19、JVM 调优实战 - JVM中 Class 文件结构及字节码指令的深入理解
今天分析Class 文件结构及深入字节码指令:
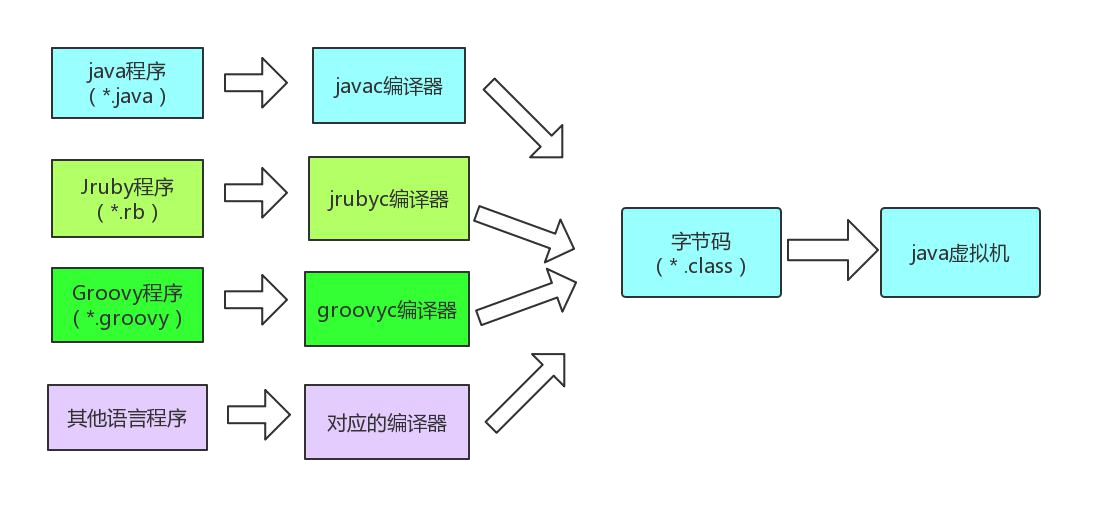
JVM 的无关性
与平台无关性是建立在操作系统上,虚拟机厂商提供了许多可以运行在各种不同平台的虚拟机,它们都可以载入和执行字节码,从而实现程序的“一次 编写,到处运行”
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
各种不同平台的虚拟机与所有平台都统一使用的程序存储格式——字节码( ByteCode )是构成平台无关性的基石,也是语言无关性的基础。 Java 虚拟机不 和包括 Java 在内的任何语言绑定,它只与“ Class 文件”这种特定的二进制文件格式所关联, Class 文件中包含了 Java 虚拟机指令集和符号表以及若干其他 辅助信息
Class 类文件(了解即可)
Java 技术能够一直保持非常好的向后兼容性,这点 Class 文件结构的稳定性功不可没。 Java 已经发展到 14 版本,但是 class 文件结构的内容,绝大部分在 JDK1.2 时代就已经定义好了。虽然 JDK1.2 的内容比较古老,但是 java 发展经历了十余个大版本,但是每次基本上知识在原有结构基础上新增内容、扩充 功能,并未对定义的内容做修改。 任何一个 Class 文件都对应着唯一一个类或接口的定义信息,但反过来说, Class 文件实际上它并不一定以磁盘文件的形式存在(比如可以动态生成、或者 直接送入类加载器中)。 Class 文件是一组以 8 位字节为基础单位的二进制流。 Class 文件结构这些内容在面试的时候很少有人问,因此大家学这个东西要当成一个兴趣去学,这个是自身内力提升的过程。
工具介绍
Sublime
查看16 进制的编辑器
javap
javap 是 JDK 自带的反解析工具。它的作用是将 .class 字节码文件解析成可读的文件格式。
在使用 javap 时我一般会添加 -v 参数,尽量多打印一些信息。同时,我也会使用 -p 参数,打印一些私有的字段和方法。
jclasslib
如果你不太习惯使用命令行的操作,还可以使用 jclasslib , jclasslib 是一个图形化的工具,能够更加直观的查看字节码中的内容。它还分门别类的对类中 的各个部分进行了整理,非常的人性化。同时,它还提供了 Idea 的插件,你可以从 plugins 中搜索到它。
jclasslib 的下载地址: https://github.com/ingokegel/jclasslib
Class 文件格式
从一个 Class 文件开始,下图是一个 java 文件。
我们使用 Sublime 这个工具打开 class

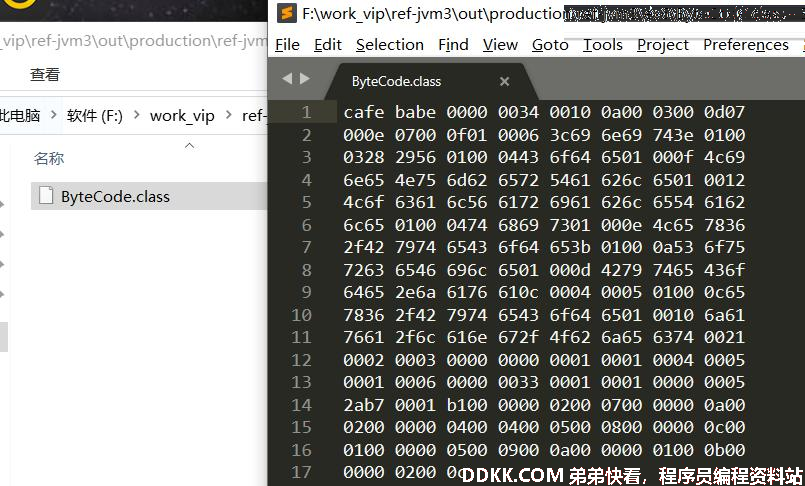
整个class 文件的格式就是一个二进制的字节流。 那么这个二进制的字节流就看谁来解释了,我做了一个 Xmind 文件。 各个数据项目严格按照顺序紧凑地排列在 Class 文件之中,中间没有添加任何分隔符,这使得整个 Class 文件中存储的内容几乎全部是程序运行的必要数 据,没有空隙存在。 Class 文件格式采用一种类似于 C 语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:无符号数和表。 无符号数属于基本的数据类型,以 u1 、 u2 、 u4 、 u8 来分别代表 1 个字节(一个字节是由两位 16 进制数组成)、 2 个字节、 4 个字节和 8 个字节的无符号 数,无符号数可以用来描述数字、索引引用、数量值或者按照 UTF-8 编码构成字符串值。 表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以“_info ”结尾。表用于描述有层次关系的复合结构的数据,整个 Class 文件本质上就是一张表。
Class 文件格式详解
Class 的结构不像 XML 等描述语言,由于它没有任何分隔符号,所以在其中的数据项,无论是顺序还是数量,都是被严格限定的,哪个字节代表什么含义, 长度是多少,先后顺序如何,都不允许改变。
按顺序包括:
魔数与 Class 文件的版本
每个Class 文件的头 4 个字节称为魔数( Magic Number ),它的唯一作用是确定这个文件是否为一个能被虚拟机接受的 Class 文件。使用魔数而不是扩展 名来进行识别主要是基于安全方面的考虑,因为文件扩展名可以随意地改动。文件格式的制定者可以自由地选择魔数值,只要这个魔数值还没有被广泛 采用过同时又不会引起混淆即可。( ) 紧接着魔数的 4 个字节存储的是 Class 文件的版本号:第 5 和第 6 个字节是次版本号( MinorVersion ),第 7 和第 8 个字节是主版本号( Major Version )。
Java 的版本号是从 45 开始的, JDK 1.1 之后的每个 JDK 大版本发布主版本号向上加 1 高版本的 JDK 能向下兼容以前版本的 Class 文件,但不能运行以后版 本的 Class 文件,即使文件格式并未发生任何变化,虚拟机也必须拒绝执行超过其版本号的 Class 文件。 代表 JDK1.8 ( 16 进制的 34 ,换成 10 进制就是 52 )
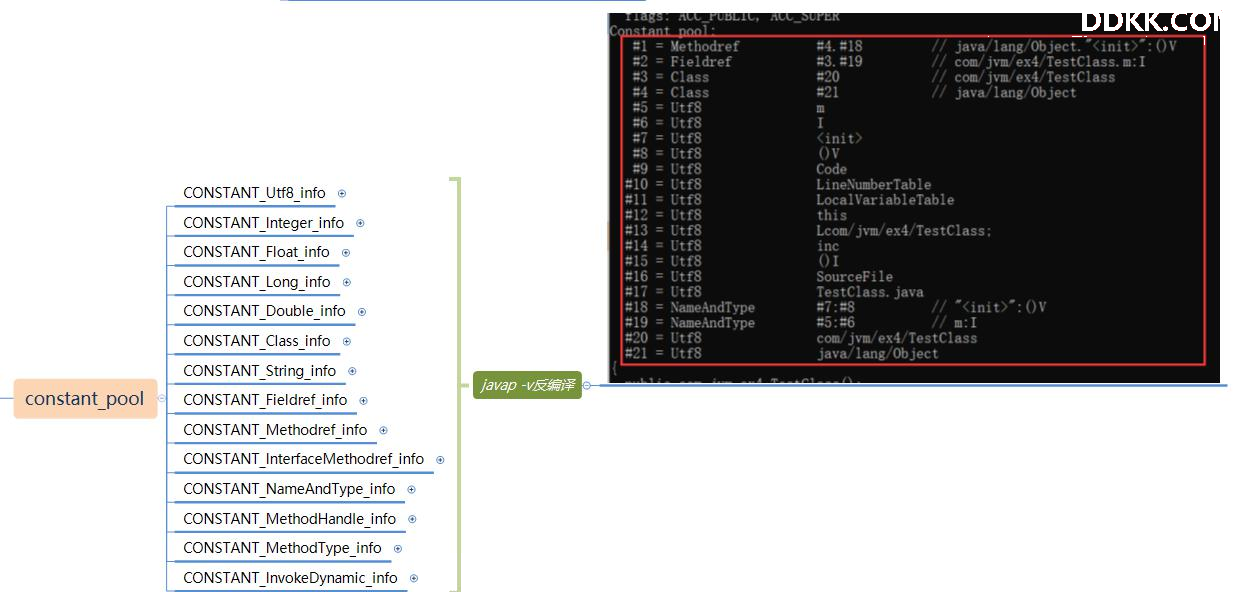
常量池
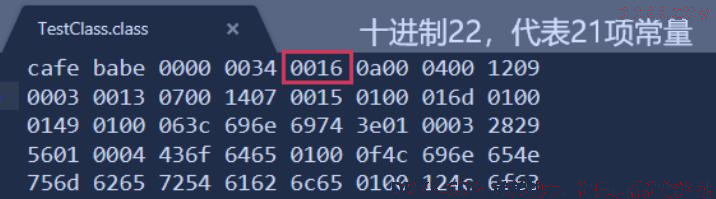
常量池中常量的数量是不固定的,所以在常量池的入口需要放置一项 u2 类型的数据,代表常量池容量计数值( constant_pool_count )。
与Java 中语言习惯不一样的是,这个容量计数是从 1 而不是 0 开始的
常量池中主要存放两大类常量:字面量( Literal )和符号引用( Symbolic References )。
字面量比较接近于 Java 语言层面的常量概念,如文本字符串、声明为 final 的常量值等。
而符号引用则属于编译原理方面的概念,包括了下面三类常量:
类和接口的全限定名( Fully Qualified Name )、字段的名称和描述符( Descriptor )、方法的名称和描述符
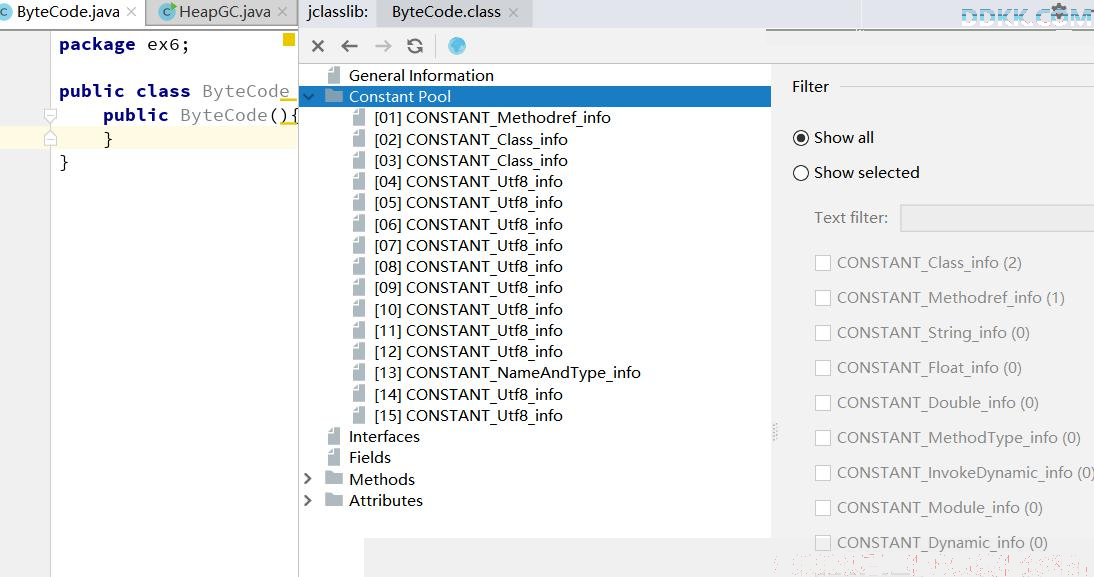
我们就可以使用更加直观的工具 jclasslib ,来查看字节码中的具体内容了
访问标志
用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口;是否定义为 public 类型;是否定义为 abstract 类型;如果是类的话,是否被 声明为 final 等
