08、ShardingSphere 实战:编排治理(八)
导览
提供注册中心、配置动态化、数据库熔断禁用、调用链路等治理能力。
配置中心
实现动机
- 配置集中化:越来越多的运行时实例,使得散落的配置难于管理,配置不同步导致的问题十分严重。将配置集中于配置中心,可以更加有效进行管理。
- 配置动态化:配置修改后的分发,是配置中心可以提供的另一个重要能力。它可支持数据源、表与分片及读写分离策略的动态切换。
配置中心数据结构
配置中心在定义的命名空间的config下,以YAML格式存储,包括数据源,数据分片,读写分离、Properties配置,可通过修改节点来实现对于配置的动态管理。
config
├──authentication Sharding-Proxy权限配置
├──props 属性配置
├──schema Schema配置
├ ├──sharding_db SchemaName配置
├ ├ ├──datasource 数据源配置
├ ├ ├──rule 数据分片规则配置
├ ├──masterslave_db SchemaName配置
├ ├ ├──datasource 数据源配置
├ ├ ├──rule 读写分离规则
config/authentication
password: root
username: root
config/sharding/props
相对于sharding-sphere配置里面的Sharding Properties。
executor.size: 20
sql.show: true
config/schema/schemeName/datasource
多个数据库连接池的集合,不同数据库连接池属性自适配(例如:DBCP,C3P0,Druid, HikariCP)。
ds_0: !!org.apache.shardingsphere.orchestration.yaml.YamlDataSourceConfiguration
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
properties:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
password: null
maxPoolSize: 50
maintenanceIntervalMilliseconds: 30000
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
minPoolSize: 1
username: root
maxLifetimeMilliseconds: 1800000
ds_1: !!org.apache.shardingsphere.orchestration.yaml.YamlDataSourceConfiguration
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
properties:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
password: null
maxPoolSize: 50
maintenanceIntervalMilliseconds: 30000
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
minPoolSize: 1
username: root
maxLifetimeMilliseconds: 1800000
config/schema/sharding_db/rule
数据分片配置,包括数据分片 + 读写分离配置。
tables:
t_order:
actualDataNodes: ds_$->{0..1}.t_order_$->{0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_$->{user_id % 2}
keyGenerator:
column: order_id
logicTable: t_order
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_$->{order_id % 2}
t_order_item:
