06、Flink深入:Flink安装部署之Flink On Yarn模式
1. 原理
1.1. 为什么使用Flink On Yarn
在实际开发中,使用Flink时,更多的使用方式是Flink On Yarn模式,原因如下:
- Yarn的资源可以按需使用,提高集群的资源利用率
- Yarn的任务有优先级,根据优先级运行作业
- 基于Yarn调度系统,能够自动化地处理各个角色的 Failover(容错)
- JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控
- 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器
- 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager
1.2. Flink如何和Yarn进行交互

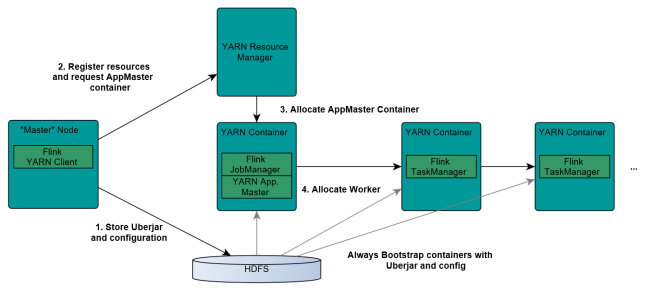
- Client上传jar包和配置文件到HDFS集群上
- Client向Yarn ResourceManager提交任务并申请资源
- ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager,JobManager和ApplicationMaster运行在同一个container上。一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。这个配置文件也被上传到HDFS上。此外,AppMaster容器也提供了Flink的web服务接口。YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink
- ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
1.3. 两种方式
Session模式 :
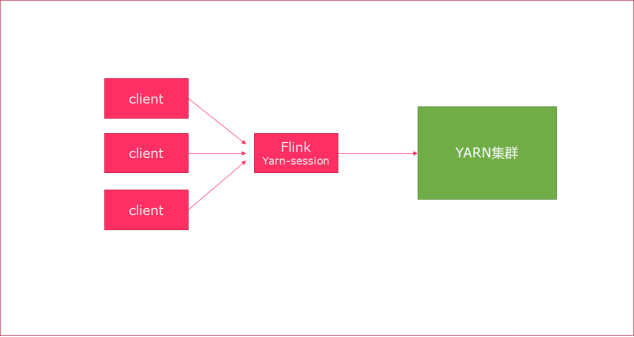
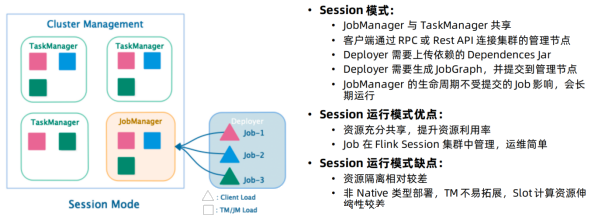
特点:需要事先申请资源,启动JobManager和TaskManger
优点:不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源
应用场景:适合作业递交比较频繁的场景,小作业比较多的场景
Per-Job模式 :
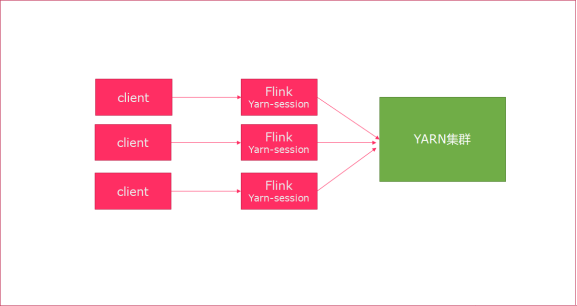
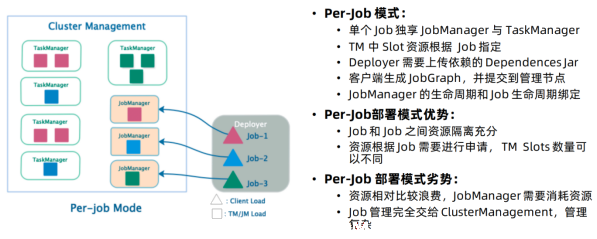
特点:每次递交作业都需要申请一次资源
优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源
缺点:每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间
应用场景:适合作业比较少的场景、大作业的场景
2. 操作
2.1. 关闭yarn的内存检查
在yarn-site.xml文件中添加如下内容
vim/export/server/hadoop/etc/hadoop/yarn-site.xml
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
说明:
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
在这里面我们需要关闭,因为对于flink使用yarn模式下,很容易内存超标,这个时候yarn会自动杀掉job。
2.2. 同步
