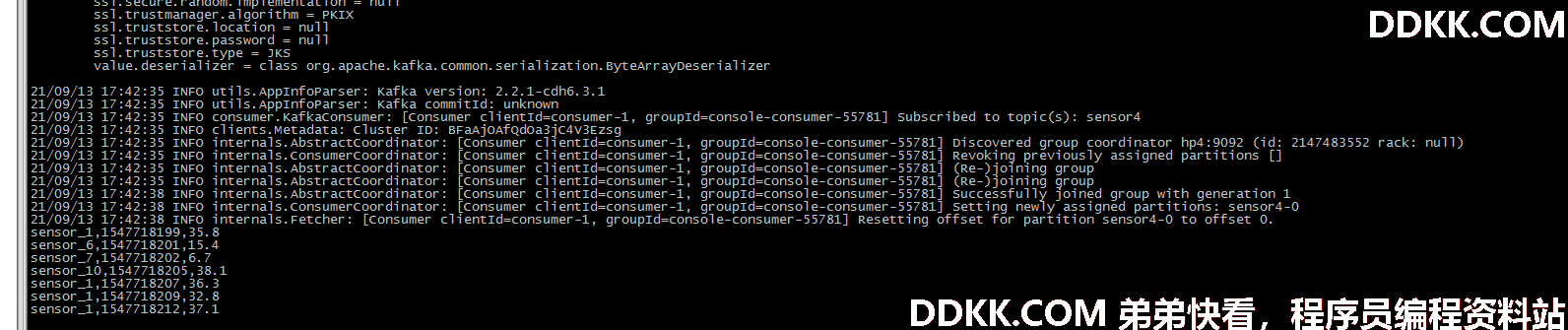
测试记录:
2.2 Java代码准备
代码:
package org.flink.sink;
import org.flink.beans.SensorReading;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
/** *
* @remark Kafka Sink
*/
public class SinkTest1_Kafka {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// // 从文件读取数据
// DataStream<String> inputStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkStudy\\src\\main\\resources\\sensor.txt");
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.31.1.124:9092,10.31.1.125:9092,10.31.1.126:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
// 从Kafka读取数据
DataStream<String> inputStream = env.addSource( new FlinkKafkaConsumer<String>("sensor4", new SimpleStringSchema(), properties));
// 转换成SensorReading类型
DataStream<String> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])).toString();
});
dataStream.addSink( new FlinkKafkaProducer<String>("10.31.1.124:9092,10.31.1.125:9092,10.31.1.126:9092", "sinktest", new SimpleStringSchema()));
env.execute();
}
}
直接运行代码,后面开启生产者,看输出。
2.3 开启生产者
因为真实环境非离线,来一条处理一条,所以这个地方我们开启一个Kafka的生产者,手工的录入一些数据
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/kafka/bin/kafka-console-producer.sh --broker-list 10.31.1.124:9092 --topic first
输入: 
2.4 查看Kafka输出
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/kafka/bin/kafka-console-consumer.sh --from-beginning --bootstrap-server 10.31.1.124:9092 --topic sensor4