actualDataNodes: ds_$->{0..1}.t_order_item_$->{0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_$->{user_id % 2}
keyGenerator:
column: order_item_id
logicTable: t_order_item
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_$->{order_id % 2}
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDataSourceName: ds_0
masterSlaveRules: {}
config/schema/masterslave/rule
读写分离独立使用时使用该配置。
name: ds_ms
masterDataSourceName: ds_master
slaveDataSourceNames:
- ds_slave0
- ds_slave1
loadBalanceAlgorithmType: ROUND_ROBIN
动态生效
在注册中心上修改、删除、新增相关配置,会动态推送到生产环境并立即生效。
编排治理
实现动机
通过注册中心,提供熔断数据库访问程序对数据库的访问和禁用从库的访问的能力。治理仍然有大量未完成的功能。
注册中心数据结构
注册中心在定义的命名空间的state下,创建数据库访问对象运行节点,用于区分不同数据库访问实例。包括instances和datasources节点。
instances
├──your_instance_ip_a@-@your_instance_pid_x
├──your_instance_ip_b@-@your_instance_pid_y
├──....
datasources
├──ds0
├──ds1
├──....
Sharding-Proxy支持多逻辑数据源,因此datasources子节点的名称采用schema_name.data_source_name的形式。
instances
├──your_instance_ip_a@-@your_instance_pid_x
├──your_instance_ip_b@-@your_instance_pid_y
├──....
datasources
├──sharding_db.ds0
├──sharding_db.ds1
├──....
state/instances
数据库访问对象运行实例信息,子节点是当前运行实例的标识。 运行实例标识由运行服务器的IP地址和PID构成。运行实例标识均为临时节点,当实例上线时注册,下线时自动清理。 注册中心监控这些节点的变化来治理运行中实例对数据库的访问等。
state/datasources
可以治理读写分离从库,可动态添加删除以及禁用。
操作指南
熔断实例
可在IP地址@-@PID节点写入DISABLED(忽略大小写)表示禁用该实例,删除DISABLED表示启用。
Zookeeper命令如下:
[zk: localhost:2181(CONNECTED) 0] set /your_zk_namespace/your_app_name/state/instances/your_instance_ip_a@-@your_instance_pid_x DISABLED
Etcd命令如下:
etcdctl set /your_app_name/state/instances/your_instance_ip_a@-@your_instance_pid_x DISABLED
禁用从库
在读写分离(或数据分片+读写分离)场景下,可在数据源名称子节点中写入DISABLED(忽略大小写)表示禁用从库数据源,删除DISABLED或节点表示启用。
Zookeeper命令如下:
[zk: localhost:2181(CONNECTED) 0] set /your_zk_namespace/your_app_name/state/datasources/your_slave_datasource_name DISABLED
Etcd命令如下:
etcdctl set /your_app_name/state/datasources/your_slave_datasource_name DISABLED
支持的注册中心
SPI