scp -r /export/server/hadoop/etc/hadoop/yarn-site.xml node2:/export/server/hadoop/etc/hadoop/yarn-site.xml
scp -r /export/server/hadoop/etc/hadoop/yarn-site.xml node3:/export/server/hadoop/etc/hadoop/yarn-site.xml
2.3. 重启yarn
/export/server/hadoop/sbin/stop-yarn.sh
/export/server/hadoop/sbin/start-yarn.sh
3. 测试
3.1. Session模式
yarn-session.sh(开辟资源) + flink run(提交任务)
步骤一:在yarn上启动一个Flink会话,node1上执行以下命令
/export/server/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
说明:
申请2个CPU、1600M内存
# -n 表示申请2个容器,这里指的就是多少个taskmanager
# -tm 表示每个TaskManager的内存大小
# -s 表示每个TaskManager的slots数量
# -d 表示以后台程序方式运行
注意:
该警告不用管
WARN org.apache.hadoop.hdfs.DFSClient - Caught exception java.lang.InterruptedException
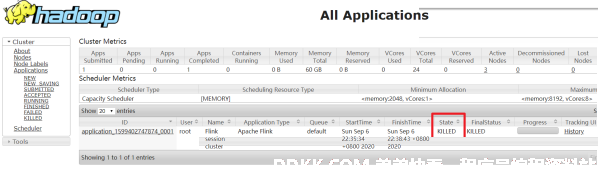
步骤二:查看UI界面
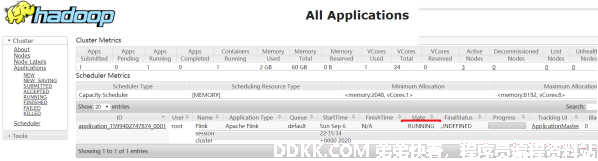
步骤三:使用flink run提交任务
/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar
运行完之后可以继续运行其他的小任务
run/export/server/flink/examples/batch/WordCount.jar
步骤四:通过上方的ApplicationMaster可以进入Flink的管理界面
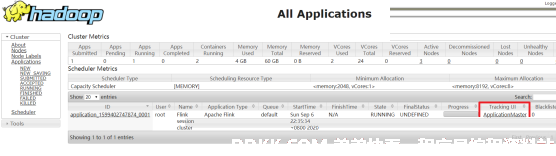
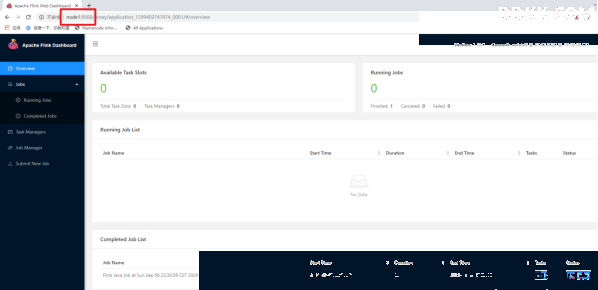
步骤五:关闭yarn-session
yarn application -kill application_1599402747874_0001
rm-rf /tmp/.yarn-properties-root
3.2. Per-Job分离模式
步骤一:直接提交job
/export/server/flink/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 /export/server/flink/examples/batch/WordCount.jar
# -m jobmanager的地址
# -yjm 1024 指定jobmanager的内存信息
# -ytm 1024 指定taskmanager的内存信息
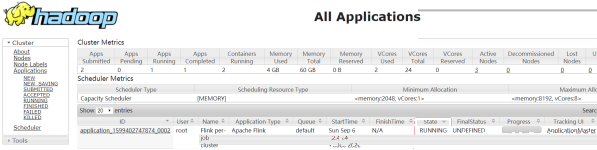
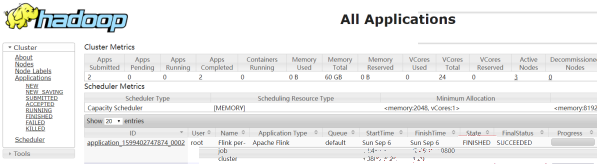
步骤二:查看UI界面
注意点 :
在之前版本中如果使用的是flink on yarn方式,想切换回standalone模式的话,如果报错需要删除:【/tmp/.yarn-properties-root】
rm-rf /tmp/.yarn-properties-root
因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager