03、ShardingSphere 实战:数据分片-内核剖析(三)
核心剖析
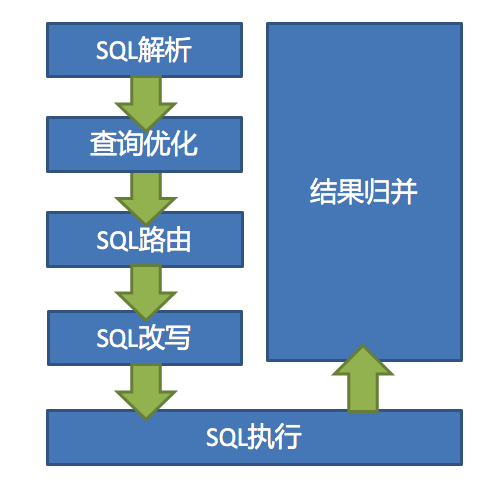
ShardingSphere的3个产品的数据分片主要流程是完全一致的。 核心由SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成。
SQL解析
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
执行器优化
合并和优化分片条件,如OR等。
SQL路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
SQL改写
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
SQL执行
通过多线程执行器异步执行。
结果归并
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
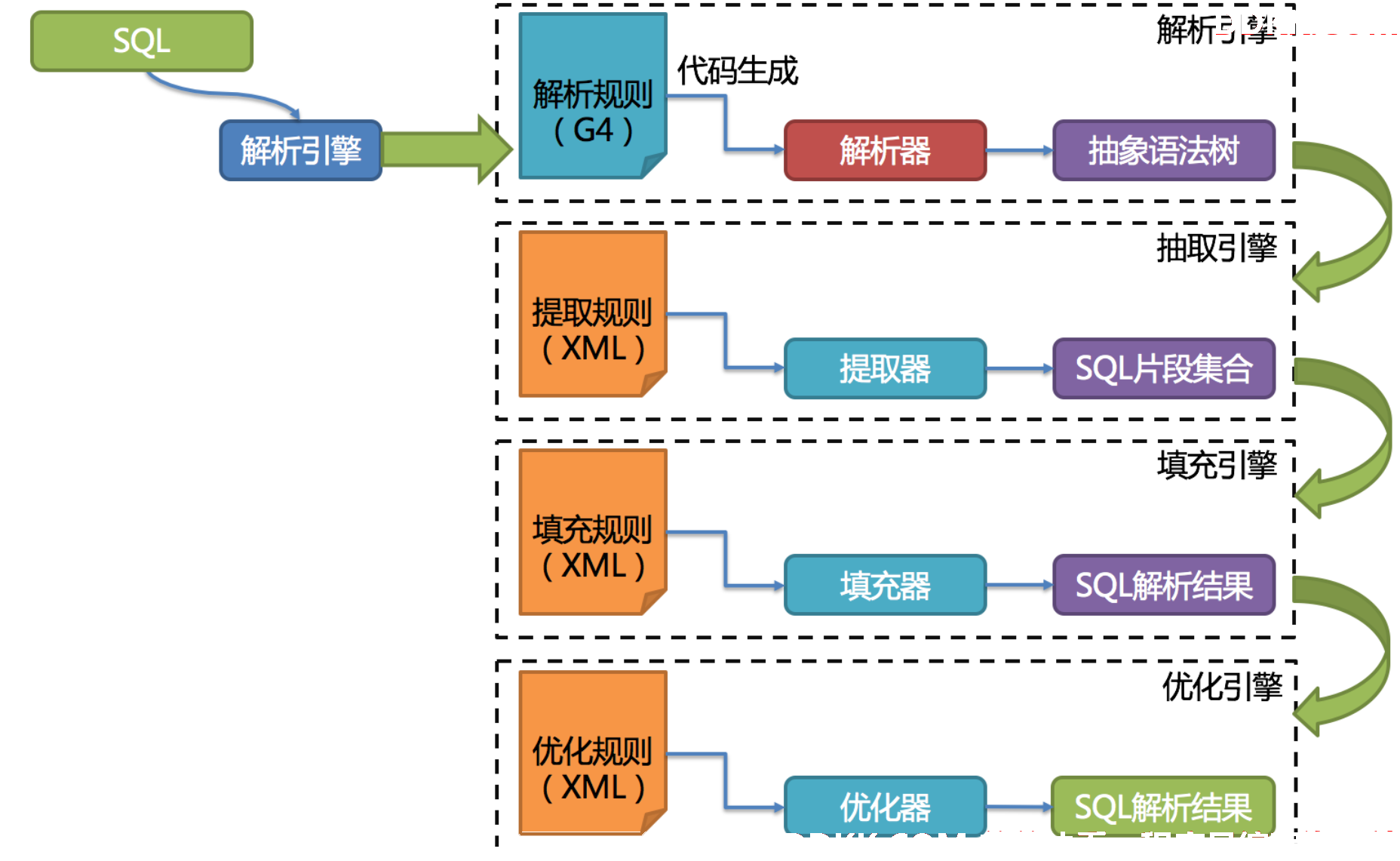
解析引擎
相对于其他编程语言,SQL是比较简单的。 不过,它依然是一门完善的编程语言,因此对SQL的语法进行解析,与解析其他编程语言(如:Java语言、C语言、Go语言等)并无本质区别。
抽象语法树
解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树。
例如,以下SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析之后的为抽象语法树见下图。
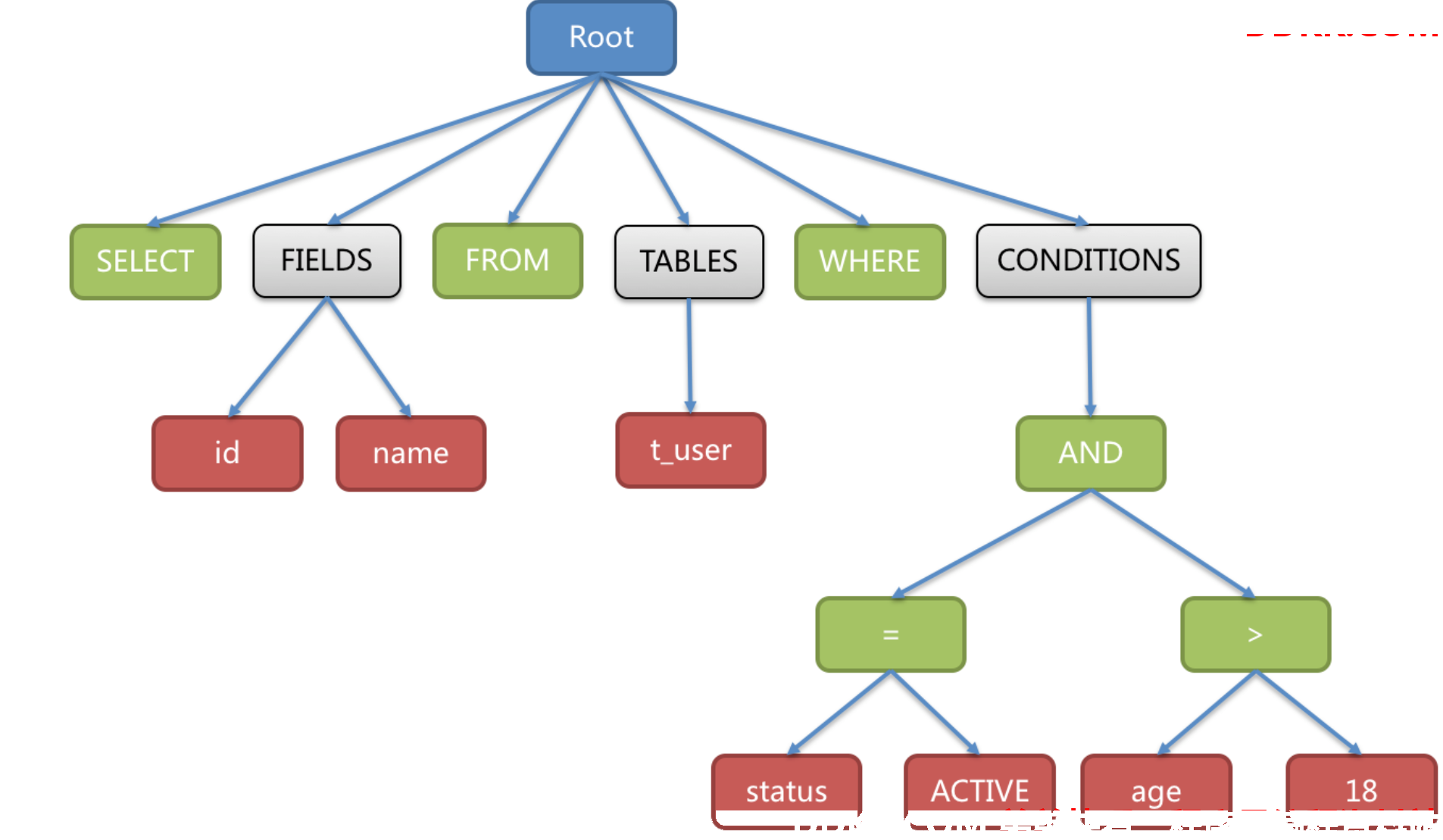
为了便于理解,抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分。