Service Provider Interface (SPI)是一种为了被第三方实现或扩展的API。它可以用于实现框架扩展或组件替换。
ShardingSphere在数据库治理模块使用SPI方式载入注册中心,进行实例熔断和数据库禁用。 目前,ShardingSphere内部支持Zookeeper和Etcd两种常用的注册中心。 此外,您可以使用其他第三方注册中心,并通过SPI的方式注入到ShardingSphere,从而使用该注册中心,实现数据库治理功能。
Zookeeper
ShardingSphere官方使用Apache Curator作为Zookeeper的实现方案。 请使用Zookeeper 3.4.6及其以上版本,详情请参见官方网站。
Etcd
ShardingSphere官方使用原生的Etcd作为Etcd的实现方案。 请使用Etcd V3及其以上版本,详情请参见官方网站。
其他
使用SPI方式自行实现相关逻辑编码。
应用性能监控
背景
APM是应用性能监控的缩写。目前APM的主要功能着眼于分布式系统的性能诊断,其主要功能包括调用链展示,应用拓扑分析等。
ShardingSphere并不负责如何采集、存储以及展示应用性能监控的相关数据,而是将SQL解析与SQL执行这两块数据分片的最核心的相关信息发送至应用性能监控系统,并交由其处理。 换句话说,ShardingSphere仅负责产生具有价值的数据,并通过标准协议递交至相关系统。ShardingSphere可以通过两种方式对接应用性能监控系统。
第一种方式是使用OpenTracing API发送性能追踪数据。面向OpenTracing协议的APM产品都可以和ShardingSphere自动对接,比如SkyWalking,Zipkin和Jaeger。使用这种方式只需要在启动时配置OpenTracing协议的实现者即可。 它的优点是可以兼容所有的与OpenTracing协议兼容的产品作为APM的展现系统,如果采用公司愿意实现自己的APM系统,也只需要实现OpenTracing协议,即可自动展示ShardingSphere的链路追踪信息。 缺点是OpenTracing协议发展并不稳定,较新的版本实现者较少,且协议本身过于中立,对于个性化的相关产品的实现不如原生支持强大。
第二种方式是使用SkyWalking的自动探针。 ShardingSphere团队与SkyWalking团队共同合作,在SkyWalking中实现了ShardingSphere自动探针,可以将相关的应用性能数据自动发送到SkyWalking中。
使用方法
使用OpenTracing协议
- 方法1:通过读取系统参数注入APM系统提供的Tracer实现类
启动时添加参数
-Dorg.apache.shardingsphere.opentracing.tracer.class=org.apache.skywalking.apm.toolkit.opentracing.SkywalkingTracer
调用初始化方法
ShardingTracer.init();
- 方法2:通过参数注入APM系统提供的Tracer实现类
ShardingTracer.init(new SkywalkingTracer());
注意:使用SkyWalking的OpenTracing探针时,应将原ShardingSphere探针插件禁用,以防止两种插件互相冲突
使用SkyWalking自动探针
请参考SkyWalking部署手册。
效果展示
无论使用哪种方式,都可以方便的将APM信息展示在对接的系统中,以下以SkyWalking为例。
应用架构
使用Sharding-Proxy访问两个数据库192.168.0.1:3306和192.168.0.2:3306,且每个数据库中有两个分表。
拓扑图展示
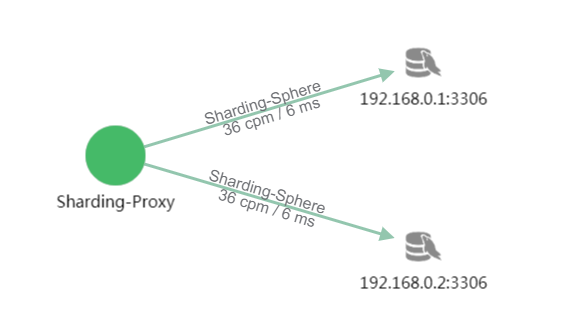
从图中看,用户访问18次Sharding-Proxy应用,每次每个数据库访问了两次。这是由于每次访问涉及到每个库中的两个分表,所以每次访问了四张表。
跟踪数据展示
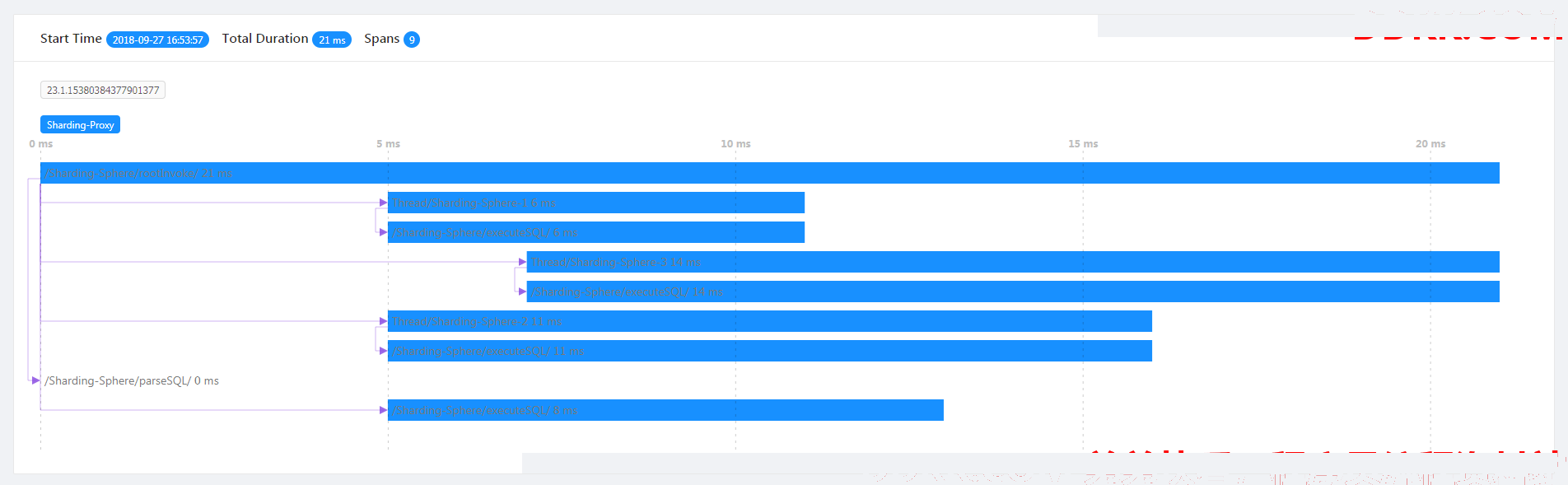
从跟踪图中可以能够看到SQL解析和执行的情况。
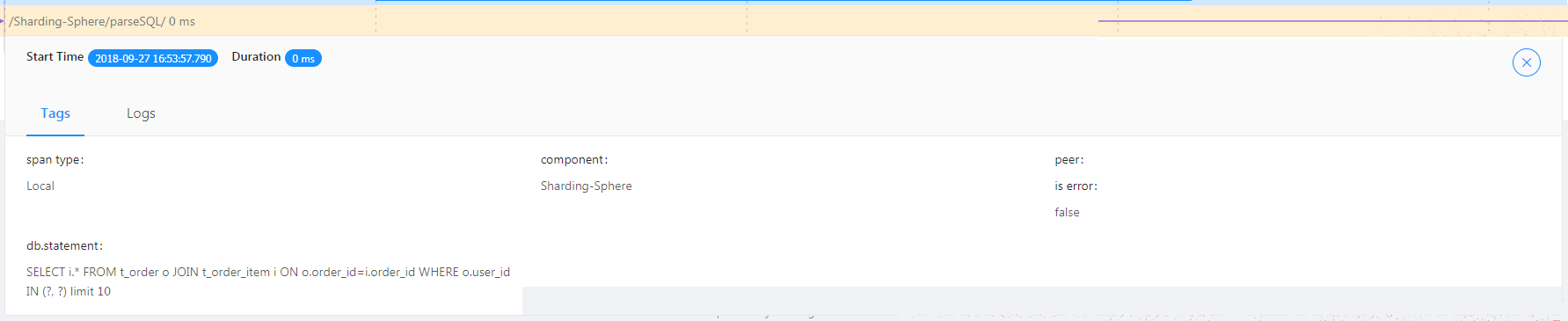
/Sharding-Sphere/parseSQL/ : 表示本次SQL的解析性能。
 ]
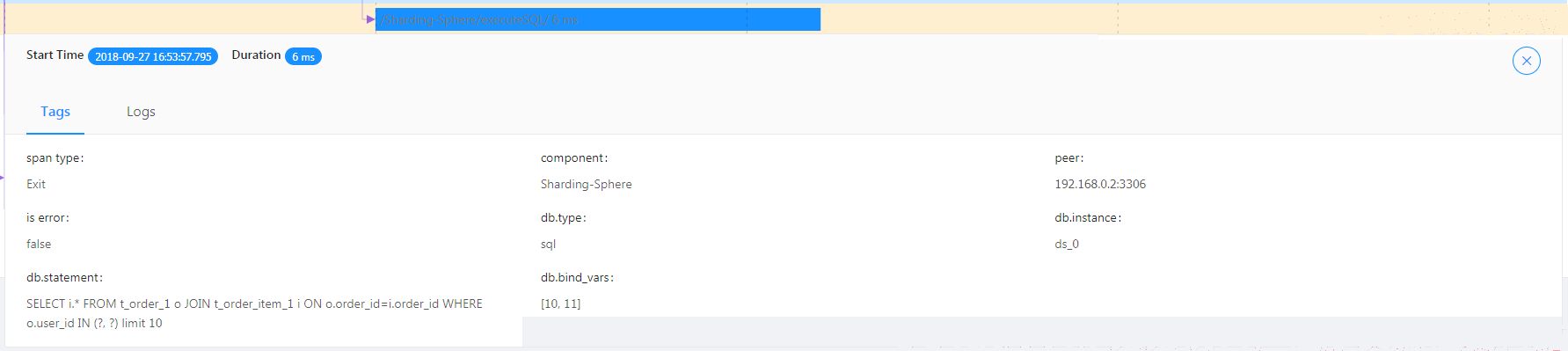
]/Sharding-Sphere/executeSQL/ : 表示具体执行的实际SQL的性能。
 ]
]异常情况展示
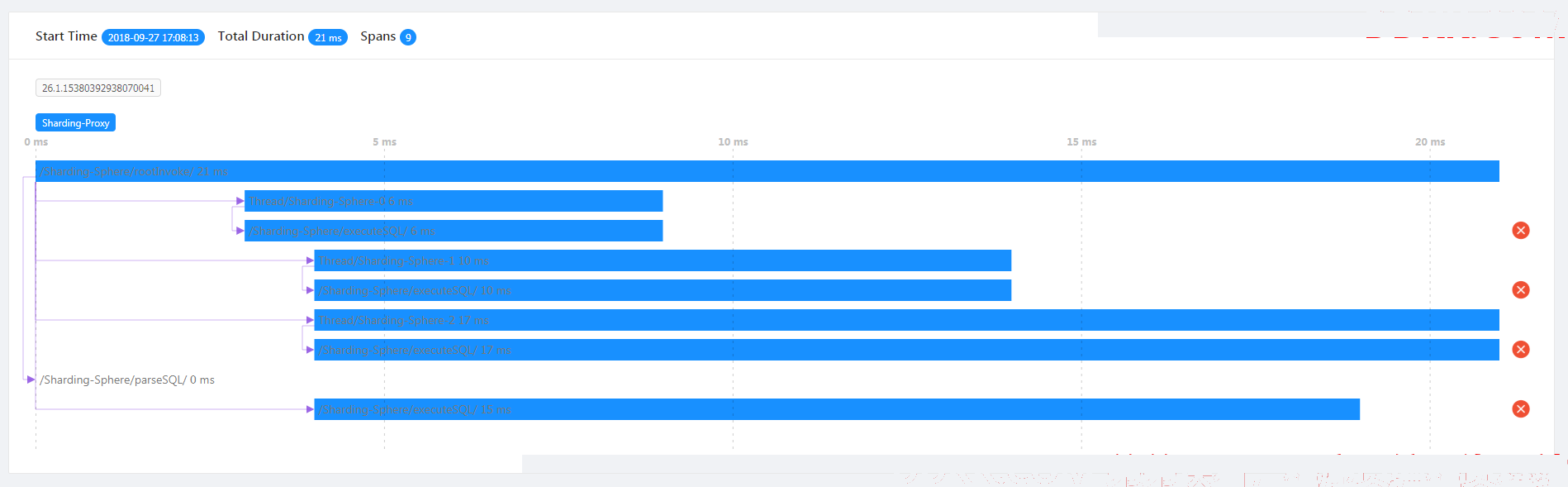 ]
]从跟踪图中可以能够看到发生异常的节点。
/Sharding-Sphere/executeSQL/ : 表示执行SQL异常的结果。
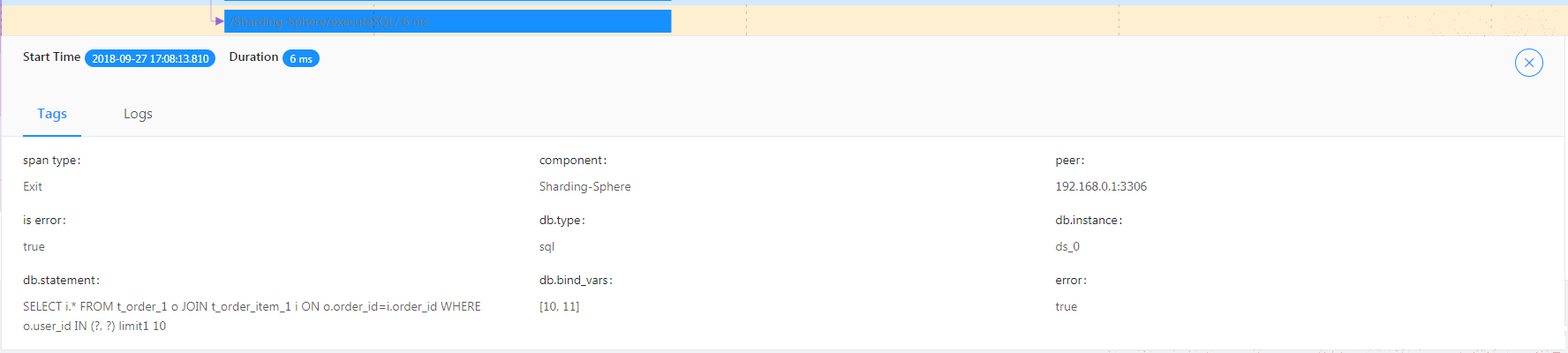 ]
]/Sharding-Sphere/executeSQL/ : 表示执行SQL异常的日志。
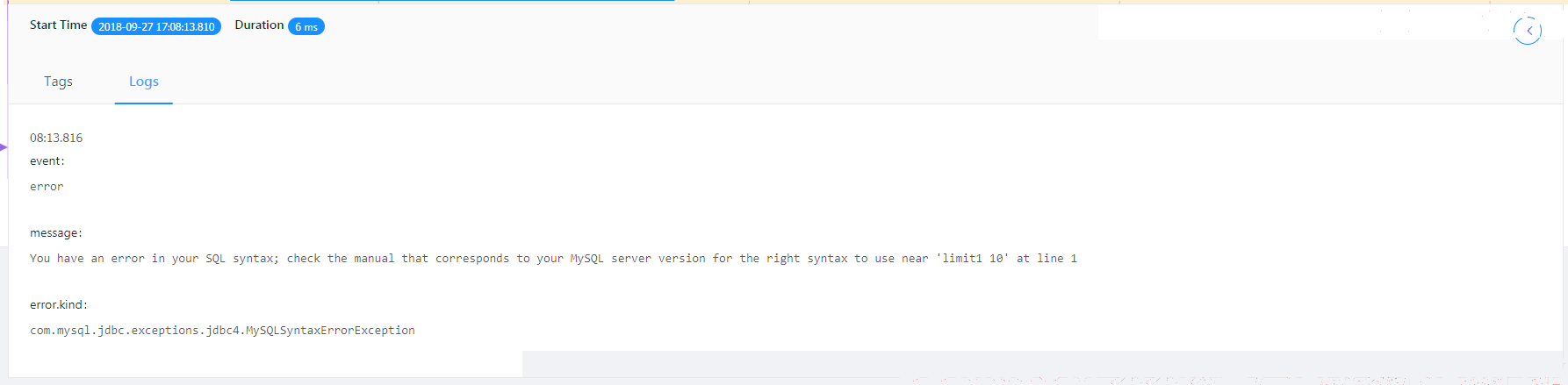 ]
]数据脱敏
一、背景
安全控制一直是治理的重要环节,数据脱敏属于安全控制的范畴。对互联网公司、传统行业来说,数据安全一直是极为重视和敏感的话题。数据脱敏是指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。涉及客户安全数据或者一些商业性敏感数据,如身份证号、手机号、卡号、客户号等个人信息按照相关部门规定,都需要进行数据脱敏。
在真实业务场景中,相关业务开发团队则往往需要针对公司安全部门需求,自行实行并维护一套加解密系统,而当脱敏场景发生改变时,自行维护的脱敏系统往往又面临着重构或修改风险。此外,对于已经上线的业务,如何在不修改业务逻辑、业务SQL的情况下,透明化、安全低风险地实现无缝进行脱敏改造呢?
Apache ShardingSphere根据业界对脱敏的需求及业务改造痛点,提供了一套完整、安全、透明化、低改造成本的数据脱敏整合解决方案。
二、前序
Apache ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(规划中)这3款相互独立,却又能够混合部署配合使用的产品组成。它们均能够提供标准化的数据分片、分布式事务和分布式治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
数据脱敏模块属于ShardingSphere分布式治理这一核心功能下的子功能模块。它通过对用户输入的SQL进行解析,并依据用户提供的脱敏配置对SQL进行改写,从而实现对原文数据进行加密,并将原文数据(可选)及密文数据同时存储到底层数据库。在用户查询数据时,它又从数据库中取出密文数据,并对其解密,最终将解密后的原始数据返回给用户。Apache ShardingSphere分布式数据库中间件自动化&透明化了数据脱敏过程,让用户无需关注数据脱敏的实现细节,像使用普通数据那样使用脱敏数据。此外,无论是已在线业务进行脱敏改造,还是新上线业务使用脱敏功能,ShardingSphere都可以提供一套相对完善的解决方案。
三、需求场景分析
对于数据脱敏的需求,在现实的业务场景中一般分为两种情况:
1、 新业务上线,安全部门规定需将涉及用户敏感信息,例如银行、手机号码等进行加密后存储到数据库,在使用的时候再进行解密处理因为是全新系统,因而没有存量数据清洗问题,所以实现相对简单;
2、 已上线业务,之前一直将明文存储在数据库中相关部门突然需要对已上线业务进行脱敏整改这种场景一般需要处理三个问题:;
a)历史数据需要如何进行脱敏处理,即洗数。
b)如何能在不改动业务SQL和逻辑情况下,将新增数据进行脱敏处理,并存储到数据库;在使用时,再进行解密取出。
c)如何较为安全、无缝、透明化地实现业务系统在明文与密文数据间的迁移。
四、处理流程详解
整体架构
ShardingSphere提供的Encrypt-JDBC和业务代码部署在一起。业务方需面向Encrypt-JDBC进行JDBC编程。由于Encrypt-JDBC实现所有JDBC标准接口,业务代码无需做额外改造即可兼容使用。此时,业务代码所有与数据库的交互行为交由Encrypt-JDBC负责。业务只需提供脱敏规则即可。作为业务代码与底层数据库中间的桥梁,Encrypt-JDBC便可拦截用户行为,并在改造行为后与数据库交互。
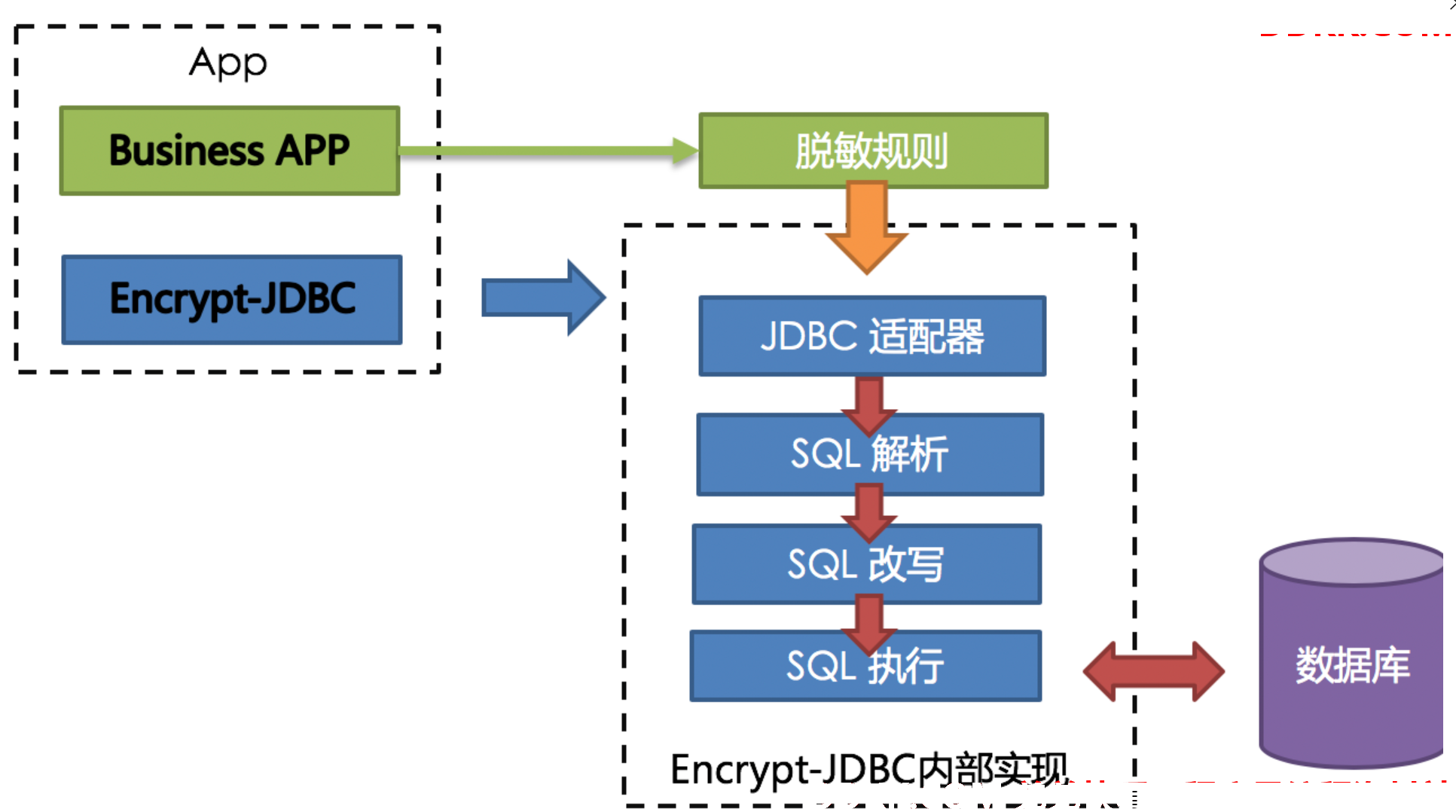
Encrypt-JDBC将用户发起的SQL进行拦截,并通过SQL语法解析器进行解析、理解SQL行为,再依据用户传入的脱敏规则,找出需要脱敏的字段和所使用的加解密器对目标字段进行加解密处理后,再与底层数据库进行交互。ShardingSphere会将用户请求的明文进行加密后存储到底层数据库;并在用户查询时,将密文从数据库中取出进行解密后返回给终端用户。ShardingSphere通过屏蔽对数据的脱敏处理,使用户无需感知解析SQL、数据加密、数据解密的处理过程,就像在使用普通数据一样使用脱敏数据。
脱敏规则
在详解整套流程之前,我们需要先了解下脱敏规则与配置,这是认识整套流程的基础。脱敏配置主要分为四部分:数据源配置,加密器配置,脱敏表配置以及查询属性配置,其详情如下图所示:
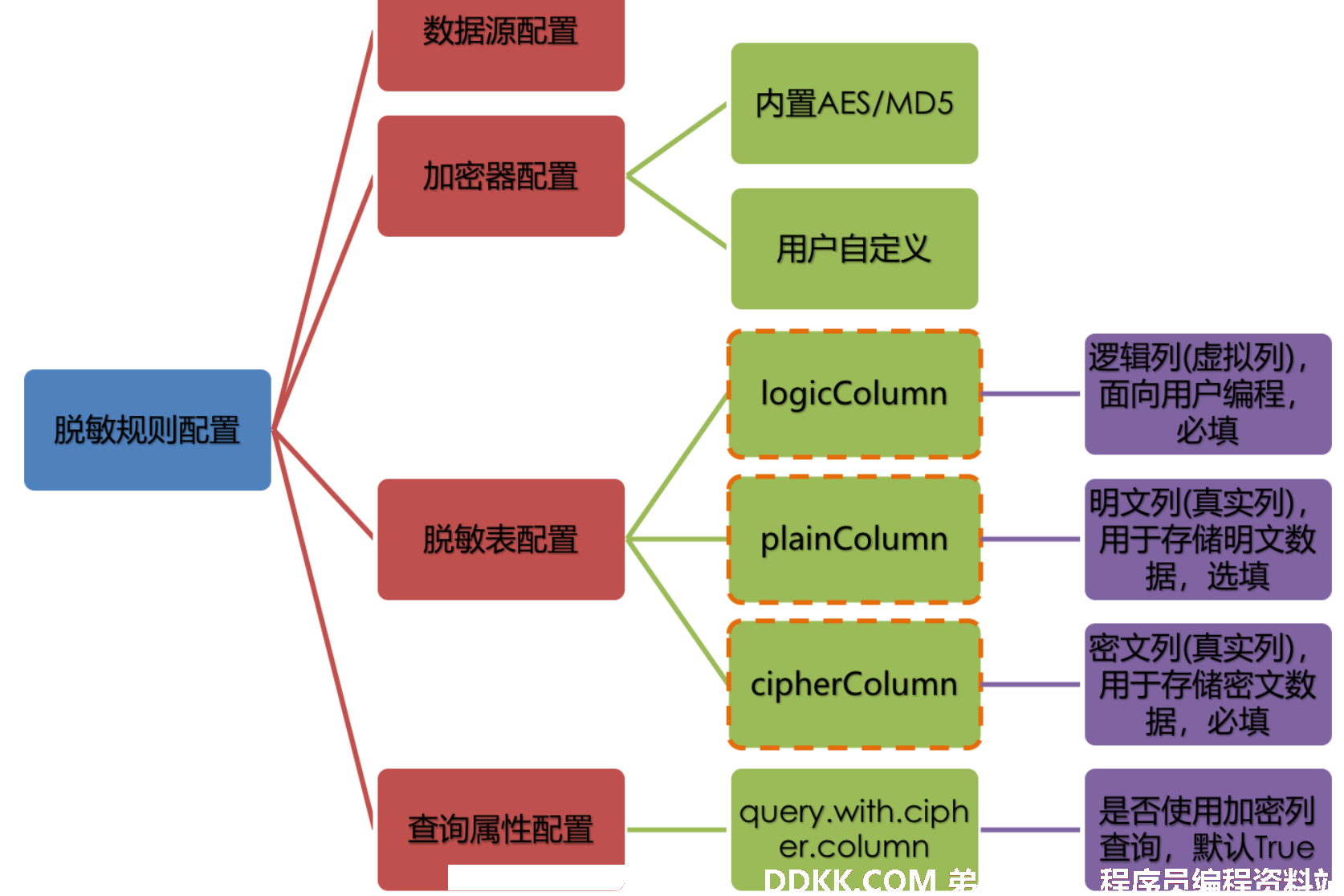
数据源配置:是指DataSource的配置。
加密器配置:是指使用什么加密策略进行加解密。目前ShardingSphere内置了两种加解密策略:AES/MD5。用户还可以通过实现ShardingSphere提供的接口,自行实现一套加解密算法。
脱敏表配置:用于告诉ShardingSphere数据表里哪个列用于存储密文数据(cipherColumn)、哪个列用于存储明文数据(plainColumn)以及用户想使用哪个列进行SQL编写(logicColumn)。
如何理解
用户想使用哪个列进行SQL编写(logicColumn)?我们可以从Encrypt-JDBC存在的意义来理解。Encrypt-JDBC最终目的是希望屏蔽底层对数据的脱敏处理,也就是说我们不希望用户知道数据是如何被加解密的、如何将明文数据存储到plainColumn,将密文数据存储到cipherColumn。换句话说,我们不希望用户知道plainColumn和cipherColumn的存在和使用。所以,我们需要给用户提供一个概念意义上的列,这个列可以脱离底层数据库的真实列,它可以是数据库表里的一个真实列,也可以不是,从而使得用户可以随意改变底层数据库的plainColumn和cipherColumn的列名。或者删除plainColumn,选择永远不再存储明文,只存储密文。只要用户的SQL面向这个逻辑列进行编写,并在脱敏规则里给出logicColumn和plainColumn、cipherColumn之间正确的映射关系即可。
为什么要这么做呢?答案在文章后面,即为了让已上线的业务能无缝、透明、安全地进行数据脱敏迁移。
查询属性的配置:当底层数据库表里同时存储了明文数据、密文数据后,该属性开关用于决定是直接查询数据库表里的明文数据进行返回,还是查询密文数据通过Encrypt-JDBC解密后返回。
脱敏处理过程
举个栗子,假如数据库里有一张表叫做t_user,这张表里实际有两个字段pwd_plain,用于存放明文数据、pwd_cipher,用于存放密文数据,同时定义logicColumn为pwd。那么,用户在编写SQL时应该面向logicColumn进行编写,即INSERT INTO t_user SET pwd = ‘123’。ShardingSphere接收到该SQL,通过用户提供的脱敏配置,发现pwd是logicColumn,于是便对逻辑列及其对应的明文数据进行脱敏处理。可以看出**ShardingSphere将面向用户的逻辑列与面向底层数据库的明文列和密文列进行了列名以及数据的脱敏映射转换。**如下图所示:
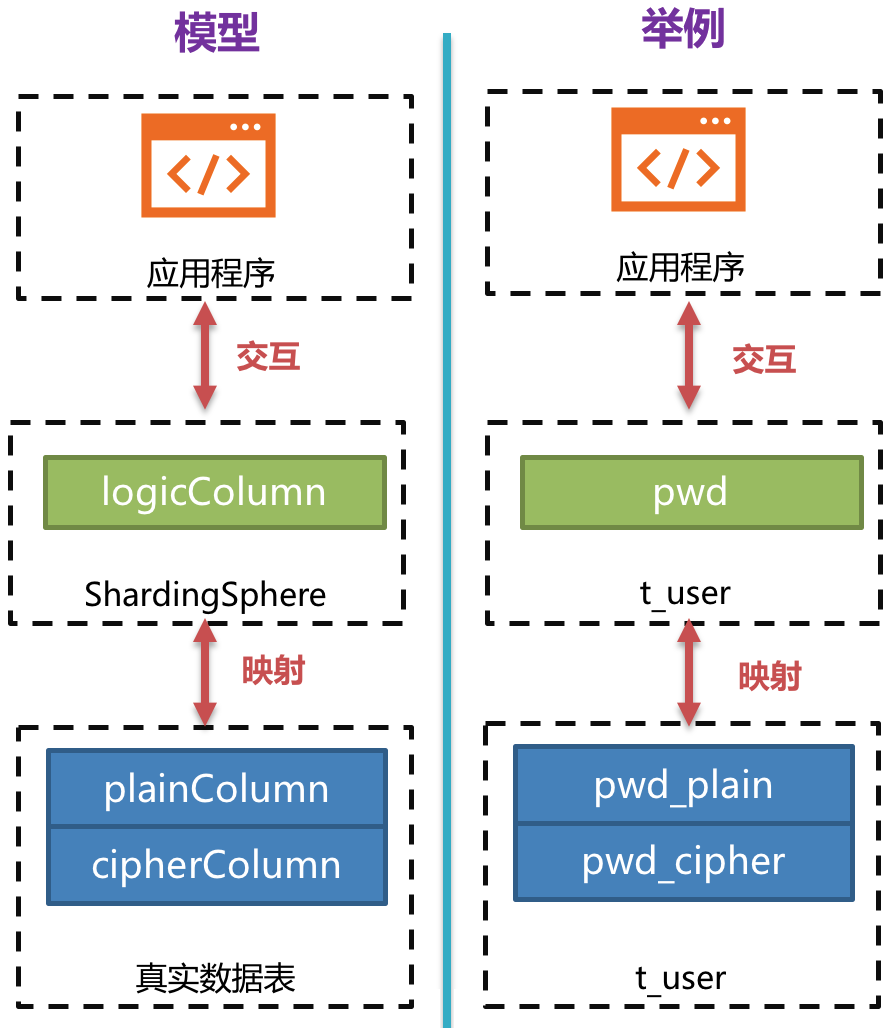 ]
]**这也正是Encrypt-JDBC核心意义所在,即依据用户提供的脱敏规则,将用户SQL与底层数据表结构割裂开来,使得用户的SQL编写不再依赖于真实的数据库表结构。而用户与底层数据库之间的衔接、映射、转换交由ShardingSphere进行处理。**为什么我们要这么做?还是那句话:为了让已上线的业务能无缝、透明、安全地进行数据脱敏迁移。
为了让读者更清晰了解到Encrypt-JDBC的核心处理流程,下方图片展示了使用Encrypt-JDBC进行增删改查时,其中的处理流程和转换逻辑,如下图所示。
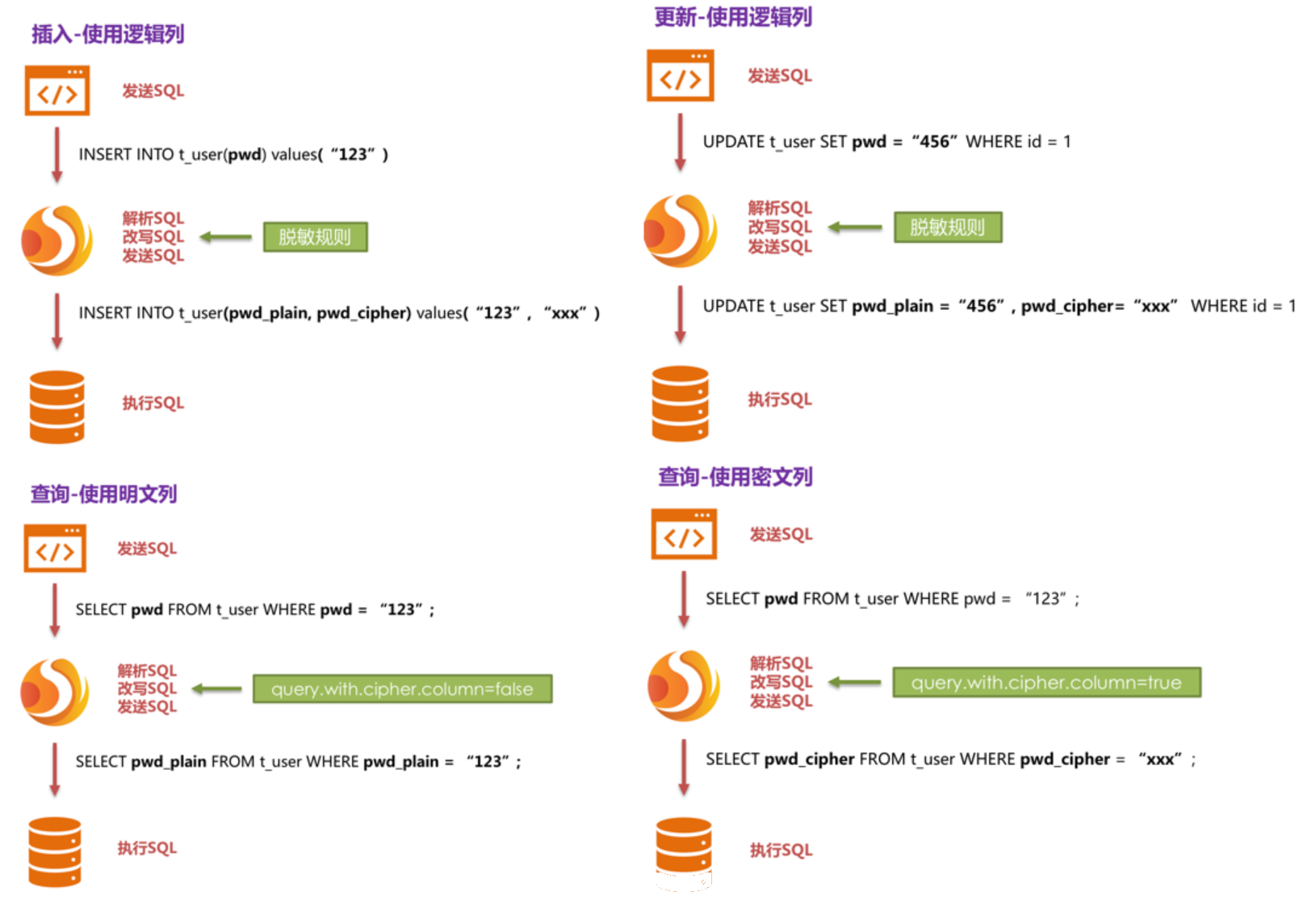
五、解决方案详解
在了解了ShardingSphere脱敏处理流程后,即可将脱敏配置、脱敏处理流程与实际场景进行结合。所有的设计开发都是为了解决业务场景遇到的痛点。那么面对之前提到的业务场景需求,又应该如何使用ShardingSphere这把利器来满足业务需求呢?
新上线业务
业务场景分析:新上线业务由于一切从零开始,不存在历史数据清洗问题,所以相对简单。
解决方案说明:选择合适的加密器,如AES后,只需配置逻辑列(面向用户编写SQL)和密文列(数据表存密文数据)即可,逻辑列和密文列可以相同也可以不同。建议配置如下(Yaml格式展示):
encryptRule:
encryptors:
aes_encryptor:
type: aes
props:
aes.key.value: 123456abc
tables:
t_user:
columns:
pwd:
cipherColumn: pwd
encryptor: aes_encryptor
使用这套配置,Encrypt-JDBC只需将logicColumn和cipherColumn进行转换,底层数据表不存储明文,只存储了密文,这也是安全审计部分的要求所在。如果用户希望将明文、密文一同存储到数据库,只需添加plainColumn配置即可。整体处理流程如下图所示:

已上线业务改造
业务场景分析:由于业务已经在线上运行,数据库里必然存有大量明文历史数据。现在的问题是如何让历史数据得以加密清洗、如何让增量数据得以加密处理、如何让业务在新旧两套数据系统之间进行无缝、透明化迁移。
解决方案说明:在提供解决方案之前,我们先来头脑风暴一下:首先,既然是旧业务需要进行脱敏改造,那一定存储了非常重要且敏感的信息。这些信息含金量高且业务相对基础重要。如果搞错了,整个团队KPI就再见了。所以不可能一上来就停业务,禁止新数据写入,再找个加密器把历史数据全部加密清洗,再把之前重构的代码部署上线,使其能把存量和增量数据进行在线加密解密。如此简单粗暴的方式,按照历史经验来谈,一定凉凉。
那么另一种相对安全的做法是:重新搭建一套和生产环境一模一样的预发环境,然后通过相关迁移洗数工具把生产环境的存量原文数据加密后存储到预发环境,而新增数据则通过例如MySQL主从复制及业务方自行开发的工具加密后存储到预发环境的数据库里,再把重构后可以进行加解密的代码部署到预发环境。这样生产环境是一套以明文为核心的查询修改的环境;预发环境是一套以密文为核心加解密查询修改的环境。在对比一段时间无误后,可以夜间操作将生产流量切到预发环境中。此方案相对安全可靠,只是时间、人力、资金、成本较高,主要包括:预发环境搭建、生产代码整改、相关辅助工具开发等。除非无路可走,否则业务开发人员一般是从入门到放弃。
业务开发人员最希望的做法是:减少资金费用的承担、最好不要修改业务代码、能够安全平滑迁移系统。于是,ShardingSphere的脱敏功能模块便应用而生。可分为三步进行:
1、 系统迁移前;
假设系统需要对t_user的pwd字段进行脱敏处理,业务方使用Encrypt-JDBC来代替标准化的JDBC接口,此举基本不需要额外改造(我们还提供了SpringBoot,SpringNameSpace,Yaml等接入方式,满足不同业务方需求)。另外,提供一套脱敏配置规则,如下所示:
encryptRule:
encryptors:
aes_encryptor:
type: aes
props:
aes.key.value: 123456abc
tables:
t_user:
columns:
pwd:
plainColumn: pwd
cipherColumn: pwd_cipher
encryptor: aes_encryptor
props:
query.with.cipher.column: false
依据上述脱敏规则可知,首先需要在数据库表t_user里新增一个字段叫做pwd_cipher,即cipherColumn,用于存放密文数据,同时我们把plainColumn设置为pwd,用于存放明文数据,而把logicColumn也设置为pwd。由于之前的代码SQL就是使用pwd进行编写,即面向逻辑列进行SQL编写,所以业务代码无需改动。通过Encrypt-JDBC,针对新增的数据,会把明文写到pwd列,并同时把明文进行加密存储到pwd_cipher列。此时,由于query.with.cipher.column设置为false,对业务应用来说,依旧使用pwd这一明文列进行查询存储,却在底层数据库表pwd_cipher上额外存储了新增数据的密文数据,其处理流程如下图所示:
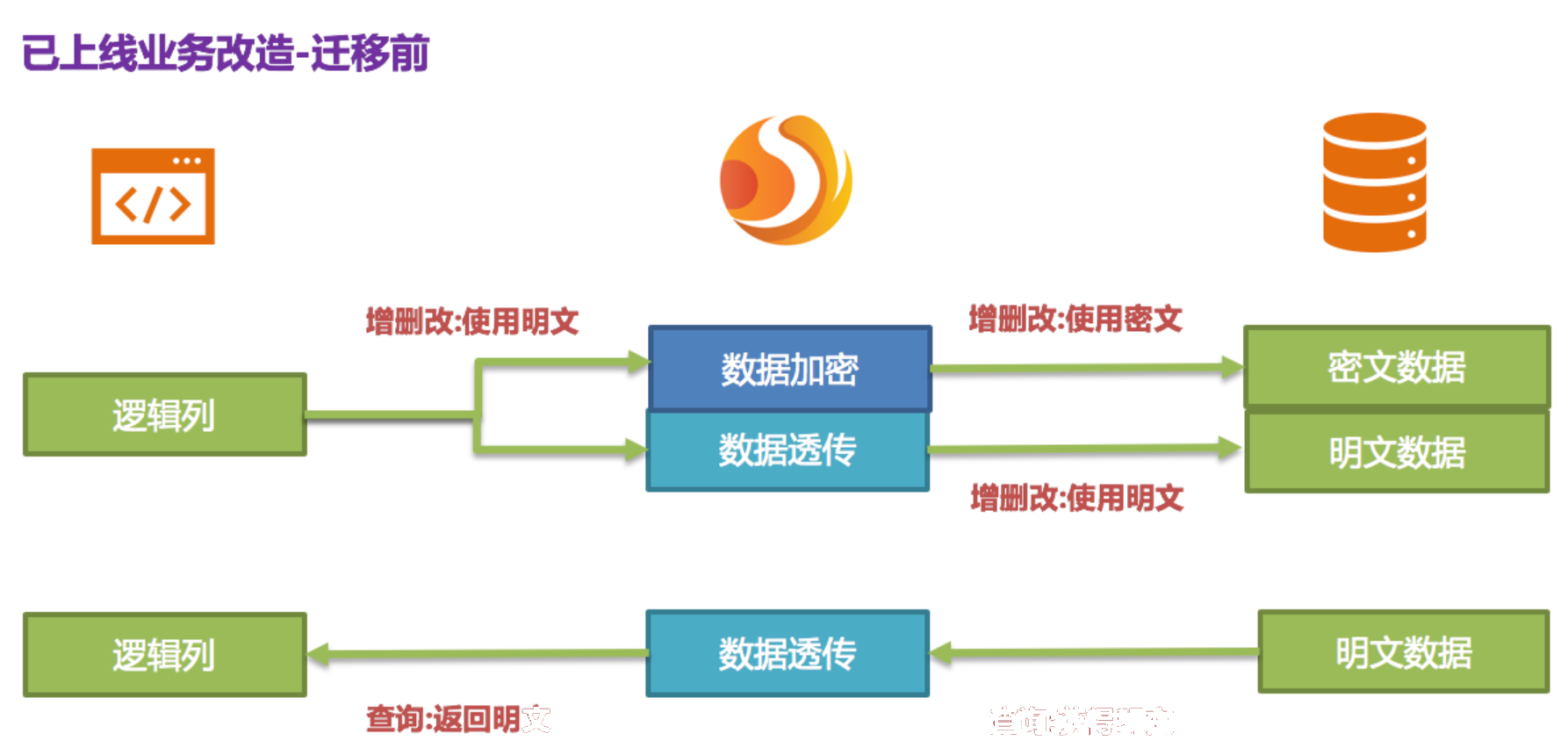
新增数据在插入时,就通过Encrypt-JDBC加密为密文数据,并被存储到了cipherColumn。而现在就需要处理历史明文存量数据。由于Apache ShardingSphere目前并未提供相关迁移洗数工具,此时需要业务方自行将pwd中的明文数据进行加密处理存储到pwd_cipher。
1、 系统迁移中;
新增的数据已被Encrypt-JDBC将密文存储到密文列,明文存储到明文列;历史数据被业务方自行加密清洗后,将密文也存储到密文列。也就是说现在的数据库里即存放着明文也存放着密文,只是由于配置项中的query.with.cipher.column=false,所以密文一直没有被使用过。现在我们为了让系统能切到密文数据进行查询,需要将脱敏配置中的query.with.cipher.column设置为true。在重启系统后,我们发现系统业务一切正常,但是Encrypt-JDBC已经开始从数据库里取出密文列的数据,解密后返回给用户;而对于用户的增删改需求,则依旧会把原文数据存储到明文列,加密后密文数据存储到密文列。
虽然现在业务系统通过将密文列的数据取出,解密后返回;但是,在存储的时候仍旧会存一份原文数据到明文列,这是为什么呢?答案是:为了能够进行系统回滚。**因为只要密文和明文永远同时存在,我们就可以通过开关项配置自由将业务查询切换到cipherColumn或plainColumn。**也就是说,如果将系统切到密文列进行查询时,发现系统报错,需要回滚。那么只需将query.with.cipher.column=false,Encrypt-JDBC将会还原,即又重新开始使用plainColumn进行查询。处理流程如下图所示:
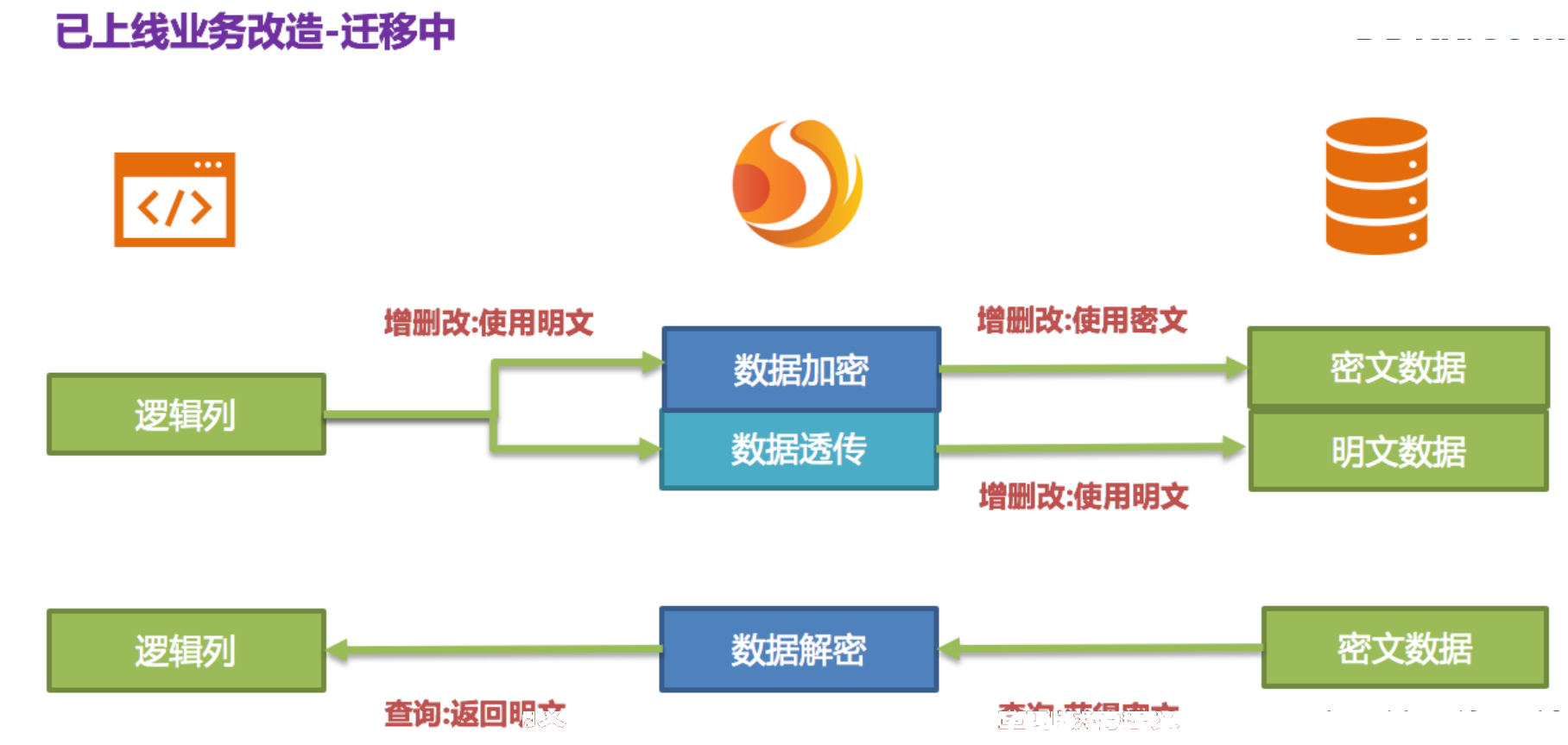
1、 系统迁移后;
由于安全审计部门要求,业务系统一般不可能让数据库的明文列和密文列永久同步保留,我们需要在系统稳定后将明文列数据删除。即我们需要在系统迁移后将plainColumn,即pwd进行删除。那问题来了,现在业务代码都是面向pwd进行编写SQL的,把底层数据表中的存放明文的pwd删除了,换用pwd_cipher进行解密得到原文数据,那岂不是意味着业务方需要整改所有SQL,从而不使用即将要被删除的pwd列?还记得我们Encrypt-JDBC的核心意义所在吗?
