26、Flink深入:Flink中的时间语议
1. Flink中时间语议概述
在Flink的流式处理中,会涉及到时间的不同概念,如下图所示:
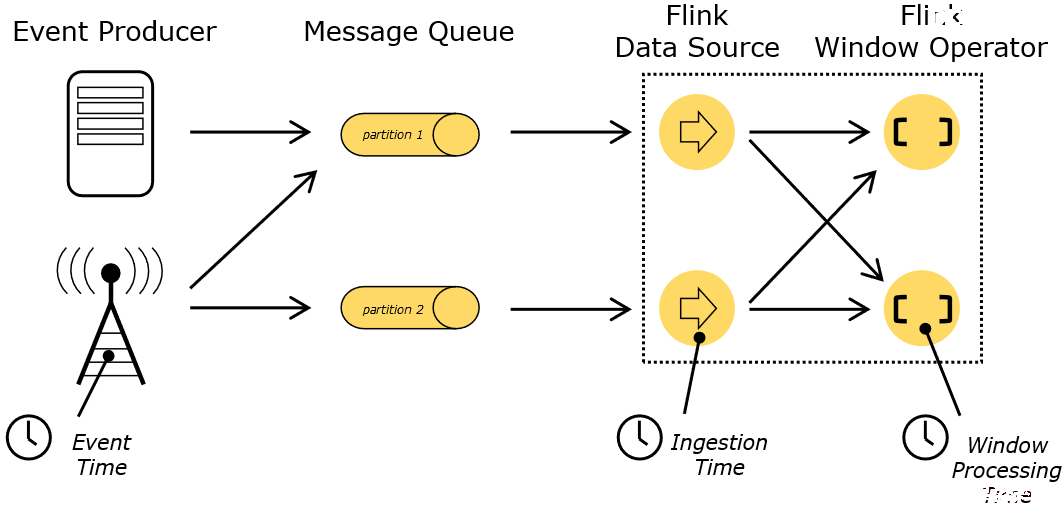
- Event Time :是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
- Ingestion Time :是数据进入Flink的时间。
- Processing Time :是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
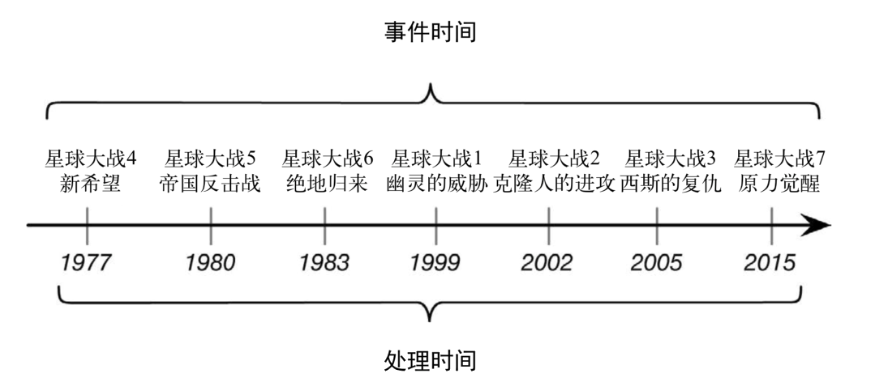
一个例子——电影《星球大战》:
例如,一条日志进入Flink的时间为2017-11-12 10:00:00.123,到达Window的系统时间为2017-11-12 10:00:01.234,日志的内容如下:
2017-11-02 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计1min内的故障日志个数,哪个时间是最有意义的?—— eventTime,因为我们要根据日志的生成时间进行统计。
2. EventTime的引入
在Flink的流式处理中,绝大部分的业务都会使用eventTime,一般只在eventTime无法使用时,才会被迫使用ProcessingTime或者IngestionTime。
如果要使用EventTime,那么需要引入EventTime的时间属性,引入方式如下所示:
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给env创建的每一个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
3. EventTime的重要性
3.1. 示例一
假设,你正在去往地下停车场的路上,并且打算用手机点一份外卖。
选好了外卖后,你就用在线支付功能付款了,这个时候是11点59分。
恰好这时,你走进了地下停车库,而这里并没有手机信号。
因此外卖的在线支付并没有立刻成功,而支付系统一直在Retry重试“支付”这个操作。
当你找到自己的车并且开出地下停车场的时候,已经是12点01分了。
这个时候手机重新有了信号,手机上的支付数据成功发到了外卖在线支付系统,支付完成。
在上面这个场景中你可以看到,
支付数据的事件时间是11点59分,而支付数据的处理时间是12点01分
-------
问题:
如果要统计12之前的订单金额,那么这笔交易是否应被统计?
答案:
应该被统计,因为该数据的真真正正的产生时间为11点59分,即该数据的事件时间为11点59分,
事件时间能够真正反映/代表事件的本质! 所以一般在实际开发中会以事件时间作为计算标准
3.2. 示例二
一条错误日志的内容为:
2020-11:11 22:59:00 error NullPointExcep --事件时间
进入Flink的时间为2020-11:11 23:00:00 --摄入时间
到达Window的时间为2020-11:11 23:00:10 --处理时间
-------
问题:
对于业务来说,要统计1h内的故障日志个数,哪个时间是最有意义的?
答案:
EventTime事件时间,因为bug真真正正产生的时间就是事件时间,只有事件时间才能真正反映/代表事件的本质!
3.3. 示例三
某 App 会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。
A用户在 11:01:00 对 App 进行操作,B用户在 11:02:00 操作了 App。
但是A用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到B用户的消息,然后再接受到A用户的消息,消息乱序了。
-------
问题:
如果这个是一个根据用户操作先后顺序,进行抢购的业务,那么是A用户成功还是B用户成功?
答案:
应该算A成功,因为A确实比B操作的早,但是实际中考虑到实现难度,可能直接按B成功算;
也就是说,实际开发中希望基于事件时间来处理数据,但因为数据可能因为网络延迟等原因,出现了乱序;
按照事件时间处理起来有难度!
3.4. 示例四
在实际环境中,经常会出现,因为网络原因,数据有可能会延迟一会才到达Flink实时处理系统。
我们先来设想一下下面这个场景:
原本应该被该窗口计算的数据因为网络延迟等原因晚到了,就有可能丢失了。
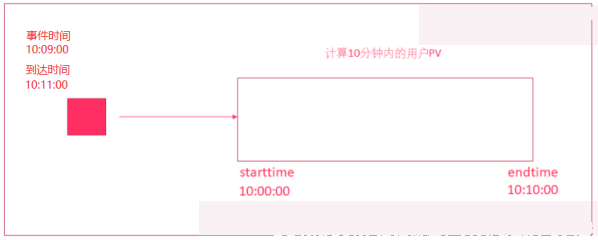
4. Flink中时间语议总结
实际开发中我们希望基于事件时间来处理数据,但因为数据可能因为网络延迟等原因,出现了乱序或延迟到达,那么可能处理的结果不是我们想要的甚至出现数据丢失的情况,所以在flink中存在一种机制(watermark水印机制)来解决一定程度上的数据乱序或延迟到底的问题!