最后,通过对抽象语法树的遍历去提炼分片所需的上下文,并标记有可能需要改写的位置。 供分片使用的解析上下文包含查询选择项(Select Items)、表信息(Table)、分片条件(Sharding Condition)、自增主键信息(Auto increment Primary Key)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit、Rownum、Top)。 SQL的一次解析过程是不可逆的,一个个Token的按SQL原本的顺序依次进行解析,性能很高。 考虑到各种数据库SQL方言的异同,在解析模块提供了各类数据库的SQL方言字典。
SQL解析引擎
SQL解析作为分库分表类产品的核心,其性能和兼容性是最重要的衡量指标。 ShardingSphere的SQL解析器经历了3代产品的更新迭代。
第一代SQL解析器为了追求性能与快速实现,在1.4.x之前的版本使用Druid作为SQL解析器。经实际测试,它的性能远超其它解析器。
Druid SQL Parser的使用场景
- MySql SQL全量统计
- Hive/ODPS SQL执行安全审计
- 分库分表SQL解析引擎
- 数据库引擎的SQL Parser
- 参考:https://github.com/alibaba/druid/wiki/SQL-Parser
第二代SQL解析器从1.5.x版本开始,ShardingSphere采用完全自研的SQL解析引擎。 由于目的不同,ShardingSphere并不需要将SQL转为一颗完全的抽象语法树,也无需通过访问器模式进行二次遍历。它采用对SQL半理解的方式,仅提炼数据分片需要关注的上下文,因此SQL解析的性能和兼容性得到了进一步的提高。