这也正是Encrypt-JDBC核心意义所在,即依据用户提供的脱敏规则,将用户SQL与底层数据库表结构割裂开来,使得用户的SQL编写不再依赖于真实的数据库表结构。而用户与底层数据库之间的衔接、映射、转换交由ShardingSphere进行处理。
是的,因为有logicColumn存在,用户的编写SQL都面向这个虚拟列,Encrypt-JDBC就可以把这个逻辑列和底层数据表中的密文列进行映射转换。于是迁移后的脱敏配置即为:
encryptRule:
encryptors:
aes_encryptor:
type: aes
props:
aes.key.value: 123456abc
tables:
t_user:
columns:
pwd: pwd与pwd_cipher的转换映射
cipherColumn: pwd_cipher
encryptor: aes_encryptor
props:
query.with.cipher.column: true
其处理流程如下:
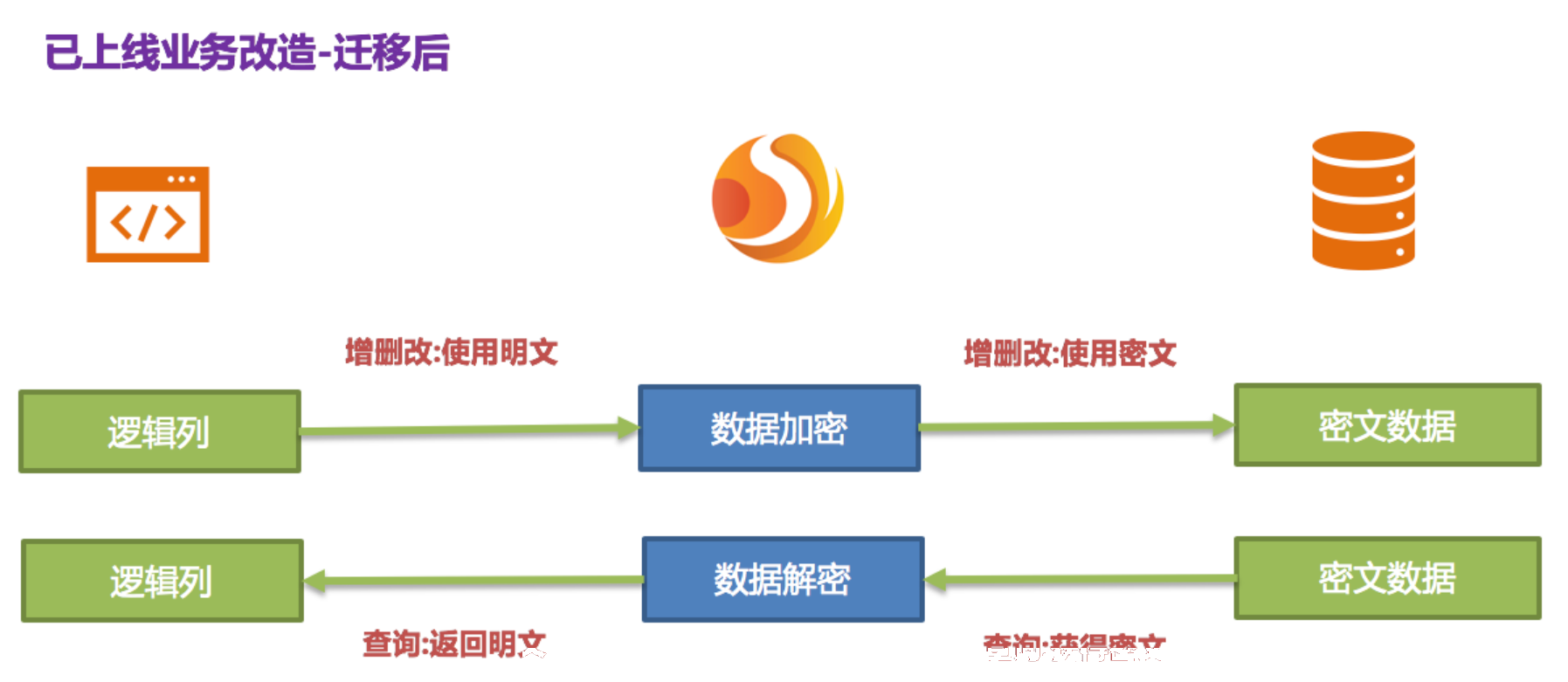
至此,已在线业务脱敏整改解决方案全部叙述完毕。我们提供了Java、Yaml、SpringBoot、SpringNameSpace多种方式供用户选择接入,力求满足业务不同的接入需求。该解决方案目前已在京东数科不断落地上线,提供对内基础服务支撑。
六、中间件脱敏服务优势
1、 自动化&透明化数据脱敏过程,用户无需关注脱敏中间实现细节;
2、 提供多种内置、第三方(AKS)的脱敏策略,用户仅需简单配置即可使用;
3、 提供脱敏策略API接口,用户可实现接口,从而使用自定义脱敏策略进行数据脱敏;
4、 支持切换不同的脱敏策略;
5、 针对已上线业务,可实现明文数据与密文数据同步存储,并通过配置决定使用明文列还是密文列进行查询可实现在不改变业务查询SQL前提下,已上线系统对加密前后数据进行安全、透明化迁移;
七、适用场景说明
1、 用户项目使用Java语言进行编程;
2、 后端数据库为MySQL、Oracle、PostgreSQL、SQLServer;
3、 用户需要对数据库表中某个或多个列进行脱敏(数据加密&解密);
4、 兼容所有常用SQL;
八、限制条件
1、 用户需要自行处理数据库中原始的存量数据、洗数;
2、 使用脱敏功能+分库分表功能,部分特殊SQL不支持,请参考SQL使用规范;
3、 脱敏字段无法支持比较操作,如:大于小于、ORDERBY、BETWEEN、LIKE等;
4、 脱敏字段无法支持计算操作,如:AVG、SUM以及计算表达式;
九、加密策略解析
ShardingSphere提供了两种加密策略用于数据脱敏,该两种策略分别对应ShardingSphere的两种加解密的接口,即ShardingEncryptor和ShardingQueryAssistedEncryptor。
一方面,ShardingSphere为用户提供了内置的加解密实现类,用户只需进行配置即可使用;另一方面,为了满足用户不同场景的需求,我们还开放了相关加解密接口,用户可依据该两种类型的接口提供具体实现类。再进行简单配置,即可让ShardingSphere调用用户自定义的加解密方案进行数据脱敏。
ShardingEncryptor
该解决方案通过提供encrypt(), decrypt()两种方法对需要脱敏的数据进行加解密。在用户进行INSERT, DELETE, UPDATE时,ShardingSphere会按照用户配置,对SQL进行解析、改写、路由,并会调用encrypt()将数据加密后存储到数据库, 而在SELECT时,则调用decrypt()方法将从数据库中取出的脱敏数据进行逆向解密,最终将原始数据返回给用户。
当前,ShardingSphere针对这种类型的脱敏解决方案提供了两种具体实现类,分别是MD5(不可逆),AES(可逆),用户只需配置即可使用这两种内置的方案。
ShardingQueryAssistedEncryptor
相比较于第一种脱敏方案,该方案更为安全和复杂。它的理念是:即使是相同的数据,如两个用户的密码相同,它们在数据库里存储的脱敏数据也应当是不一样的。这种理念更有利于保护用户信息,防止撞库成功。
它提供三种函数进行实现,分别是encrypt(), decrypt(), queryAssistedEncrypt()。在encrypt()阶段,用户通过设置某个变动种子,例如时间戳。针对原始数据+变动种子组合的内容进行加密,就能保证即使原始数据相同,也因为有变动种子的存在,致使加密后的脱敏数据是不一样的。在decrypt()可依据之前规定的加密算法,利用种子数据进行解密。
虽然这种方式确实可以增加数据的保密性,但是另一个问题却随之出现:相同的数据在数据库里存储的内容是不一样的,那么当用户按照这个加密列进行等值查询(SELECT FROM table WHERE encryptedColumnn = ?)时会发现无法将所有相同的原始数据查询出来。为此,我们提出了辅助查询列的概念。该辅助查询列通过queryAssistedEncrypt()生成,与decrypt()不同的是,该方法通过对原始数据进行另一种方式的加密,但是针对原始数据相同的数据,这种加密方式产生的加密数据是一致的。将queryAssistedEncrypt()后的数据存储到数据中用于辅助查询真实数据。因此,数据库表中多出这一个辅助查询列。
由于queryAssistedEncrypt()和encrypt()产生不同加密数据进行存储,而decrypt()可逆,queryAssistedEncrypt()不可逆。 在查询原始数据的时候,我们会自动对SQL进行解析、改写、路由,利用辅助查询列进行 WHERE条件的查询,却利用 decrypt()对encrypt()加密后的数据进行解密,并将原始数据返回给用户。这一切都是对用户透明化的。
当前,ShardingSphere针对这种类型的脱敏解决方案并没有提供具体实现类,却将该理念抽象成接口,提供给用户自行实现。ShardingSphere将调用用户提供的该方案的具体实现类进行数据脱敏。
十、后续
本篇文章介绍了如何使用ShardingSphere产品之一的Encrypt-JDBC进行接入,接入形式还可以选择使用SpringBoot、SpringNameSpace等,这种形态的接入端主要面向JAVA同构,并与业务代码共同部署在生产环境中。面向异构语言,ShardingSphere还提供Encrypt-Proxy客户端。Encrypt-Proxy是一款实现MySQL、PostgreSQL的二进制协议的服务器端产品,用户可独立部署Encrypt-Proxy服务,并且像使用普通MySQL、PostgreSQL数据库一样,使用例如Navicat第三方数据库管理工具、JAVA连接池、命令行的方式访问这台具有脱敏功能的虚拟数据库服务器。
脱敏功能属于Apache ShardingSphere分布式治理的功能范畴。事实上,Apache ShardingSphere这个生态还拥有其他更强大的能力,例如数据分片、读写分离、分布式事务、监控治理等。您甚至可以选择任意多种功能模块进行叠加使用,例如同时使用数据脱敏+数据分片,或是数据分片+读写分离,再或者是监控治理+数据分片等。除了在功能层面的叠加选择,ShardingSphere还提供了各种接入端形式,例如Sharding-JDBC或Sharding-Proxy等以满足大家不同场景需求。