类索引、父类索引与接口索引集合
这三项数据来确定这个类的继承关系。类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名。由于 Java 语言不允许多重继承, 所以父类索引只有一个,除了 java.lang.Object 之外,所有的 Java 类都有父类,因此除了 java.lang.Object 外,所有 Java 类的父类索引都不为 0 。接口索引 集合就用来描述这个类实现了哪些接口,这些被实现的接口将按 implements 语句(如果这个类本身是一个接口,则应当是 extends 语句)后的接口顺序 从左到右排列在接口索引集合中
字段表集合
描述接口或者类中声明的变量。字段( field )包括类级变量以及实例级变量。 而字段叫什么名字、字段被定义为什么数据类型,这些都是无法固定的,只能引用常量池中的常量来描述。 字段表集合中不会列出从超类或者父接口中继承而来的字段,但有可能列出原本 Java 代码之中不存在的字段,譬如在内部类中为了保持对外部类的访问 性,会自动添加指向外部类实例的字段。
方法表集合
描述了方法的定义,但是方法里的 Java 代码,经过编译器编译成字节码指令后,存放在属性表集合中的方法属性表集合中一个名为“ Code ”的属性里面。 与字段表集合相类似的,如果父类方法在子类中没有被重写(Override ),方法表集合中就不会出现来自父类的方法信息。但同样的,有可能会出现由编译器自动添加的方法,最典型的便是类构造器“<clinit>”方法和实例构造器“< init >”
属性表集合
存储Class 文件、字段表、方法表都自己的属性表集合,以用于描述某些场景专有的信息。如方法的代码就存储在 Code 属性表中。
字节码指令
字节码指令属于方法表中的内容:

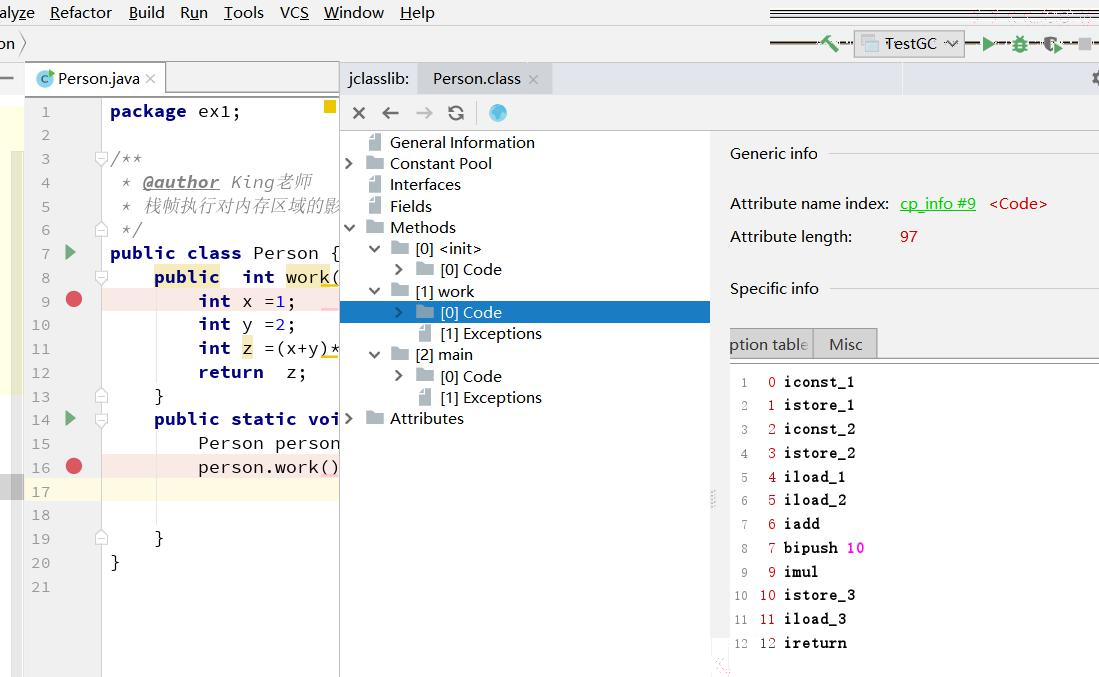
Java 虚拟机的指令由一个字节长度的、代表着某种特定操作含义的数字(称为操作码, Opcode )以及跟随其后的零至多个代表此操作所需参数(称为操 作数,Operands )而构成。 由于限制了 Java 虚拟机操作码的长度为一个字节(即 0 ~ 255 ),这意味着指令集的操作码总数不可能超过 256 条。 大多数的指令都包含了其操作所对应的数据类型信息。例如: iload 指令用于从局部变量表中加载 int 型的数据到操作数栈中,而 fload 指令加载的则是 float 类型的数据。 大部分的指令都没有支持整数类型 byte 、 char 和 short ,甚至没有任何指令支持 boolean 类型。大多数对于 boolean 、 byte 、 short 和 char 类型数据的操作, 实际上都是使用相应的 int 类型作为运算类型
阅读字节码作为了解 Java 虚拟机的基础技能,有需要的话可以去掌握常见指令。
字节码助记码解释地址: https://cloud.tencent.com/developer/article/1333540
加载和存储指令
用于将数据在栈帧中的局部变量表和操作数栈之间来回传输,这类指令包括如下内容。
将一个局部变量加载到操作栈: iload 、 iload_ < n >、 lload 、 lload_ < n >、 fload 、 fload_ < n >、 dload 、 dload_ < n >、 aload 、 aload_ < n >。 将一个数值从操作数栈存储到局部变量表:istore 、 istore_ < n >、 lstore 、 lstore_ < n >、 fstore 、 fstore_ < n >、 dstore 、 dstore_ < n >、 astore 、 astore_ < n >。将一个常量加载到操作数栈:bipush 、 sipush 、 ldc 、 ldc_w 、 ldc2_w 、 aconst_null 、 iconst_m1 、 iconst_ < i >、 lconst_ < l >、 fconst_ < f >、 dconst_ < d >。
扩充局部变量表的访问索引的指令: wide 。
运算或算术指令
用于对两个操作数栈上的值进行某种特定运算,并把结果重新存入到操作栈顶。
加法指令: iadd 、 ladd 、 fadd 、 dadd 。
减法指令: isub 、 lsub 、 fsub 、 dsub 。
乘法指令: imul 、 lmul 、 fmul 、 dmul 等等
类型转换指令
可以将两种不同的数值类型进行相互转换,
Java 虚拟机直接支持以下数值类型的宽化类型转换(即小范围类型向大范围类型的安全转换): int 类型到 long 、 float 或者 double 类型。
long 类型到 float 、 double 类型。
float 类型到 double 类型。
处理窄化类型转换( Narrowing Numeric Conversions )时,必须显式地使用转换指令来完成,这些转换指令包括: i2b 、 i2c 、 i2s 、 l2i 、 f2i 、 f2l 、 d2i 、 d2l 和
d2f。
创建类实例的指令
new。
创建数组的指令
newarray 、 anewarray 、 multianewarray 。
访问字段指令
getfield 、 putfield 、 getstatic 、 putstatic 。
数组存取相关指令
把一个数组元素加载到操作数栈的指令: baload 、 caload 、 saload 、 iaload 、 laload 、 faload 、 daload 、 aaload 。
将一个操作数栈的值存储到数组元素中的指令: bastore 、 castore 、 sastore 、 iastore 、 fastore 、 dastore 、 aastore 。
取数组长度的指令: arraylength 。 检查类实例类型的指令
instanceof 、 checkcast 。
操作数栈管理指令
如同操作一个普通数据结构中的堆栈那样, Java 虚拟机提供了一些用于直接操作操作数栈的指令,包括:将操作数栈的栈顶一个或两个元素出栈: pop 、 pop2。 复制栈顶一个或两个数值并将复制值或双份的复制值重新压入栈顶:dup 、 dup2 、 dup_x1 、 dup2_x1 、 dup_x2 、 dup2_x2 。 将栈最顶端的两个数值互换:swap 。
控制转移指令
控制转移指令可以让 Java 虚拟机有条件或无条件地从指定的位置指令而不是控制转移指令的下一条指令继续执行程序,从概念模型上理解,可以认为控 制转移指令就是在有条件或无条件地修改 PC 寄存器的值。控制转移指令如下。
条件分支: ifeq 、 iflt 、 ifle 、 ifne 、 ifgt 、 ifge 、 ifnull 、 ifnonnull 、 if_icmpeq 、 if_icmpne 、 if_icmplt 、 if_icmpgt 、 if_icmple 、 if_icmpge 、 if_acmpeq 和 if_acmpne 。
复合条件分支: tableswitch 、 lookupswitch 。
无条件分支: goto 、 goto_w 、 jsr 、 jsr_w 、 ret 。
方法调用指令
invokevirtual 指令用于调用对象的实例方法,根据对象的实际类型进行分派(虚方法分派),这也是 Java 语言中最常见的方法分派方式。
invokeinterface 指令用于调用接口方法,它会在运行时搜索一个实现了这个接口方法的对象,找出适合的方法进行调用。
invokespecial 指令用于调用一些需要特殊处理的实例方法,包括实例初始化方法、私有方法和父类方法。
invokestatic 指令用于调用类方法( static 方法)。
invokedynamic 指令用于在运行时动态解析出调用点限定符所引用的方法,并执行该方法,前面 4 条调用指令的分派逻辑都固化在 Java 虚拟机内部,而
invokedynamic 指令的分派逻辑是由用户所设定的引导方法决定的。
方法调用指令与数据类型无关。
方法返回指令
是根据返回值的类型区分的,包括 ireturn (当返回值是 boolean 、 byte 、 char 、 short 和 int 类型时使用)、 lreturn 、 freturn 、 dreturn 和 areturn ,另外还有 一条 return 指令供声明为 void 的方法、实例初始化方法以及类和接口的类初始化方法使用。
异常处理指令
在Java 程序中显式抛出异常的操作( throw 语句)都由 athrow 指令来实现
同步指令
有monitorenter 和 monitorexit 两条指令来支持 synchronized 关键字的语义
字节码指令 —— 异常处理
每个时刻正在执行的当前方法就是虚拟机栈顶的栈桢。方法的执行就对应着栈帧在虚拟机栈中入栈和出栈的过程。 当一个方法执行完,要返回,那么有两种情况,一种是正常,另外一种是异常。 完成出口(返回地址) : 正常返回:(调用程序计数器中的地址作为返回)
三步曲:
恢复上层方法的局部变量表和操作数栈、
把返回值(如果有的话)压入调用者栈帧的操作数栈中、
调整程序计数器的值以指向方法调用指令后面的一条指令、
异常的话:(通过异常处理表 < 非栈帧中的 > 来确定)
异常机制
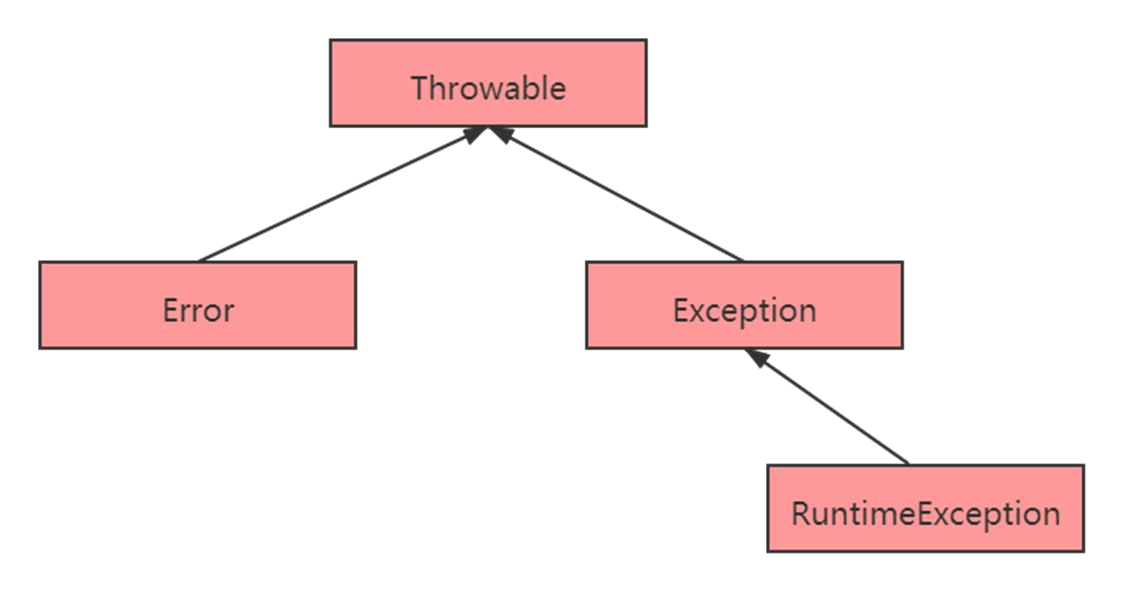
如果你熟悉 Java 语言,那么对上面的异常继承体系一定不会陌生,其中, Error 和 RuntimeException 是非检查型异常( Unchecked Exception ),也就是 不需要 catch 语句去捕获的异常;而其他异常,则需要程序员手动去处理。
异常表
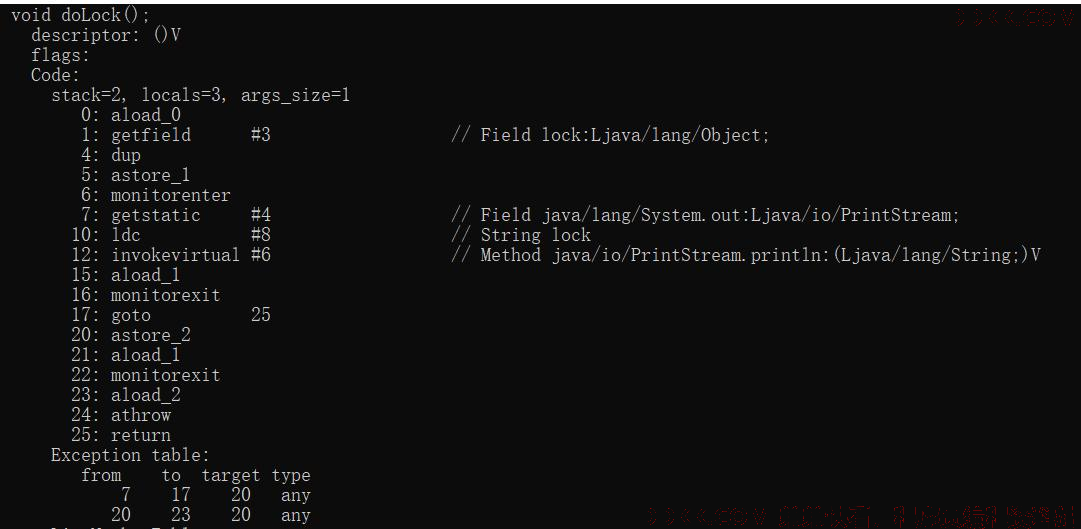
在synchronized 生成的字节码中,其实包含两条 monitorexit 指令,是为了保证所有的异常条件,都能够退出。
可以看到,编译后的字节码,带有一个叫 Exception table 的异常表,里面的每一行数据,都是一个异常处理器:
from 指定字节码索引的开始位置
to 指定字节码索引的结束位置
target 异常处理的起始位置 type 异常类型
也就是说,只要在 from 和 to 之间发生了异常,就会跳转到 target 所指定的位置。 我可以看到,第一条 monitorexit ( 16 )在异常表第一条的范围中,如果异常,能够跳转到第 20 行 第二条 monitorexit ( 22 )在异常表第二条的范围中,如果异常,能够跳转到第 20 行
Finally
通常我们在做一些文件读取的时候,都会在 finally 代码块中关闭流,以避免内存的溢出。关于这个场景,我们再分析一下下面这段代码的异常表。
上面的代码,捕获了一个 FileNotFoundException 异常,然后在 finally 中捕获了 IOException 异常。当我们分析字节码的时候,却发现了一个有意思的地 方:IOException 足足出现了三次。
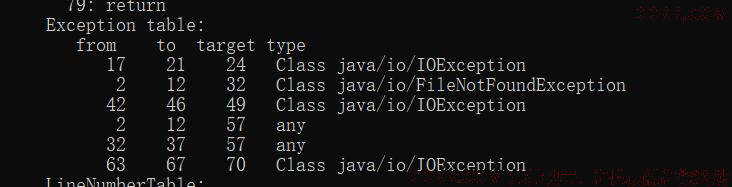
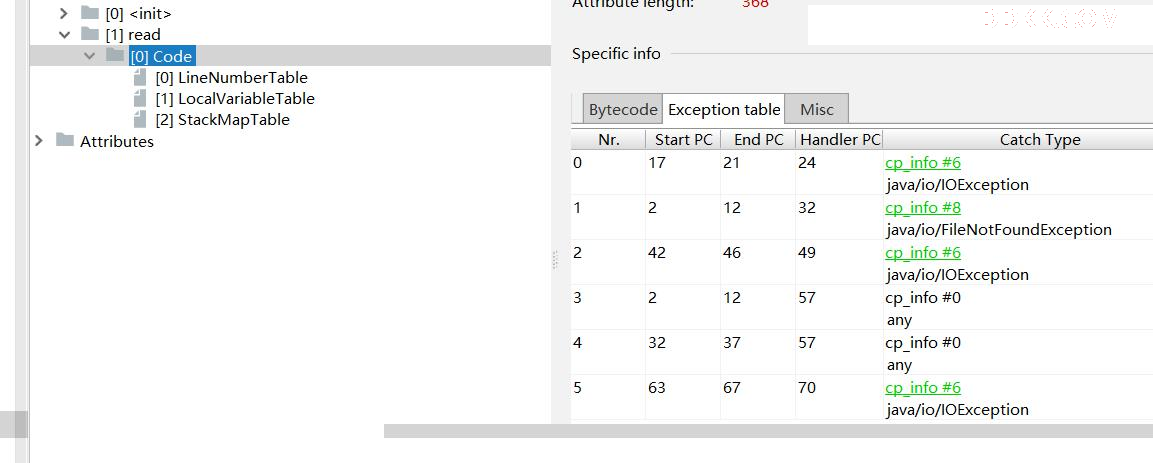
Java 编译器使用了一种比较傻的方式来组织 finally 的字节码,它分别在 try 、 catch 的正常执行路径上,复制一份 finally 代码,追加在正常执行逻辑的 后面;同时,再复制一份到其他异常执行逻辑的出口处。
再看一个例子
这段代码不报错的原因,都可以在字节码中找到答案
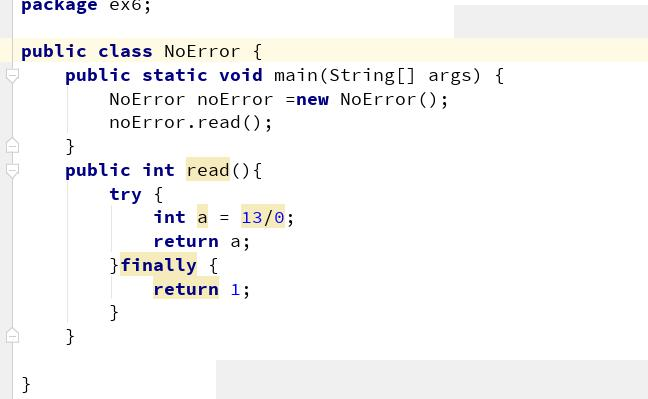
程序的字节码,可以看到,异常之后,直接跳转到序号 9 了。

字节码指令 —— 装箱拆箱
装箱拆箱
Java 中有 8 种基本类型,但鉴于 Java 面向对象的特点,它们同样有着对应的 8 个包装类型,比如 int 和 Integer ,包装类型的值可以为 null (基本类 型没有 null 值,而数据库的表中普遍存在 null 值。 所以实体类中所有属性均应采用封装类型),很多时候,它们都能够相互赋值。

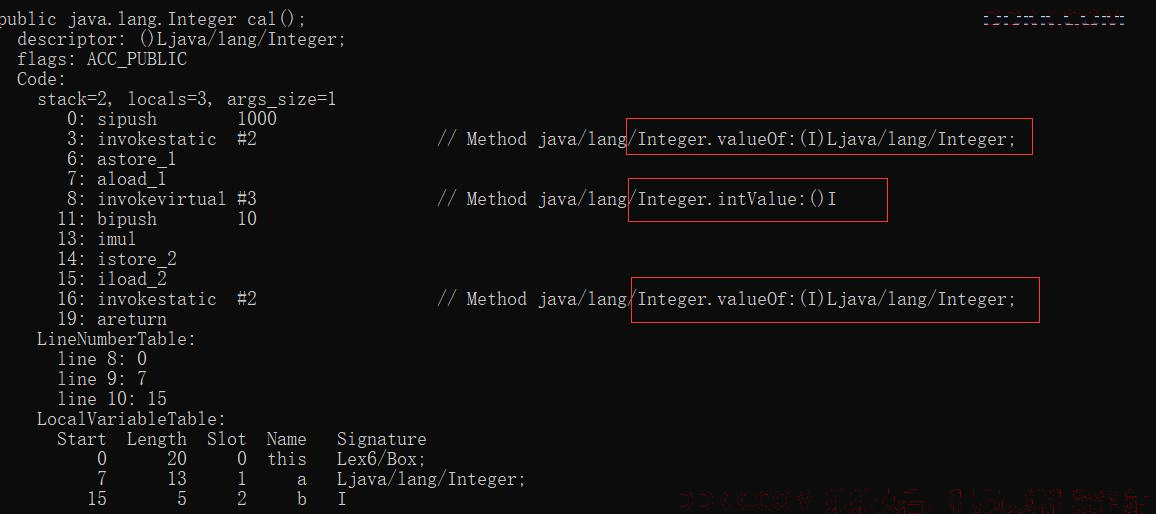
通过观察字节码,我们发现:
1、 在进行乘法运算的时候,调用了Integer.intValue方法来获取基本类型的值;
2、 赋值操作使用的是Integer.valueOf方法;
3、 在方法返回的时候,再次使用了Integer.valueOf方法对结果进行了包装;
这就是 Java 中的自动装箱拆箱的底层实现。
IntegerCache
但这里有一个陷阱问题,我们继续跟踪 Integer.valueOf 方法

这个IntegerCache ,缓存了 low 和 high 之间的 Integer 对象
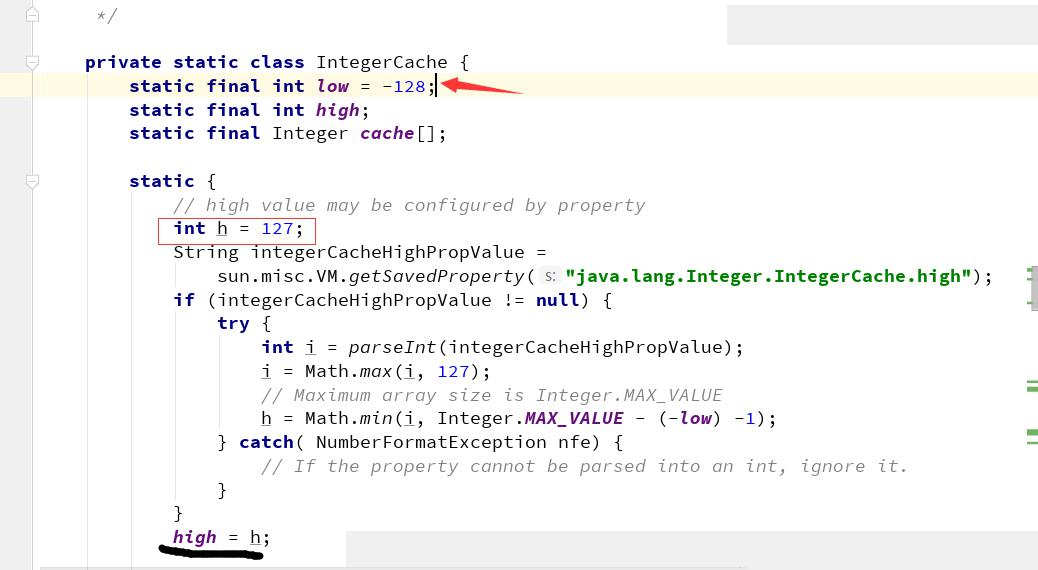
一般情况下,缓存是的 -128 到 127 之间的值,但是可以通过 -XX:AutoBoxCacheMax 来修改上限。
下面是一道经典的面试题,请考虑一下运行代码后,会输出什么结果?
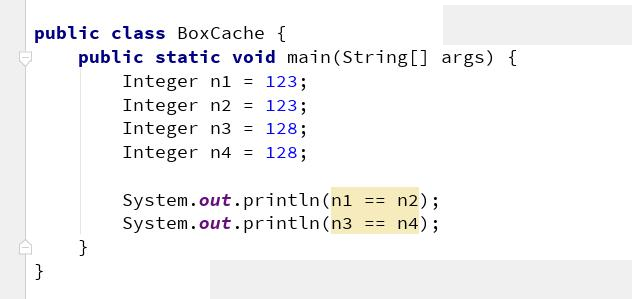
一般情况下是是 true,false 因为缓存的原因。(在缓存范围内的值,返回的是同一个缓存值,不在的话,每次都是 new 出来的)
当我加上 VM 参数 -XX:AutoBoxCacheMax=256 执行时,结果是 true,ture ,扩大缓存范围,第二个为 true 原因就在于此。
字节码指令 —— 数组
其实,数组是 JVM 内置的一种对象类型,这个对象同样是继承的 Object 类。我们使用代码来理解一下
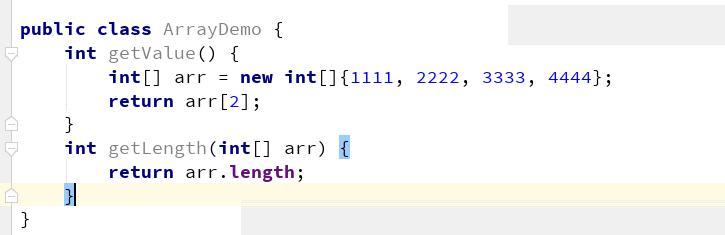
数组创建
可以看到,新建数组的代码,被编译成了 newarray 指令

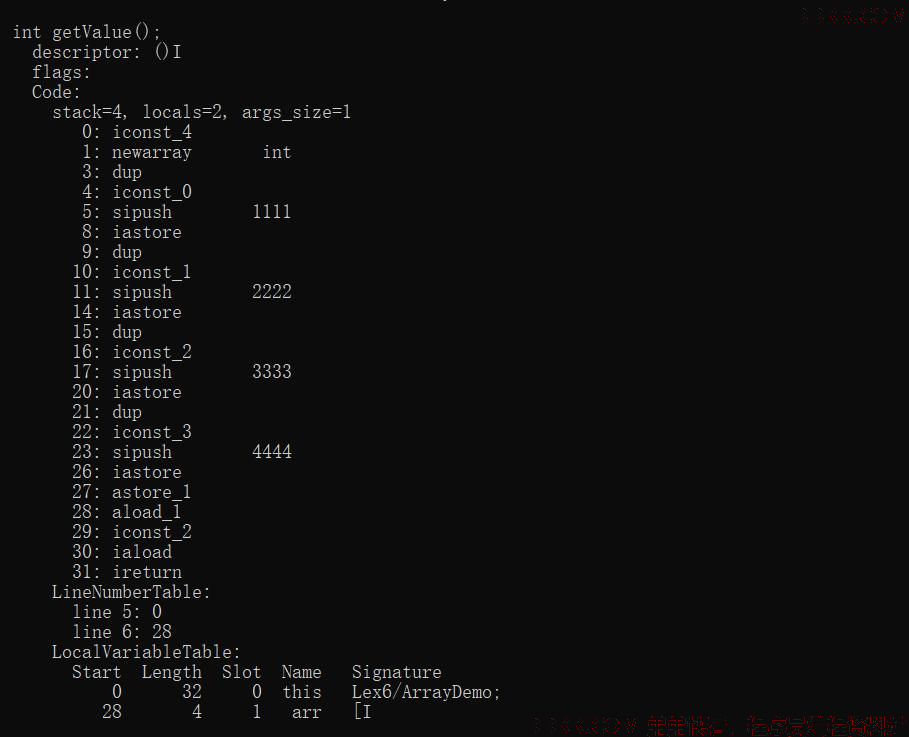
数组里的初始内容,被顺序编译成了一系列指令放入:
sipush 将一个短整型常量值推送至栈顶;
iastore 将栈顶 int 型数值存入指定数组的指定索引位置。

具体操作:
1、 iconst_0,常量0,入操作数栈;
2、 sipush;
将一个常量 1111 加载到操作数栈
3、 将栈顶int型数值存入数组的0索引位置;
为了支持多种类型,从操作数栈存储到数组,有更多的指令: bastore 、 castore 、 sastore 、 iastore 、 lastore 、 fastore 、 dastore 、 aastore 。
数组访问

数组元素的访问,是通过第 28 ~ 30 行代码来实现的:
aload_1 将第二个引用类型本地变量推送至栈顶,这里是生成的数组;
iconst_2 将 int 型 2 推送至栈顶;
iaload 将 int 型数组指定索引的值推送至栈顶。
获取数组的长度,是由字节码指令 arraylength 来完成的
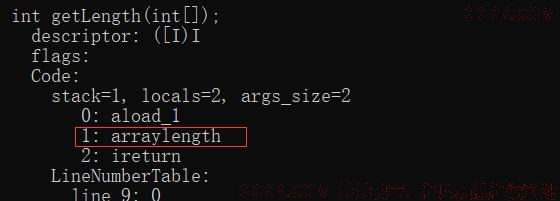
获取数组长度的指令 arraylength
字节码指令 ——foreach
无论是 Java 的数组,还是 List ,都可以使用 foreach 语句进行遍历,虽然在语言层面它们的表现形式是一致的,但实际实现的方法并不同
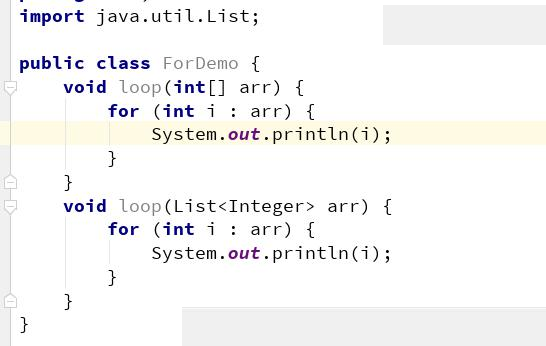
数组:它将代码解释成了传统的变量方式,即 for(int i;i<length;i++) 的形式。 List 的它实际是把 list 对象进行迭代并遍历的,在循环中,使用了 Iterator.next() 方法。 使用 jd-gui 等反编译工具,可以看到实际生成的代码:

字节码指令 —— 注解


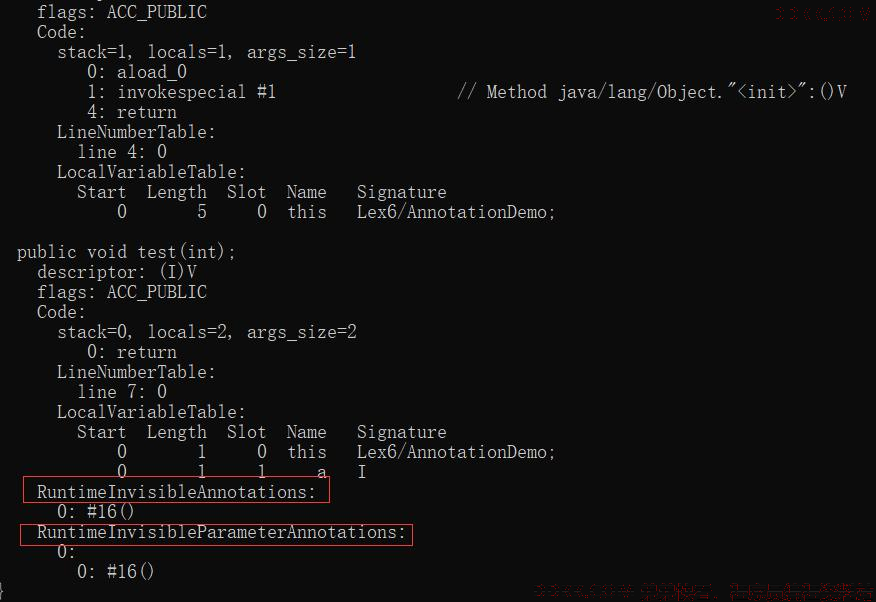
无论是类的注解,还是方法注解,都是由一个叫做 RuntimeInvisibleAnnotations 的结构来存储的,
而参数的存储,是由 RuntimeInvisibleParameterAnotations 来保证的
字节码指令总结
Java 的特性非常多,这里不再一一列出,但都可以使用这种简单的方式,从字节码层面分析了它的原理,一窥究竟。
King 老师以上操作属于抛砖引玉,给出了大家一种学习思路。 比如异常的处理、finally 块的执行顺序;以及隐藏的装箱拆箱和 foreach 语法糖的底层实现。 还有字节码指令,可能有几千行,看起来很吓人,但执行速度几乎都是纳秒级别的。Java 的无数框架,包括 JDK ,也不会为了优化这种性能对代码进行 限制。了解其原理,但不要舍本逐末,比如减少一次 Java 线程的上下文切换,就比你优化几千个装箱拆箱动作,速度来的更快一些。