第三代SQL解析器则从3.0.x版本开始,ShardingSphere尝试使用ANTLR作为SQL解析的引擎,并计划根据DDL -> TCL -> DAL –> DCL -> DML –>DQL这个顺序,依次替换原有的解析引擎,目前仍处于替换迭代中。 使用ANTLR的原因是希望ShardingSphere的解析引擎能够更好的对SQL进行兼容。对于复杂的表达式、递归、子查询等语句,虽然ShardingSphere的分片核心并不关注,但是会影响对于SQL理解的友好度。 经过实例测试,ANTLR解析SQL的性能比自研的SQL解析引擎慢3-10倍左右。为了弥补这一差距,ShardingSphere将使用PreparedStatement的SQL解析的语法树放入缓存。 因此建议采用PreparedStatement这种SQL预编译的方式提升性能。
Antlr是一款强大的生成"语法解析器"的工具,可以用作读取、处理、执行或翻译结构化文本或二进制文件。广泛的用来构建新的语言、工具和框架。这个"语法解析器"创建和遍历语法树。
eg:Hive和Spark使用antlr生成词法语法解析器、Twitter使用antlr来解析用户输入的查询内容,Oracle把antlr的功能内嵌在SQL 开发IDE中,NetBeans IDE使用antlr解析C++语言,也有公司使用antlr来从文件中抽取信息
Spark2.x SQL语句的解析采用的是ANTLR 4,ANTLR 4根据spark-2.1.1\sql\catalyst\src\main\antlr4\org\apache\spark\sql\catalyst\parser\SqlBase.g4文件自动解析生成的Java类:词法解析器SqlBaseLexer和语法解析器SqlBaseParser。
SqlBaseLexer和SqlBaseParser均是使用ANTLR 4自动生成的Java类。使用这两个解析器将SQL语句解析成了ANTLR 4的语法树结构ParseTree。然后在parsePlan中,使用AstBuilder(AstBuilder.scala)将ANTLR 4语法树结构转换成catalyst表达式逻辑计划logical plan。
第三代SQL解析引擎的整体结构划分如下图所示。