06、JVM 调优实战 - 调优实战之内存过高问题
调优实战:demo项目介绍:
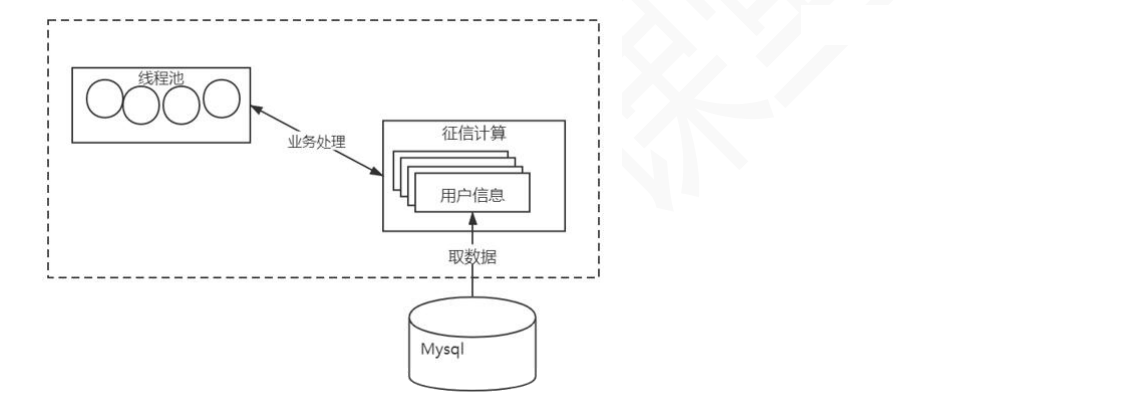
核心代码介绍:
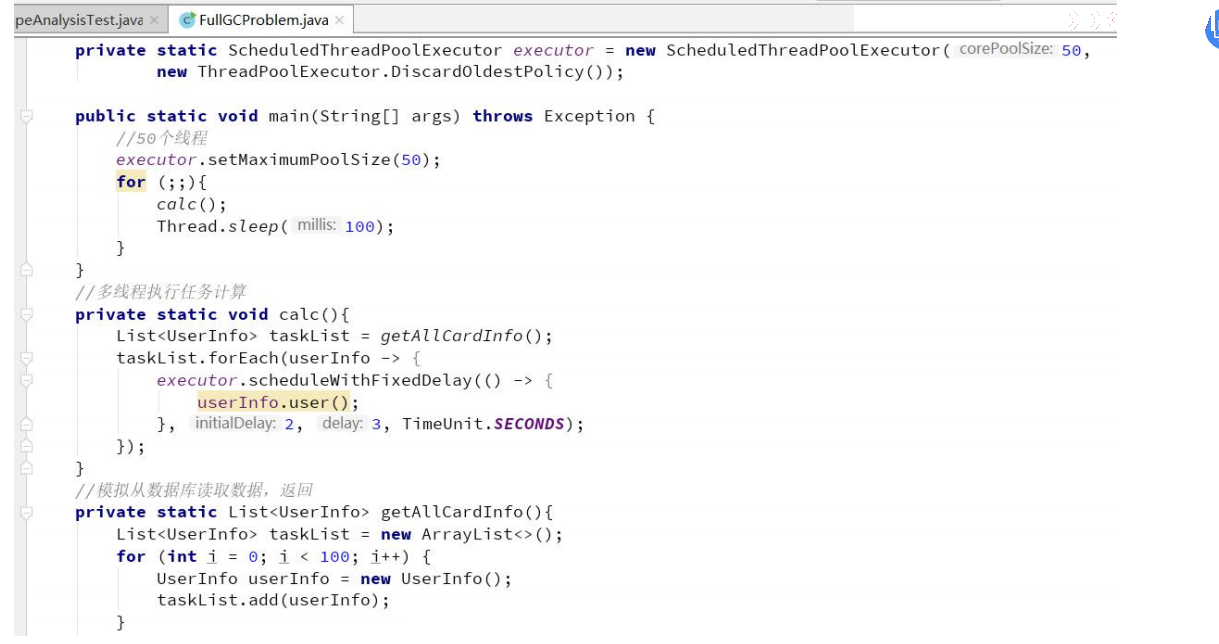
在Linux 服务跑起来
java -cp ref-jvm3.jar -XX:+PrintGC -Xms200M -Xmx200M ex13.FullGCProblem
CPU 占用过高排查实战
1. 先通过 top 命令找到消耗 cpu 很高的进程 id 假设是 2732
top 命令是我们在 Linux 下最常用的命令之一,它可以实时显示正在执行进程的 CPU 使用率、内存使用率以及系统负载等信息。其中上半部分显示的是 系统的统计信息,下半部分显示的是进程的使用率统计信息。
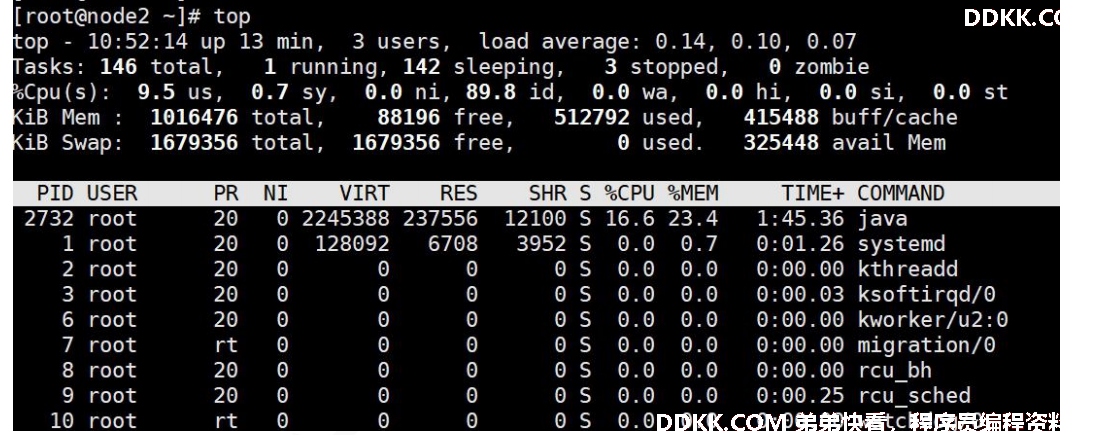
2. 执行 top -p 2732 单独监控该进程
3 、在第 2 步的监控界面输入 H ,获取当前进程下的所有线程信息
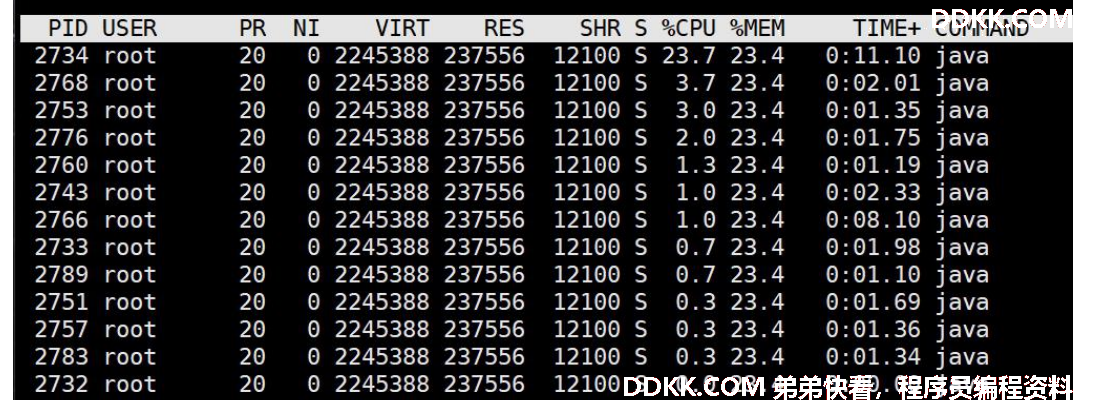
4 、找到消耗 cpu 特别高的线程编号,假设是 2734 (要等待一阵),转换成16进制;
5 、执行 jstack 2732 对当前的进程做 dump ,输出所有的线程信息;
6 将第 4 步得到的线程编号 11354 转成 16 进制是 0x7b
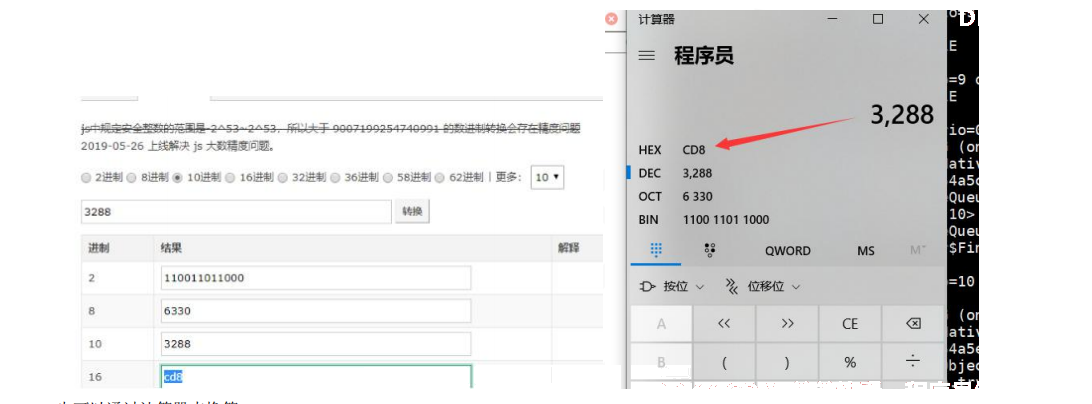
也可以通过计算器来换算。
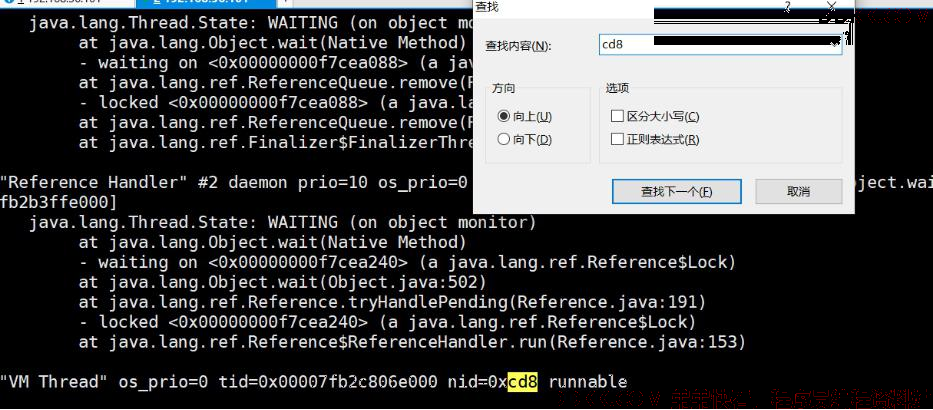
7 根据第 6 步得到的 0x7b 在第 5 步的线程信息里面去找对应线程内容
8 解读线程信息,定位具体代码位置
9、发现找是J VM 的线程占用过高,我们发现我开启的参数中,有垃圾回收的日志显示,所以我们要换一个思路,可能是我们的业务线程没问题,而是垃圾 回收的导致的。 (代码中有打印 GC 参数,生产上可以使用这个 jstat –gc 来统计,达到类似的效果) 是用于监视虚拟机各种运行状态信息的命令行工具。它可以显示本地或者远程虚拟机进程中的类装载、内存、垃圾收集、JIT 编译等运行数据,在没有 GUI 图形界面,只提供了纯文本控制台环境的服务器上,它将是运行期定位虚拟机性能问题的首选工具。 假设需要每 250 毫秒查询一次进程 13616 垃圾收集状况,一共查询 10 次,那命令应当是: jstat-gc 13616 250010
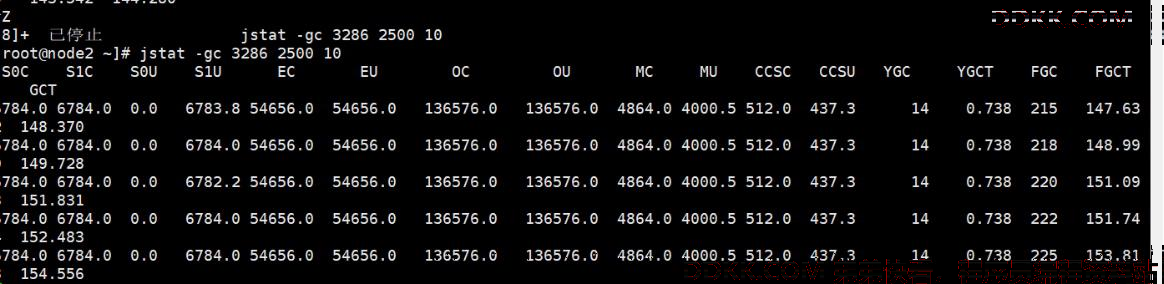
使用这个大量的 FullGC 了 还抛出了 OUT Of Memory
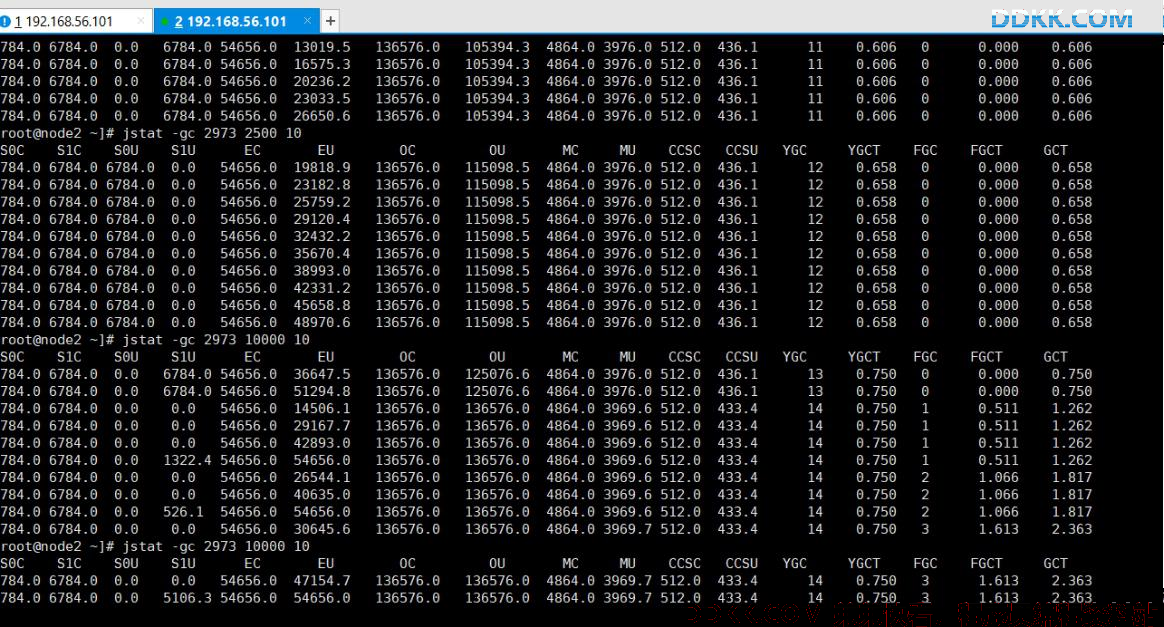
S0C:第一个幸存区的大小
S1C:第二个幸存区的大小
S0U:第一个幸存区的使用大小
S1U:第二个幸存区的使用大小
EC:伊甸园区的大小
EU:伊甸园区的使用大小
OC:老年代大小
OU:老年代使用大小
MC:方法区大小
MU:方法区使用大小
CCSC: 压缩类空间大小
CCSU: 压缩类空间使用大小
YGC:年轻代垃圾回收次数
YGCT :年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT :老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
怎么办? OOM 了 .
我们可以看到,这个里面 CPU 占用过高是什么导致的? 是业务线程吗?不是的,这个是 GC 线程占用过高导致的。 JVM 在疯狂的进行垃圾回收,再回顾下之前的知识, JVM 中默认的垃圾回收器是多线程的(回 顾下之前的文章),所以多线程在疯狂回收,导致 CPU 占用过高。
10、内存占用过高思路
用于生成堆转储快照(一般称为 heapdump 或 dump 文件)。 jmap 的作用并不仅仅是为了获取 dump 文件,它还可以查询 finalize 执行队列、 Java 堆和永 久代的详细信息,如空间使用率、当前用的是哪种收集器等。和 jinfo 命令一样, jmap 有不少功能在 Windows 平台下都是受限的,除了生成 dump 文件的 -dump 选项和用于查看每个类的实例、
空间占用统计的 -histo 选项 在所有操作系统都提供之外

把JVM 中的对象全部打印出来, 但是这样太多了,那么我们选择前 20 的对象展示出来,
jmap –histo 1196 | head -20
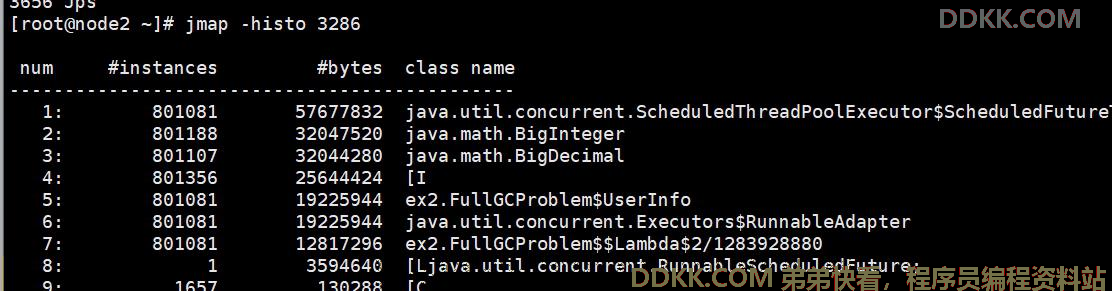
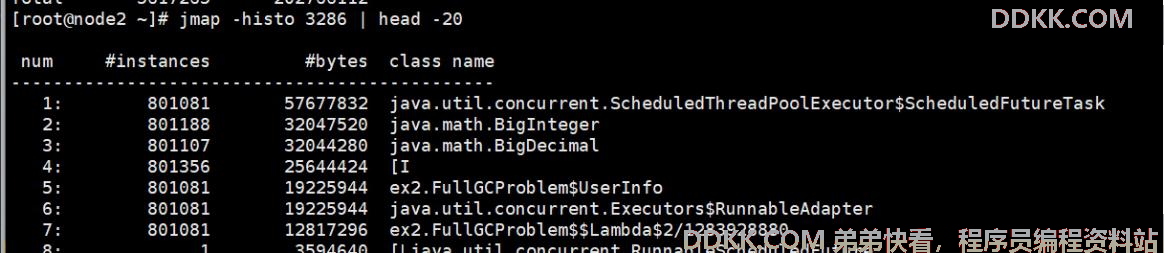
11、 定位问题的关键,就是这条命令很多个88万个对象;
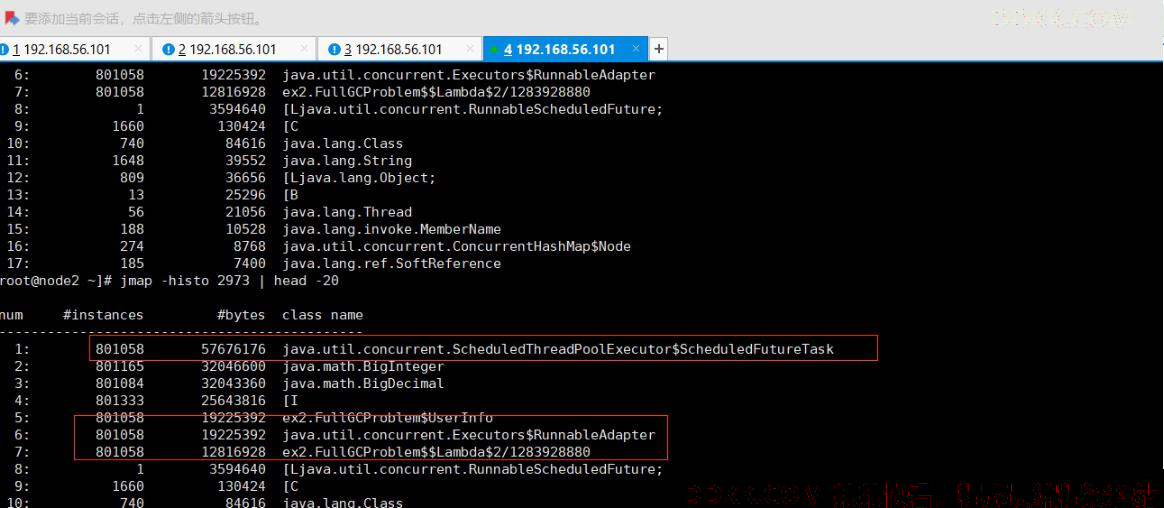
问题总结(找到问题)
一般来说,前面这几行,就可以看出,到底是哪些对象占用了内存。 这些对象回收不掉吗?是的,这些对象回收不掉,这些对象回收不掉,导致了 FullGC, 里面还有 OutOfMemory 。

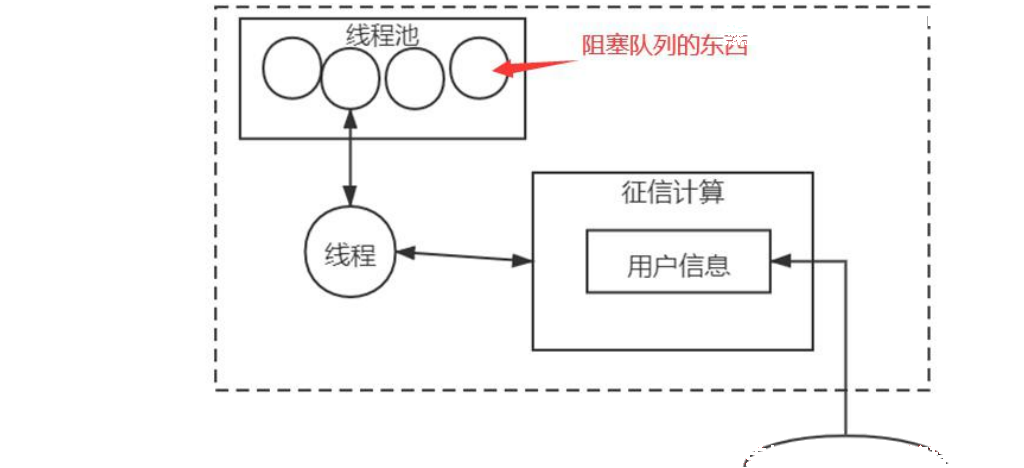
任务数多于线程数,那么任务会进入阻塞队列,就是一个队列,你进去,排队,有机会了,你就上来跑。 但是同学们,因为代码中任务数一直多于线程数,所以每 0.1S ,就会有 50 个任务进入阻塞对象, 50 个任务底下有对象,至少对象送进去了,但是没执行。 所以导致对象一直都在,同时还回收不了。
为什么回收不了。 Executor 是一个 GCroots

所以堆中,就会有对象 80 万个,阻塞队列中 80 万个任务, futureTask 。并且这些对象还回收不了。
总结
在JVM 出现性能问题的时候。(表现上是 CPU100% ,内存一直占用)
1、 如果CPU的100%,要从两个角度出发,一个有可能是业务线程疯狂运行,比如说想很多死循环还有一种可能性,就是GC线程在疯狂的回收,因为JVM中垃圾回收器主流也是多线程的,所以很容易导致CPU的100%;
2、 在遇到内存溢出的问题的时候,一般情况下我们要查看系统中哪些对象占用得比较多,我的是一个很简单的代码,在实际的业务代码中,找到对应的对象,分析对应的类,找到为什么这些对象不能回收的原因,就是我们前面讲过的可达性分析算法,JVM的内存区域,还有垃圾回收器的基础,当然,如果遇到更加复杂的情况,你要掌握的理论基础远远不止这些(JVM很多理论都是排查问题的关键);
常见问题分析
超大对象
代码中创建了很多大对象 , 且一直因为被引用不能被回收,这些大对象会进入老年代,导致内存一直被占用,很容易引发 GC 甚至是 OOM
超过预期访问量
通常是上游系统请求流量飙升,常见于各类促销 / 秒杀活动,可以结合业务流量指标排查是否有尖状峰值。 比如如果一个系统高峰期的内存需求需要 2 个 G 的堆空间,但是堆空间设置比较小,导致内存不够,导致 JVM 发起频繁的 GC 甚至 OOM 。
过多使用 Finalizer
过度使用终结器( Finalizer ),对象没有立即被 GC , Finalizer 线程会和我们的主线程进行竞争,不过由于它的优先级较低,获取到的 CPU 时间较少,因此 它永远也赶不上主线程的步伐,程序消耗了所有的可用资源,最后抛出 OutOfMemoryError 异常。
内存泄漏
大量对象引用没有释放, JVM 无法对其自动回收。
长生命周期的对象持有短生命周期对象的引用
例如将 ArrayList 设置为静态变量,则容器中的对象在程序结束之前将不能被释放,从而造成内存泄漏
连接未关闭
如数据库连接、网络连接和 IO 连接等,只有连接被关闭后,垃圾回收器才会回收对应的对象。
变量作用域不合理
例如,1. 一个变量的定义的作用范围大于其使用范围, 2. 如果没有及时地把对象设置为 null
内部类持有外部类
Java 的非静态内部类的这种创建方式,会隐式地持有外部类的引用,而且默认情况下这个引用是强引用,因此,如果内部类的生命周期长于外部类的生命 周期,程序很容易就产生内存泄漏 如果内部类的生命周期 长于 外部类的生命周期,程序很容易就产生内存泄漏(垃圾回收器会回收掉外部类的实例,但由于内部类持有外部类的引用,导 致垃圾回收器不能正常工作)
解决方法:你可以在内部类的内部显示持有一个外部类的软引用 ( 或弱引用 ) ,并通过构造方法的方式传递进来,在内部类的使用过程中,先判断一下外部 类是否被回收;
Hash 值改变
在集合中,如果修改了对象中的那些参与计算哈希值的字段,会导致无法从集合中单独删除当前对象,造成内存泄露(有代码案例 Node 类)
内存泄漏经典案例
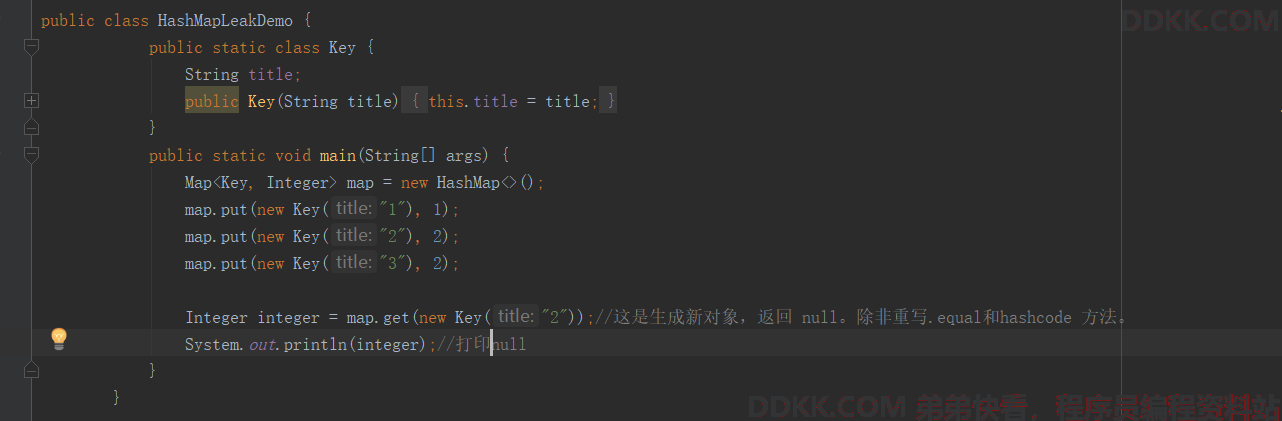
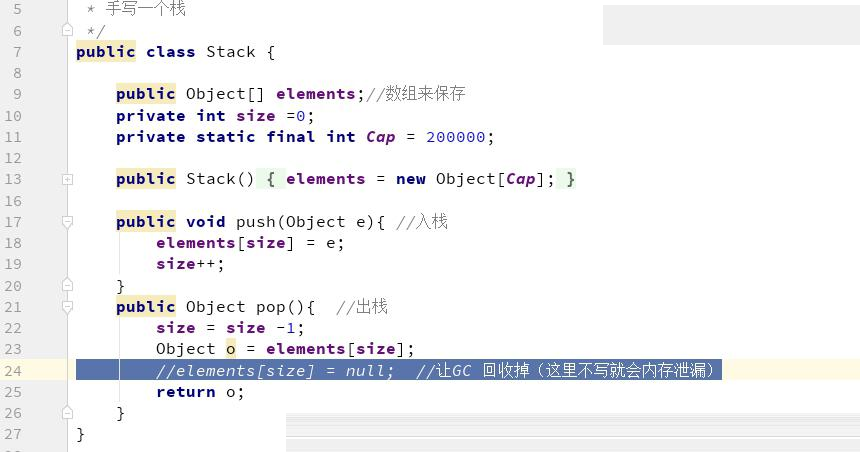
代码问题
代码问题和内存泄漏很大的关系,如果观察一个系统,每次进行 FullGC 发现堆空间回收的比例比较小,尤其是老年代,同时对象越来越多,这个时候可 以判断是有可能发生内存泄漏。
内存泄漏
程序在申请内存后,无法释放已申请的内存空间。
内存泄漏和内存溢出辨析
内存溢出:实实在在的内存空间不足导致;
内存泄漏:该释放的对象没有释放,常见于使用容器保存元素的情况下。
如何避免:
内存溢出:检查代码以及设置足够的空间
内存泄漏:一定是代码有问题
往往很多情况下,内存溢出往往是内存泄漏造成的。
我们一般优化的思路有一个重要的顺序:
1、 程序优化,效果通常非常大;
2、 扩容,如果金钱的成本比较小,不要和自己过不去;
3、 参数调优,在成本、吞吐量、延迟之间找一个平衡点;
今天的实战调优分析到这里,大家有不懂的地方随时留言,下篇我们利用 MAT 工具 分析内存泄漏,敬请期待!