11、Flink深入:Flink之流批一体架构
1. 流处理和批处理
Flink官网:Apache Flink 1.12 Documentation: Learn Flink: Hands-on Training

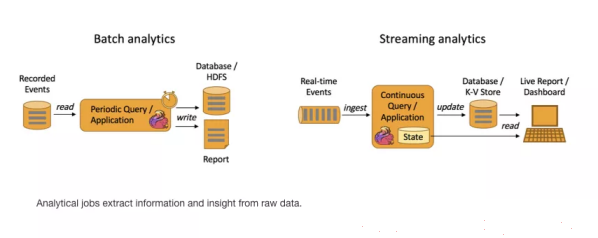

- Batch Analytics,右边是 Streaming Analytics。批量计算: 统一收集数据->存储到DB->对数据进行批量处理,就是传统意义上使用类似于 Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表
- Streaming Analytics 流式计算,顾名思义,就是对数据流进行处理,如使用流式分析引擎如 Storm,Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表。
2. 流批一体API
2.1. DataStream API 支持批执行模式
Part 1 : Flink 的核心 API 最初是针对特定的场景设计的,尽管 Table API / SQL 针对流处理和批处理已经实现了统一的 API,但当用户使用较底层的 API 时,仍然需要在批处理(DataSet API)和流处理(DataStream API)这两种不同的 API 之间进行选择。
Part 2 :鉴于批处理是流处理的一种特例,将这两种 API 合并成统一的 API,有一些非常明显的好处,比如:
- 可复用性:作业可以在流和批这两种执行模式之间自由地切换,而无需重写任何代码。因此,用户可以复用同一个作业,来处理实时数据和历史数据。
- 维护简单:统一的 API 意味着流和批可以共用同一组 connector,维护同一套代码,并能够轻松地实现流批混合执行,例如 backfilling 之类的场景。
Part 3 :考虑到这些优点,社区已朝着流批统一的 DataStream API 迈出了第一步:支持高效的批处理(FLIP-134)。从长远来看,这意味着 DataSet API 将被弃用(FLIP-131),其功能将被包含在 DataStream API 和 Table API / SQL 中。
2.2. API
Flink提供了多个层次的API供开发者使用,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大
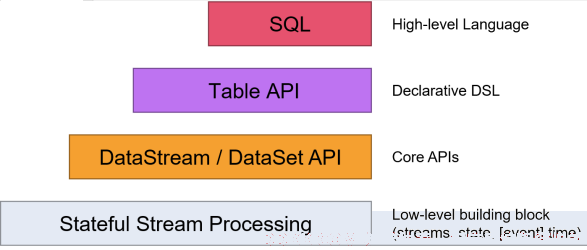
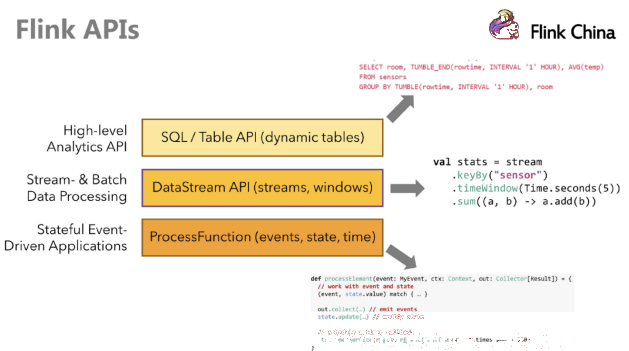
注意:在Flink1.12时支持流批一体,DataSetAPI已经不推荐使用了,之后可以使用DataStream处理批数据
Apache Flink 1.12 Documentation: Flink DataSet API Programming Guide
[官宣| Apache Flink 1.12.0 正式发布,流批一体真正统一运行!-阿里云开发者社区][_ Apache Flink 1.12.0 _-]

Apache Flink 1.12 Documentation: Flink DataStream API Programming Guide
2.3. 编程模型
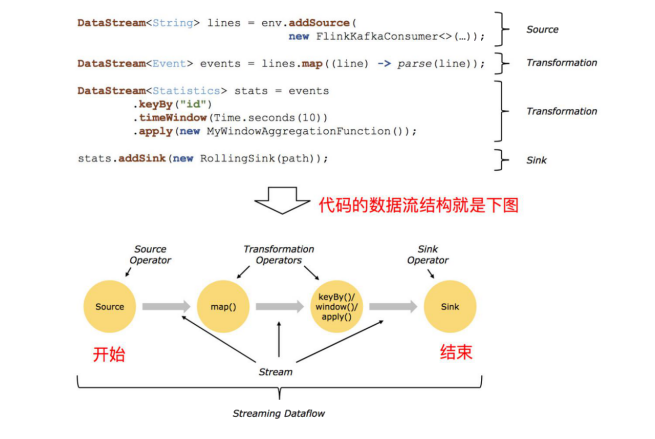
Flink 应用程序结构主要包含三部分,Source/Transformation/Sink,如下图所示: