08、JVM 实战 - 堆
1、堆空间的概述
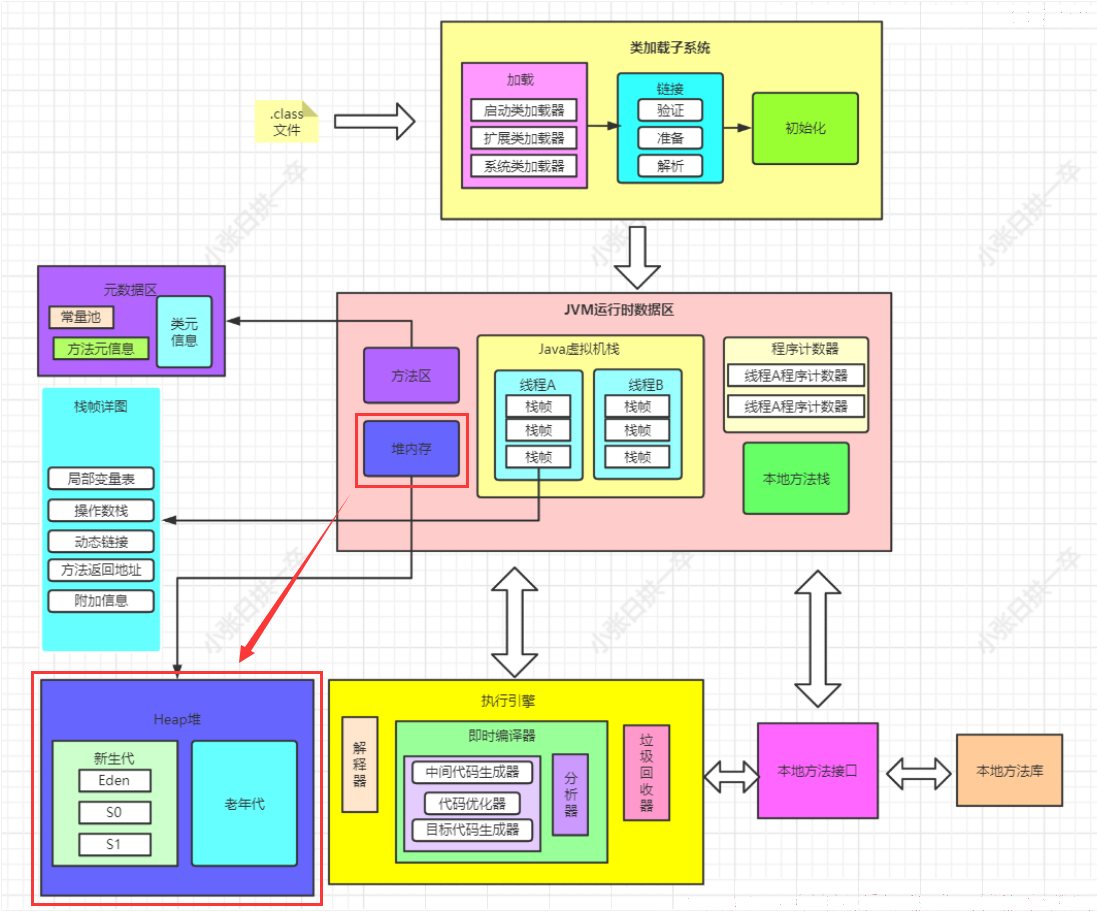
一个JVM实例只存在一个堆内存,堆也是Java内存管理的核心区域。Java堆区在JVM启动的时候即被创建,其空间大小也就确认了。堆内存的大小是可调节的,参数-Xms,-Xmx。
堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的。所有的线程共享Java堆,但这里还可以划分线程私有的缓冲区(TLAB:thread local allocation buffer)。
“几乎“所有的对象实例都在堆分配内存。有些对象可能栈上分配:逃逸分析,标量替换,但是数组和对象可能永远不会存储在栈上,因为栈帧中保存引用,引用指向对象或者数组在堆中的位置。
方法结束后,堆中的对象不会马上被移除,仅仅在垃圾回收的时候才会被移除。
- eden区满,触发GC,进行垃圾回收
- 如果堆中对象马上被回收,用户线程会受到影响,stop the world
- 堆是GC执行垃圾回收的重点区域
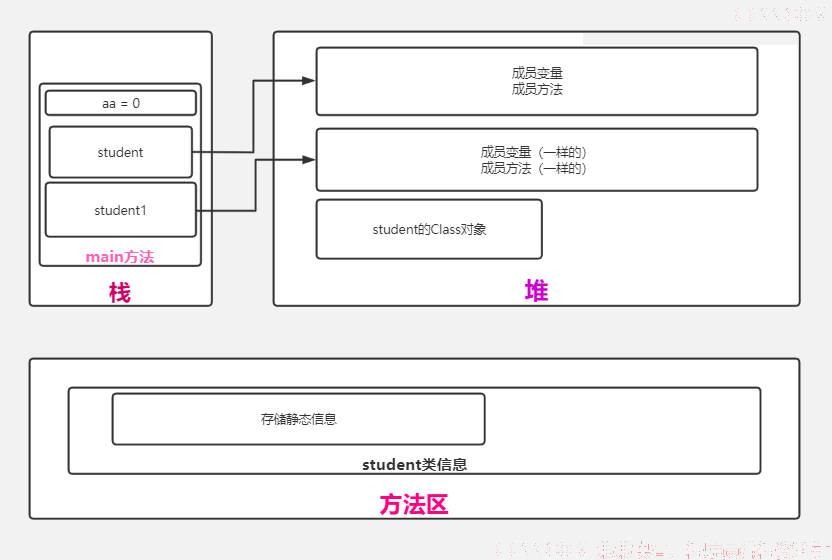
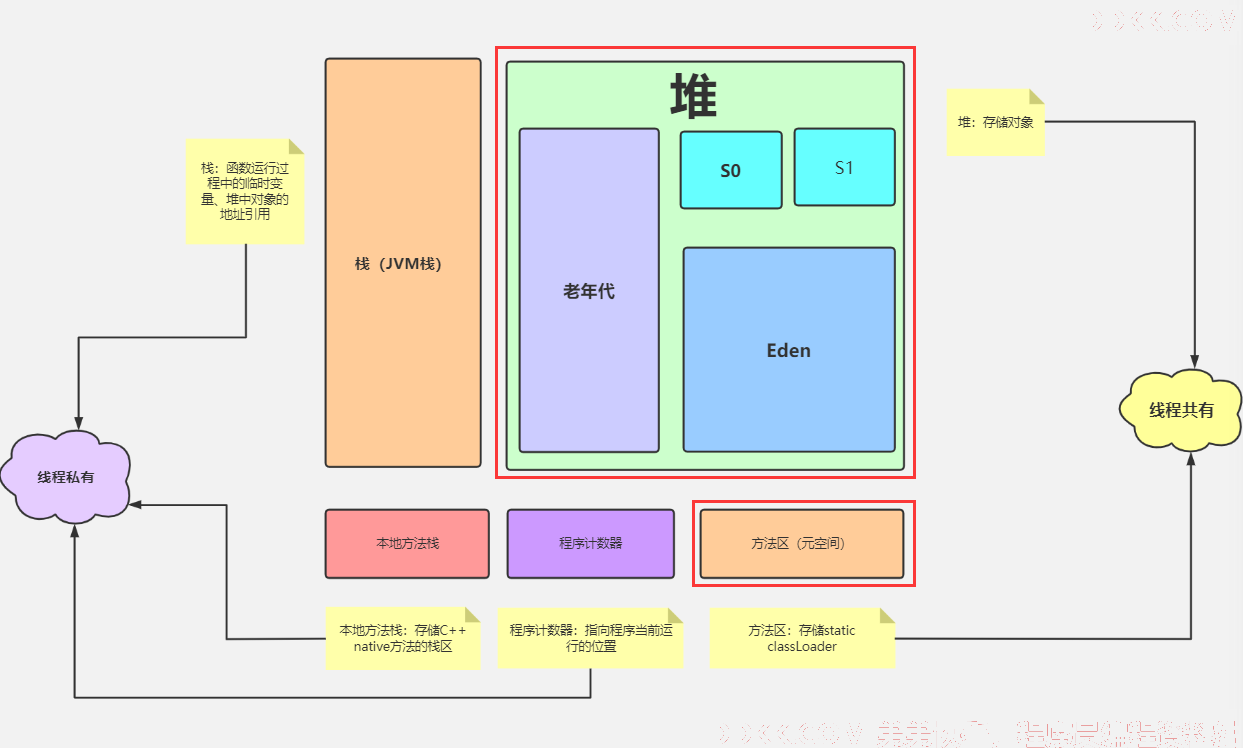
2、堆空间细分
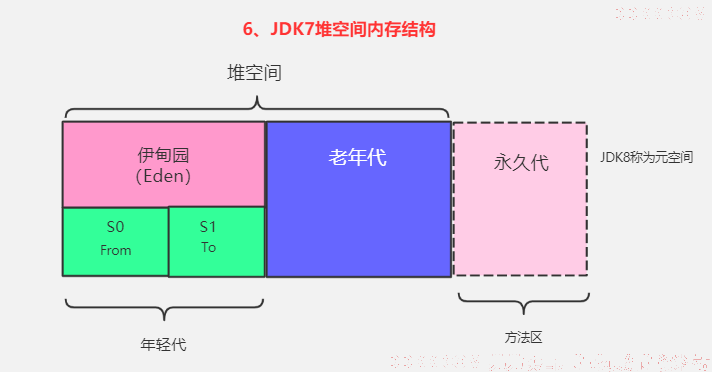
Java7及之前内存逻辑上分为:
-
新生区Young Generation Space
-
Eden区
-
Survivor区
- from
- to 谁空谁是to
-
养老区Old/Tenure generation space
-
永久区Permanent
Java8及之后内存逻辑上分为:
-
新生区
-
Eden区
-
Survivor区
- from/to 谁空谁是to
-
养老区
-
元空间Meta Space
-XX:+PrintGCDetails 可开启打印查看方法区实现
3、设置堆空间大小
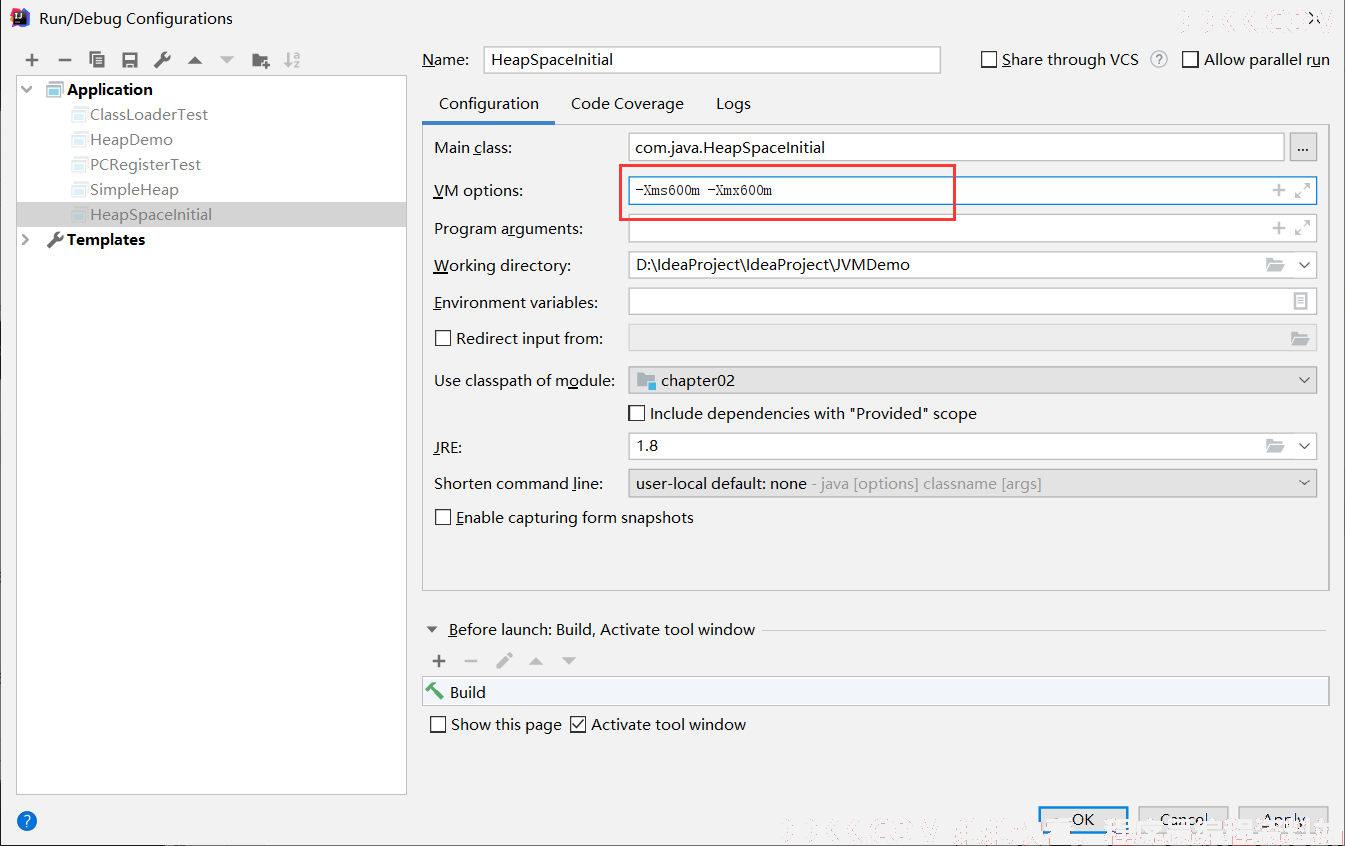
-Xms :小秘书表示堆空间(年轻代+老年代)的起始内存。
- -X 是JVM 的运行参数
- ms 是 memory start
-Xmx:小明星表示堆空间的最大内存,超过最大内存将抛出OOM。
通常将-Xms和-Xmx两个参数配置相同的值,目的:在Java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小,从而提高性能。
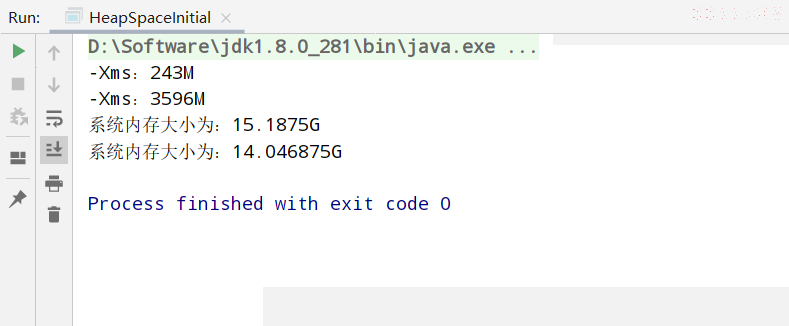
默认情况下
- 初始内存大小为:物理电脑内存大小 / 64
- 最大内存大小为:物理电脑内存大小 / 4
public class HeapSpaceInitial {
public static void main(String[] args) {
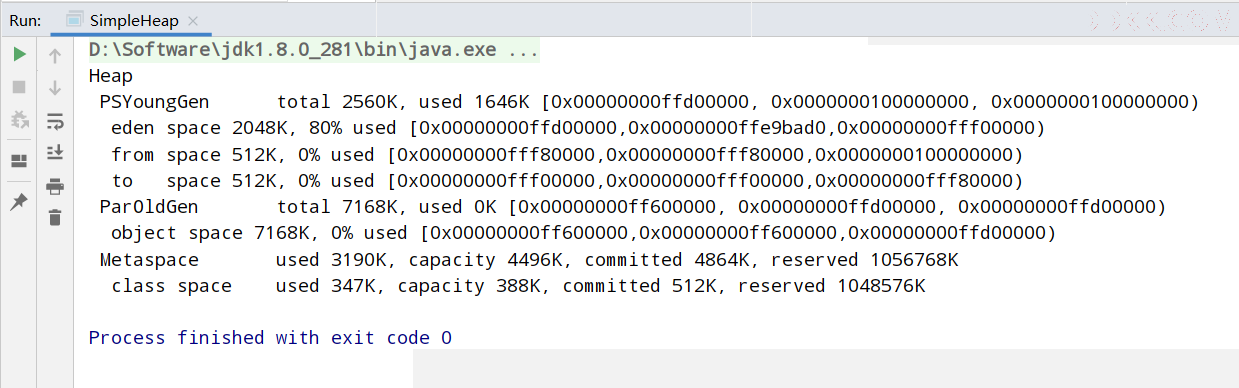
// 返回Java虚拟机中的堆内存总量
long initialMemory = Runtime.getRuntime().totalMemory() / 1024 / 1024;
// 返回Java虚拟机试图使用的最大堆内存容量
long maxMemory = Runtime.getRuntime().maxMemory() / 1024 / 1024;
System.out.println("-Xms:" + initialMemory + "M");
System.out.println("-Xms:" + maxMemory + "M");
System.out.println("系统内存大小为:" + initialMemory * 64.0 / 1024 + "G");
System.out.println("系统内存大小为:" + maxMemory * 4.0 / 1024 + "G");
}
}
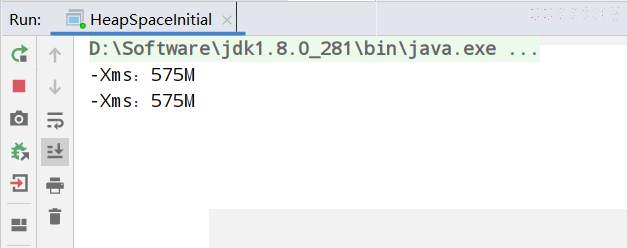
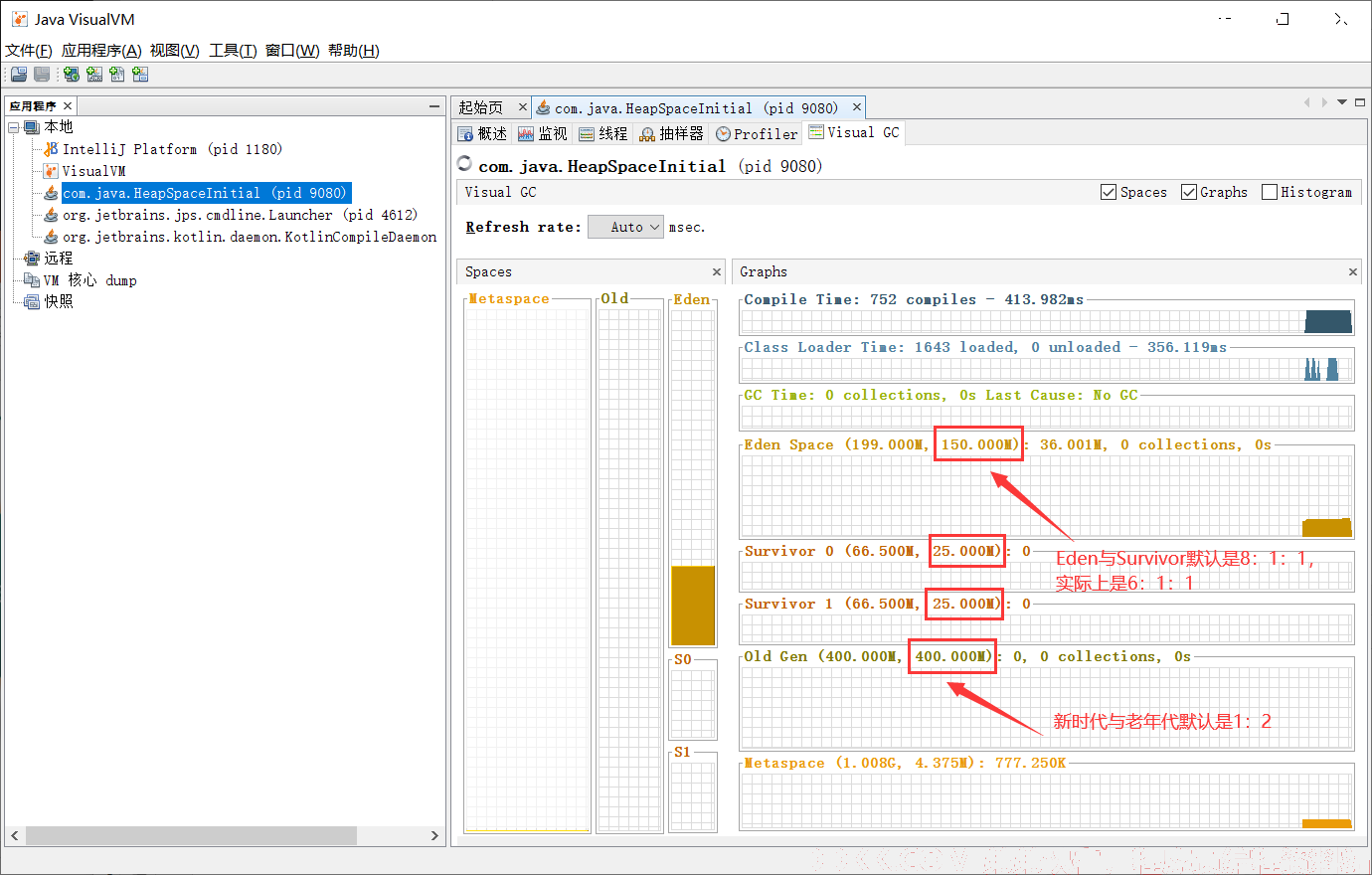
当我设置JVM参数后
运行结果:
查看堆内存信息方法:
方式一:
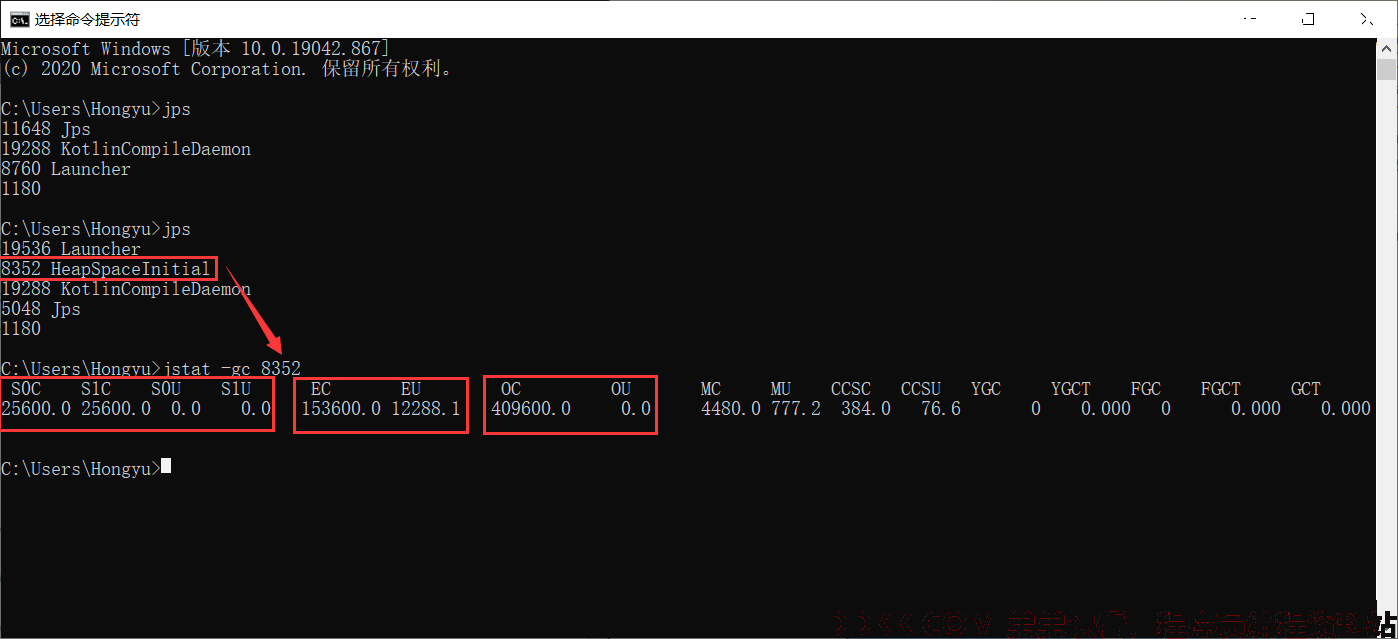
- jps命令 查看当前程序运行的进程
- jstat 查看JVM在gc时的统计信息 jstat -gc 进程号
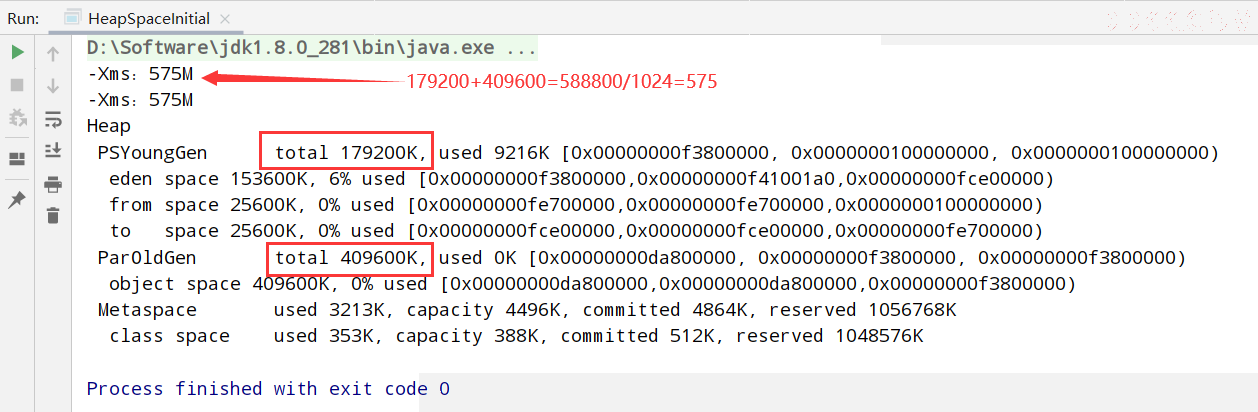
方式二:-XX:+PrintGCDetails
4、新生代与老年代
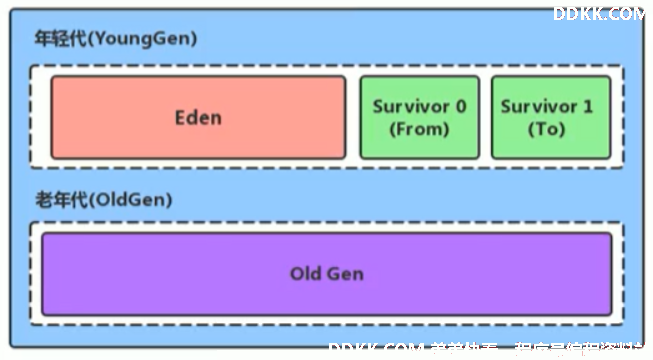
Java对象划分为两类:生命周期短和长的,新生代与老年代空间默认比例 1 : 2。
- -XX:NewRatio=2 表示新生代占1,老年代占2,新生代占整个堆的1/3,ratio:比率比例的意思。
- jinfo -flag NewRatio 进程号,查看参数设定值
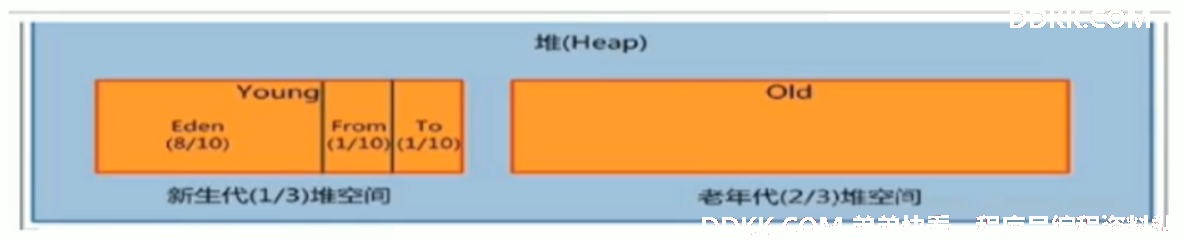
在HotSpot中,Eden空间和另外两个Survivor空间缺省所占的比例是:8:1:1
- -XX:SurvivorRatio 调整Eden与Survivor区的比例,实际是6:1:1,因为有自适应机制
- -XX:-UseAdaptiveSizePolicy:-表示关闭自适应,实际没有用。直接用 -XX:SurvivorRatio=8
几乎所有的Java对象都是在Eden区被new出来的。
- IBM研究表明,新生代80%的对象都是朝生夕死
- -Xmn:洗面奶,设置新生代最大内存大小,如果同时设置了新生代比例与此参数冲突,则以此参数为准。
(面试常问)为什么要有新生代和老年代?
- 分代的目的:优化GC的性能(不分代完全可以)
- 若不分代–>GC需要扫描整个堆空间,分代之后–>对具体某一区域进行适合的GC
- 不同代根据其特点进行不同的垃圾回收算法–>提高回收效率(分代收集算法)
(面试常问)为什么新生代被划分为Eden和survivor?
- 如果没有survivor区,Eden区进行一次MinorGC,存活对象–>老年代–满-->MajorGC
- MajorGC消耗时间更长,影响程序执行和响应速度。
- survivor存在意义:增加进入老年代的筛选条件,减少送到老年代的对象,减少FullGC的次数。
(面试常问)为什么要设置两个survivor区?
- 如果只有一个survivor区,在第一次Eden区满进行MinorGC,存活对象放到survivor区;第二次Eden区满MinorGC–>survivor区,会产生不连续的内存,无法存放更多的对象。
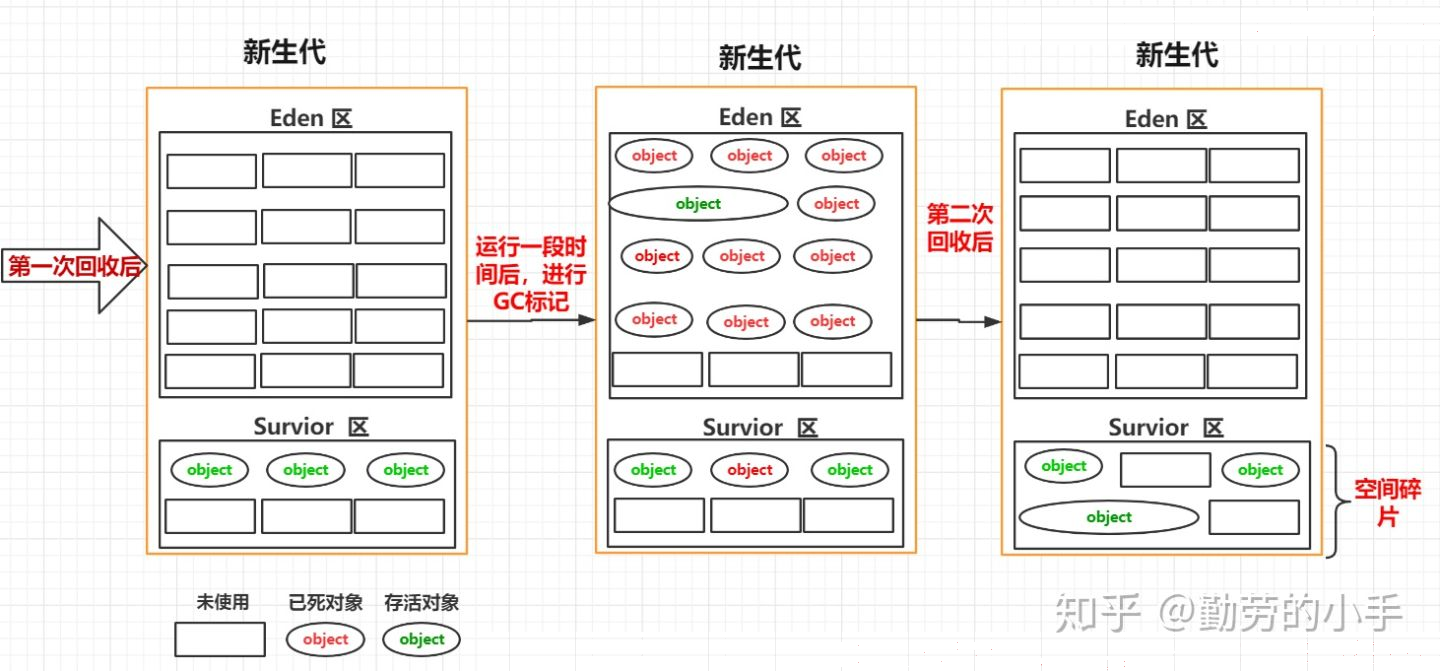
- 如果设置三个四个survivor区,则每个被分配的survivor空间相对较小,很快被填满。
- 设置两个survivor区,在MinorGC时可以将Eden区和S0存活的对象以连续存储的方式存入S1区。减少碎片化。(清除阶段的复制算法)
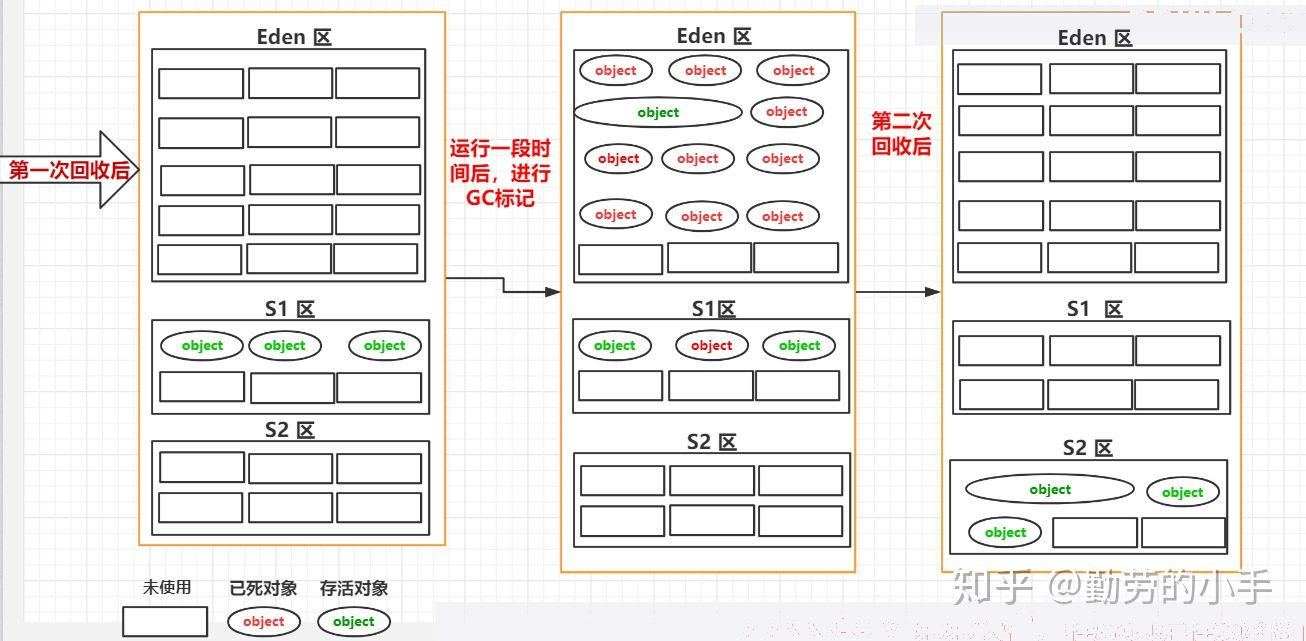
- 复制算法也是减少碎片化的过程(减少Eden区,减少survivor区)
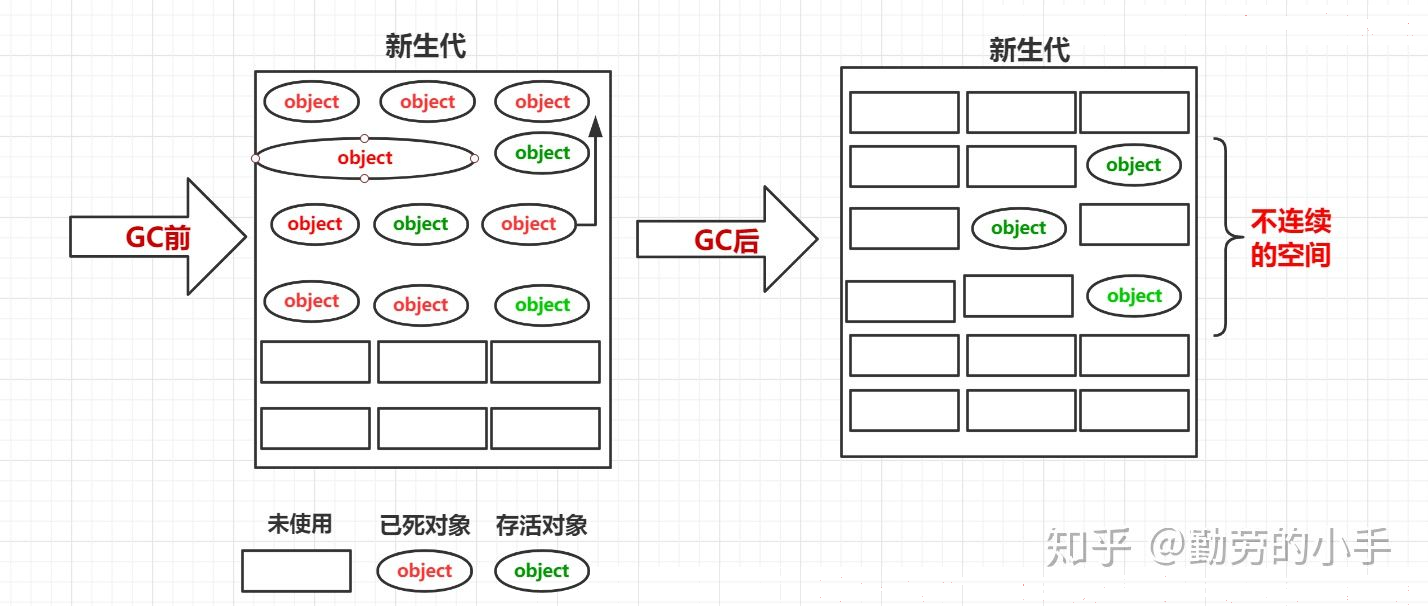
5、图解对象分配一般过程
1、 new的对象先放Eden区,放得下直接放入(此区有大小限制参数-Xmn一般默认);
2、 当创建新对象,Eden空间填满,会触发一次MinorGC/YGC,将Eden不再被其他对象引用的对象进行销毁将Eden中未销毁的对象移到survive0区survive0区每个对象都有一个年龄计数器,一次回收还存在的对象,年龄加1;
3、 如果Eden有空间,加载的新对象放到Eden区(超大对象放不下入老年代);
4、 再次eden区满,触发垃圾回收,回收eden+survive0,幸存下来的放在survive1区,年龄加1;
5、 再垃圾回收,又会将幸存者重新放回survive0区,依次类推;
6、 超大对象放入老年代,老年代满或放不下,触发majorGC,再放不下,OOM;
7、 可以设置存活次数,默认15次,超过15次,对象将从年轻区步入老年区;
-XX:MaxTenuringThreshold=N 进行设置
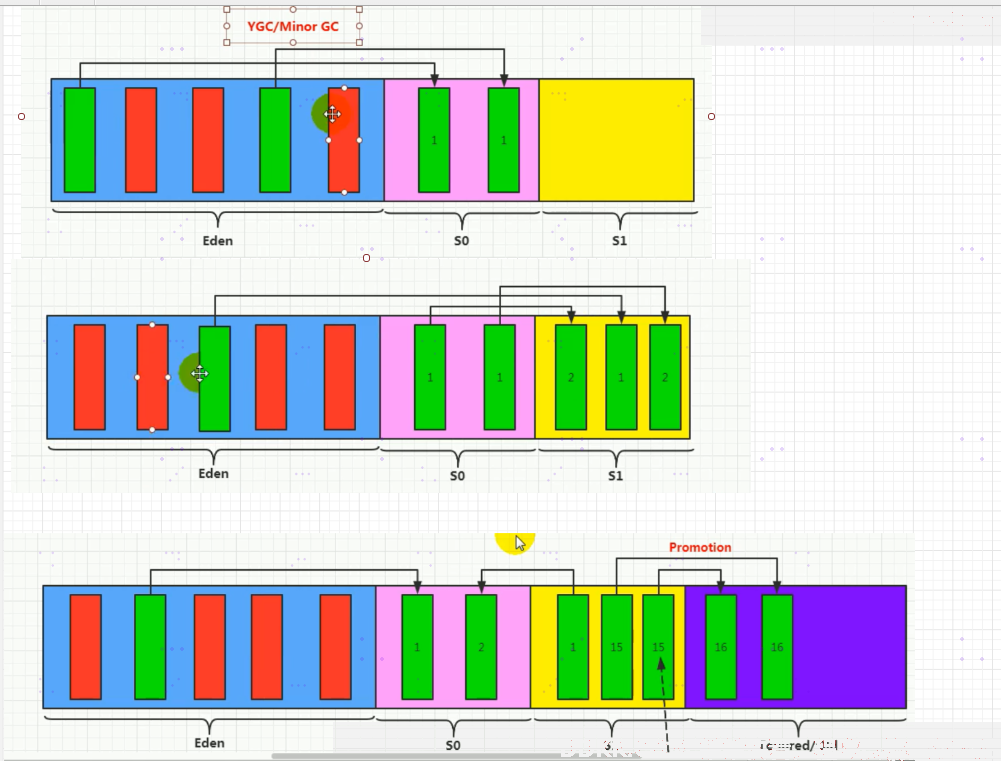
总结:
- 针对幸存者s0,s1区的总结:复制之后有交换,谁空谁是to。
- 新生代采用复制算法的目的:为了减少内碎片。
- 频繁在新生区收集,很少在养老区收集,几乎不在永久区/元空间搜集
6、对象分配特殊过程
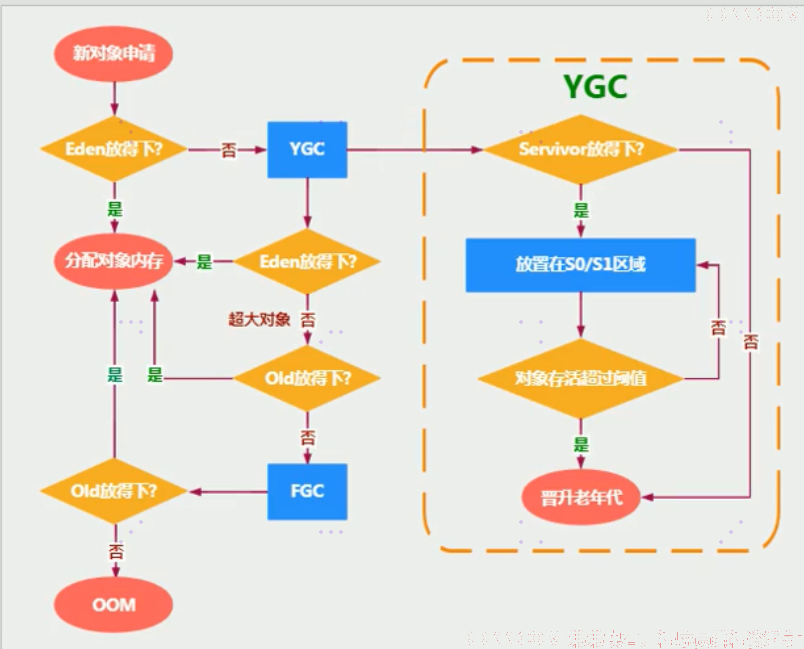
- 触发YGC,survive区就会进行回收,不会主动进行回收
幸存区满了咋办?
- 特别注意,在Eden区满了的时候,才会触发MinorGC,而幸存者区满了后,不会触发MinorGC操作
- 如果Survivor区满了后,新对象可能直接晋升老年代
(面试常问)说一下 JVM 调优的工具?
- JDK命令行
- Eclipse:Memory Analyzer Tool
- Jconsole:用于对 JVM 中的内存、线程和类等进行监控
- jvisualVM:JDK 自带的全能分析工具,可以分析:内存快照、线程快照、程序死锁、监控内存的变化、gc 变化等。
- Jprofiler
- Java Flight Recorder
7、分代收集思想 MinorGC,MajorGC,FullGC
GC按照内存回收区域分为:
-
部分收集,不是完整收集整个Java堆
-
新生代收集,MinorGC (YoungGC),新生代( Eden、S0/S1 )的垃圾收集
-
老年代收集,MajorGC/oldGC,注意很多时候MajorGC与FullGC混淆使用,具体分辨是老年代回收还是整堆回收
-
混合收集,收集整个新生代以及部分老年代的垃圾收集。
-
整堆收集,收集整个Java堆和方法区的垃圾收集
MinorGC的触发条件:
- Eden区满,触发MinorGC,Survivor区满不触发GC。每次MinorGC会清理年轻代(eden+survivor)的内存
- 因为Java对象大多朝生夕灭,所以MinorGC非常频繁
- MinorGC会引发STW
老年代GC(MajorGC/FullGC)触发条件:
- 老年代空间不足,会触发MinorGC,也就是老年代空间不足,会先尝试触发MinorGC,如果之后空间还不足,则触发MajorGC或FullGC。还不足,OOM
- MajorGC的速度比MinorGC慢10倍以上,STW的时间更长
FullGC的触发机制:
1、 调用System.gc()时,系统建议执行FullGC,但是不必然执行;
2、 老年代空间不足;
3、 方法区空间不足;
4、 通过MinorGC后进入老年代的平均大小,大于老年代的可用内存;
5、 由Eden区,Survivor0区向Survivor1区复制时,对象的大小大于ToSpace可用内存,则把改对象转存到老年代,且老年代的可用内存小于该对象的大小;
6、 FullGC是开发或调优中尽量要避免的,这样暂停时间会短一些;
STW暂停其它用户的线程,等待垃圾回收线程结束,用户线程才恢复运行。
Minor GC 针对于新生区,Major GC 针对于老年区,Full GC 针对于整个堆空间和方法区。
(面试常问)简述分代垃圾回收器是怎么工作的?
- 老年代:新生代=2:1
- Eden区:from区:to区=8:1:1
1、 Eden区满,进行GC,将Eden+from区存活的对象移动到to区;
2、 清空Eden和FromSurvivor分区,from/to调换名称;
3、 对象到to区后,对象头的GC分代年龄加一,到达年龄阈值后进入老年代;to区满eden区的对象可能直接进入老年代;大对象可能直接进入老年代;
4、 老年代达到一定阈值时,进行老年代的垃圾回收(标记-压缩算法);
(面试常问)堆空间分代思想(堆空间为什么分代)?
可以不分代,分代目的:优化GC性能,避免对所有对象进行扫描,统一对新对象进行管理
(面试常问)GC第一大任务:内存分配(第二大任务:内存回收)
如果对象再Eden出生并经过第一次MinorGC后仍然存活,并且能被Survivor区容纳,则被移动到Survivor空间中,并将对象年龄设置为1,对象在Survivor区每熬过一次MinorGC,年龄就+1,当年龄增加到一定程度(默认为15,不同Jvm,GC都所有不同)时,就会被晋升到老年代中。 -XX:MaxTenuringThreshold
内存分配策略:
- 优先分配到Eden
- 大对象直接分配到老年代,尽量避免程序中出现过多的大对象
- 长期存活的对象分配到老年代
- 动态对象年龄分配:如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代,无需等到MaxTenuringThreshold中要求的年龄。
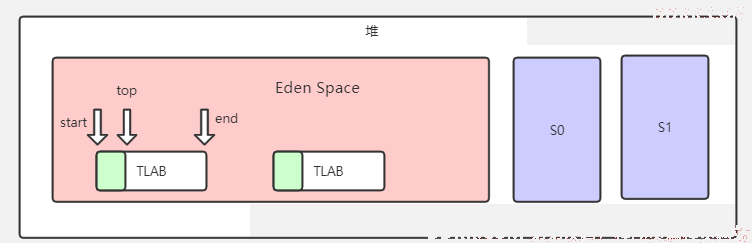
8、为对象分配内存TLAB
- Thread Local Allocation Buffer
- 堆区是线程共享区域,任何线程都可以访问到堆区的共享数据
由于对象实例的创建在JVM中非常频繁,因此在并发环境下从堆区中划分内存空间是线程不安全的。为避免多个线程操作(指针碰撞方式分配内存)同一地址,需要使用加锁等机制,进而影响分配速度。
从内存模型而不是垃圾收集的角度,对Eden区域进行划分,JVM为每个线程分配了一个私有缓存区域,包含在Eden空间中,多线程同时分配内存时,使用TLAB可以避免一系列的非线程安全问题,同时还能够提升内存分配的吞吐量,因此我们将这种内存分配方式称为快速分配策略,openjdk衍生出来的JVM都提供了TLAB的设计。
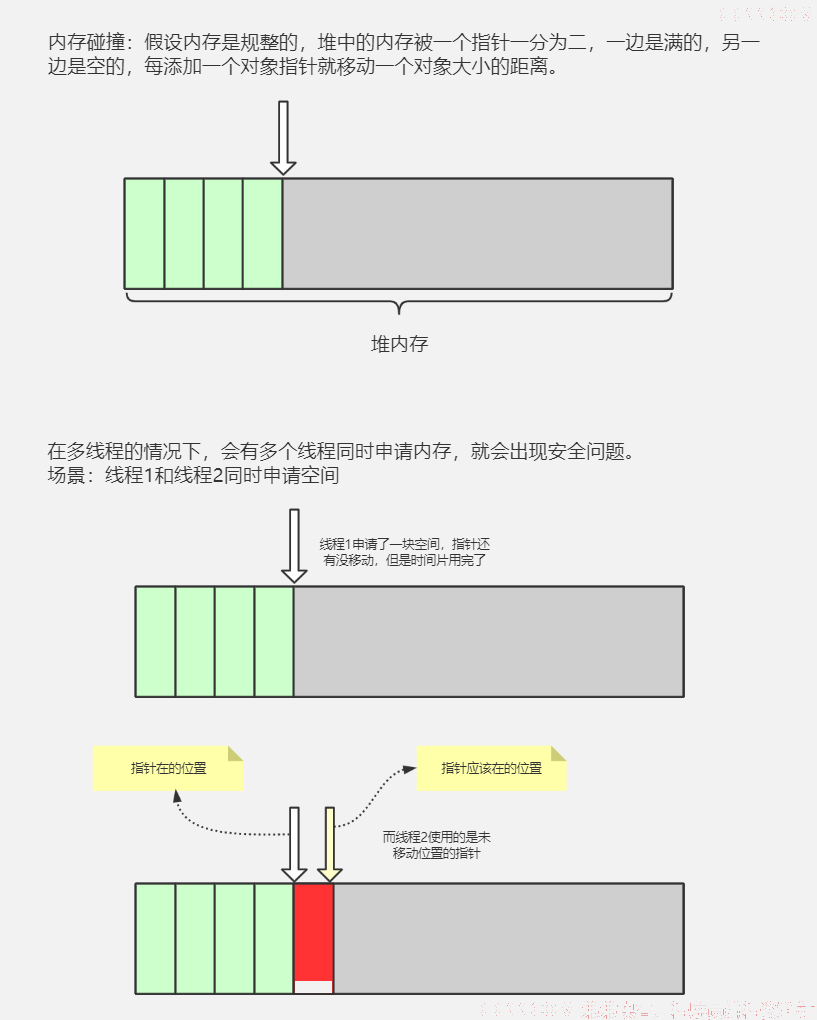
解决这个问题可以使用CAS,或者加锁。但是CAS和加锁想能都比较低,所以设计了TLAB
- TLAB结合指针碰撞实现了多线程下不加锁快速分配内存。
- TLAB在Eden园区,而且空间很小
- TLAB本质是三个指针管理的区域,start、top和end。start和end是占用位,TLAB在指针碰撞后会重新申请一个新的,l旧的空间留在原地。
- 大对象的直接在Eden Space中创建
补充:
- 尽管不是所有的对象实例都能够在TLAB中成功分配内存,但是JVM确实是将TLAB作为内存分配的首选
- 开发人员通过 -XX:UseTLAB 设置是否开启TLAB空间
- 默认情况下,TLAB空间内存非常小,仅占有整个Eden空间的1%,通过 -XX:TLABWasteTargetPercent 设置TLAB空间所占用Eden空间的百分比大小
- 一旦对象在TLAB空间分配内存失败,JVM就会尝试通过使用加锁机制确保数据操作的原子性,从而直接在Eden空间中分配内存
- HotSpot虚拟机对象探秘–>对象创建–>并发问题
9、堆空间的参数设置
(面试常问)常用的 JVM 调优的参数都有哪些?
-
-XX:+PrintFlagsInitial :查看所有的参数的默认初始值
-
-XX:+PrintFlagsFinal :查看所有的参数的最终值(可能会存在修改,不再是初始值)
-
具体查看某个参数的指令:
-
jps :查看当前运行中的进程
-
jinfo -flag survivorRatio 进程id
-
-Xms :初始堆空间内存(默认为物理内存的1/64)
-
-Xmx :最大堆空间内存(默认为物理内存的1/4)
-
-Xmn :设置新生代的大小。(初始值及最大值)
-
-XX:NewRatio=2 :设置新生代与老年代内存比例为1:2
-
-XX:SurviveRatio=8 :设置eden区与survivor区内存比例为8:1:1
-
-XX:MaxTenuringThreshold : 设置分代年龄阈值
-
-XX:+PrintGCDetails :打印 gc 详细信息
-
-XX:+PrintGC :开启打印 gc 信息
-
-XX:HandlePromotionFailure :是否设置空间分配担保,JKD7之后这个参数不会再影响到虚拟机的空间分配担保策略,规则改为只要老年代的连续空间大于新生代对象总大小,或者历次晋升的平均大小,就会进行MinorGC,否则进行FullGC。
10、逃逸分析
(面试常问):堆是分配对象的唯一选择吗?
- 随着JIT编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术,将会导致一些微秒变化,所有对象分配到堆上渐渐变得不那么绝对了。
- 逃逸分析,未逃逸,栈上分配。
- 有一种特殊情况,如果经过逃逸分析后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配,这样无需堆上分配,也不需要垃圾回收了,也是最常见的堆外存储技术。
逃逸分析概述
- 逃逸分析的基本行为就是分析对象动态作用域
- 当一个对象在方法中定义后,对象只在方法内部使用,则认为没有发生逃逸
- 当一个对象在方法中被定义后,它被外部方法引用,则认为发生逃逸,例如作为调用参数传递到其他地方中

- 启示:开发中使用局部变量,替代在方法外定义。
逃逸分析的代码优化分为3个部分:
1、 栈上分配:调用栈内运行,线程结束,栈空间被回收,局部变量对象也被回收无须进行垃圾回收;
实验代码
public class StackAllocation {
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
alloc();
}
long end = System.currentTimeMillis();
System.out.println("花费时间:" + (end - start));
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private static void alloc() {
User user = new User(); // 未发生逃逸
}
private static class User {
}
}
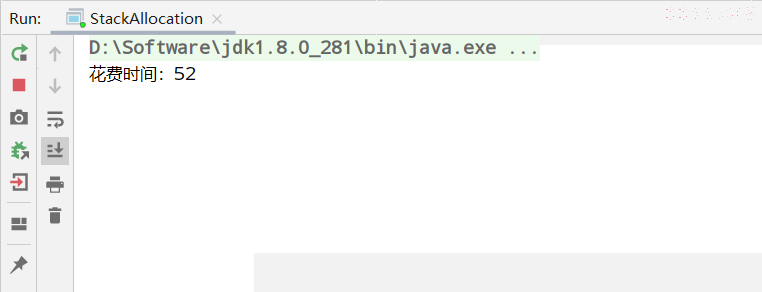
-Xmx1G -Xms1G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails // jvm参数,关闭逃逸分析
运行结果:
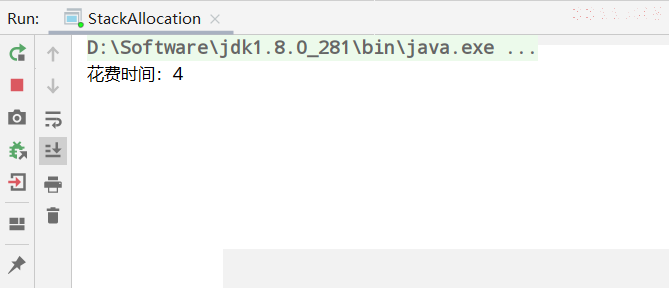
-Xmx1G -Xms1G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails // 开启逃逸分析之后
运行结果:
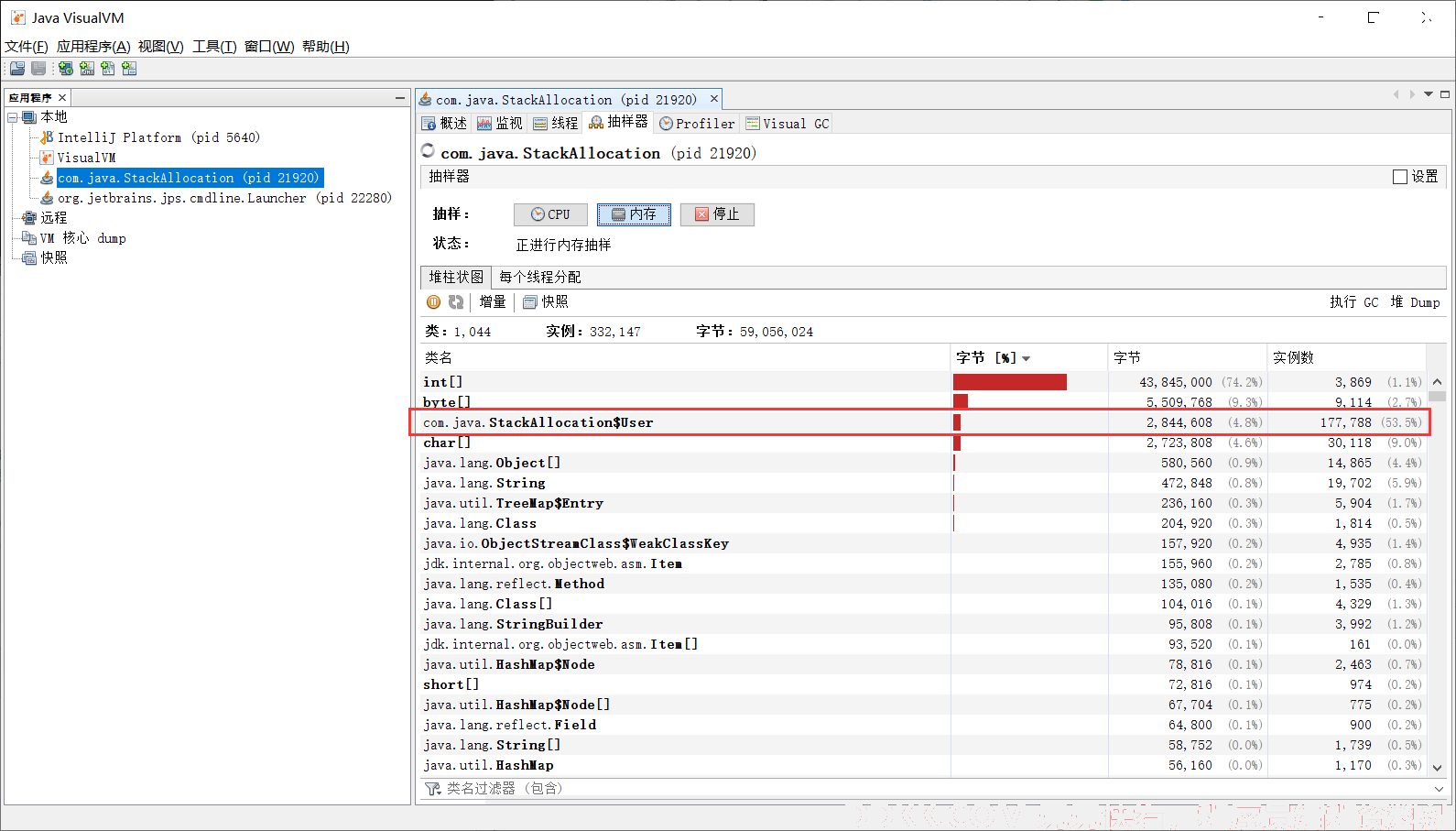
2、 同步策略:如果一个对象被发现只能从一个线程被访问到,对于这个对象的操作可以不考虑同步;

JIT编译器可以借助逃逸分析来判断同步块所使用的的锁对象,是否只能够被一个线程访问,而没有被发布到其他线程。如果没有,那么 JIT编译器在编译这个同步块的时候,就会取消对这部分代码的同步。这样就大大提高并发性和性能,这个取消同步的过程就叫同步省略,也叫锁消除。
3、 标量替换;
JIT编译器在编译阶段,经过逃逸分析,发现一个对象不会被外界访问,那么经过JIT优化,就会把这对象拆解成若干个成员变量来代替。
标量:无法再分解的更小的数据,如Java中原始数据类型,聚合量分解为标量。


开启逃逸分析,且未发生逃逸,对象保存到栈上,保存到局部变量表,但没有开启标量替换,所以还是在堆上,开启之后就保存在栈上。
标量替换参数:-XX:EliminateAllocations,默认打开