深入 JVM 即时编译器 JIT
解释执行与 JIT
Java 程序在运行的时候,主要就是执行字节码指令,一般这些指令会按照顺序解释执行,这种就是解释执行,解释执行的方式是非常低效的,它需要把字 节码先翻译成机器码,才能往下执行。另外,字节码是 Java 编译器做的一次初级优化,许多代码可以满足语法分析,其实还有很大的优化空间。 所以,为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化。 完成这个任务的编译器,就称为即时编译器(Just In Time Compiler ),简称 JIT 编译器。
热点代码
热点代码,就是那些被频繁调用的代码,比如调用次数很高或者在 for 循环里的那些代码。这些再次编译后的机器码会被缓存起来,以备下次使用,但 对于那些执行次数很少的代码来说,这种编译动作就纯属浪费。 JVM 提供了一个参数“ -XX:ReservedCodeCacheSize ”,用来限制 CodeCache 的大小。也就是说, JIT 编译后的代码都会放在 CodeCache 里。
如果这个空间不足, JIT 就无法继续编译,编译执行会变成解释执行,性能会降低一个数量级。同时, JIT 编译器会一直尝试去优化代码,从而造成了 CPU 占用上升。
热点探测
在HotSpot 虚拟机中的热点探测是 JIT 优化的条件,热点探测是基于计数器的热点探测,采用这种方法的虚拟机会为每个方法建立计数器统计方法的执 行次数,如果执行次数超过一定的阈值就认为它是“ 热点方法 ” 虚拟机为每个方法准备了两类计数器:方法调用计数器(Invocation Counter )和回边计数器( Back Edge Counter )。在确定虚拟机运行参数的前提下,这 两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发 JIT 编译。
方法调用计数器
用于统计方法被调用的次数,方法调用计数器的默认阈值在 C1 模式下是 1500 次,在 C2 模式在是 10000 次,可通过 -XX: CompileThreshold 来设定; 而在分层编译的情况下,-XX: CompileThreshold 指定的阈值将失效,此时将会根据当前待编译的方法数以及编译线程数来动态调整。当方法计数器和回边 计数器之和超过方法计数器阈值时,就会触发 JIT 编译器。
回边计数器
用于统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为 “ 回边 ” ( Back Edge ),该值用于计算是否触发 C1 编译的阈值, 在不开启分层编译的情况下,C1 默认为 13995 , C2 默认为 10700 ,可通过 -XX: OnStackReplacePercentage=N 来设置;而在分层编译的情况下, -XX: OnStackReplacePercentage 指定的阈值同样会失效,此时将根据当前待编译的方法数以及编译线程数来动态调整。 建立回边计数器的主要目的是为了触发 OSR ( On StackReplacement )编译,即栈上编译。在一些循环周期比较长的代码段中,当循环达到回边计数器阈 值时, JVM 会认为这段是热点代码, JIT 编译器就会将这段代码编译成机器语言并缓存,在该循环时间段内,会直接将执行代码替换,执行缓存的机器语 言
下篇分析类加载过程和类加载器。