06、ElasticSearch 实战:es的多种搜索方式
演示前先往es写入两条商品数据,接下来用各种查询方式来演示
PUT /product/book/1
{
"product_name": "yuwen shu",
"price": 20,
"tags": ["boring","bad"]
}
PUT /product/book/2
{
"product_name": "shuxue shu",
"price": 10,
"tags": ["interest","good"]
}
1、query string search
#查询所有商品
GET /product/book/_search
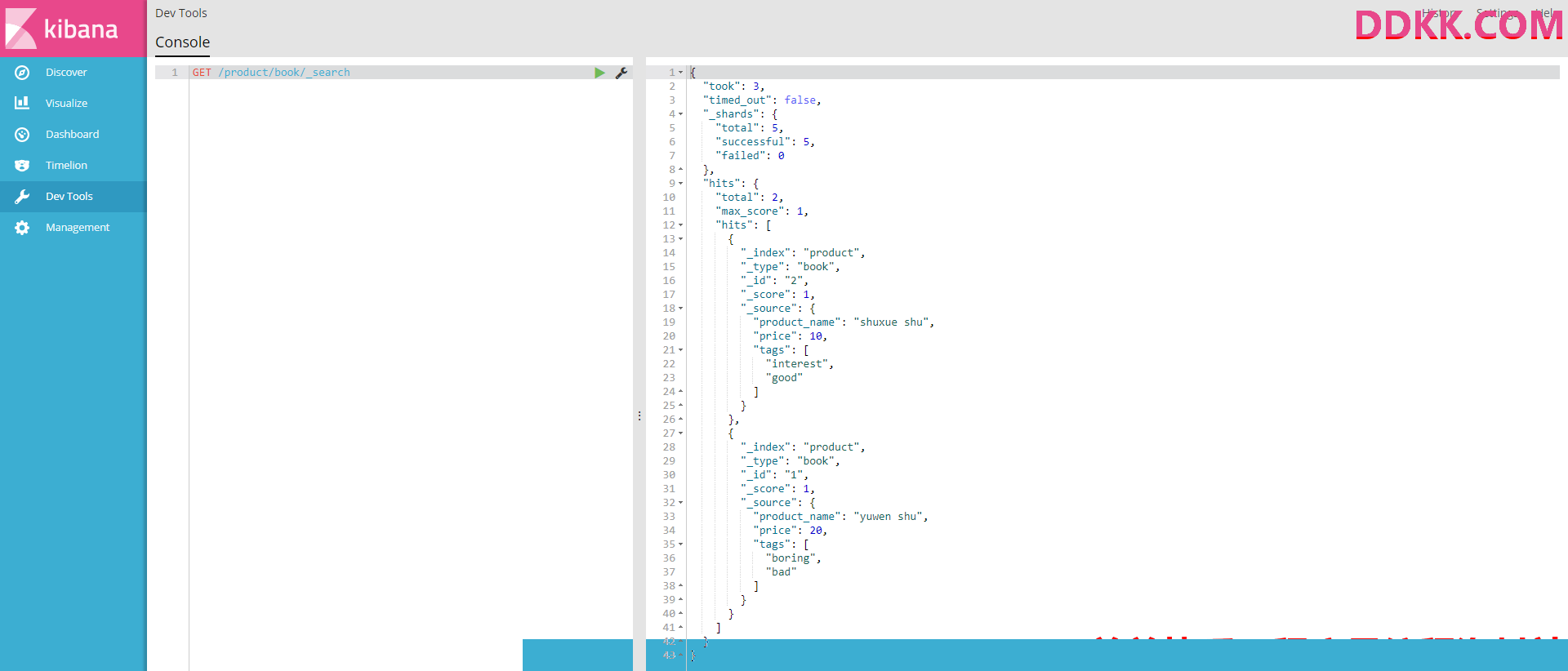
返回参数解释一下:
took:1 耗费了3毫秒
time_out:false 没有超时
_shards.total:5 请求打到了5个shard(primary shard或replica shard)上拿数据
_shards.successful:5 5个请求成功的shard
_shards.failed:0 0个请求失败的shard
hits.total:2 查询到2个document
hits.hits._score:1 在这次搜索中这个document的相关度匹配分数为1,越相关就越匹配分数就越高
hits.hits._source document数据
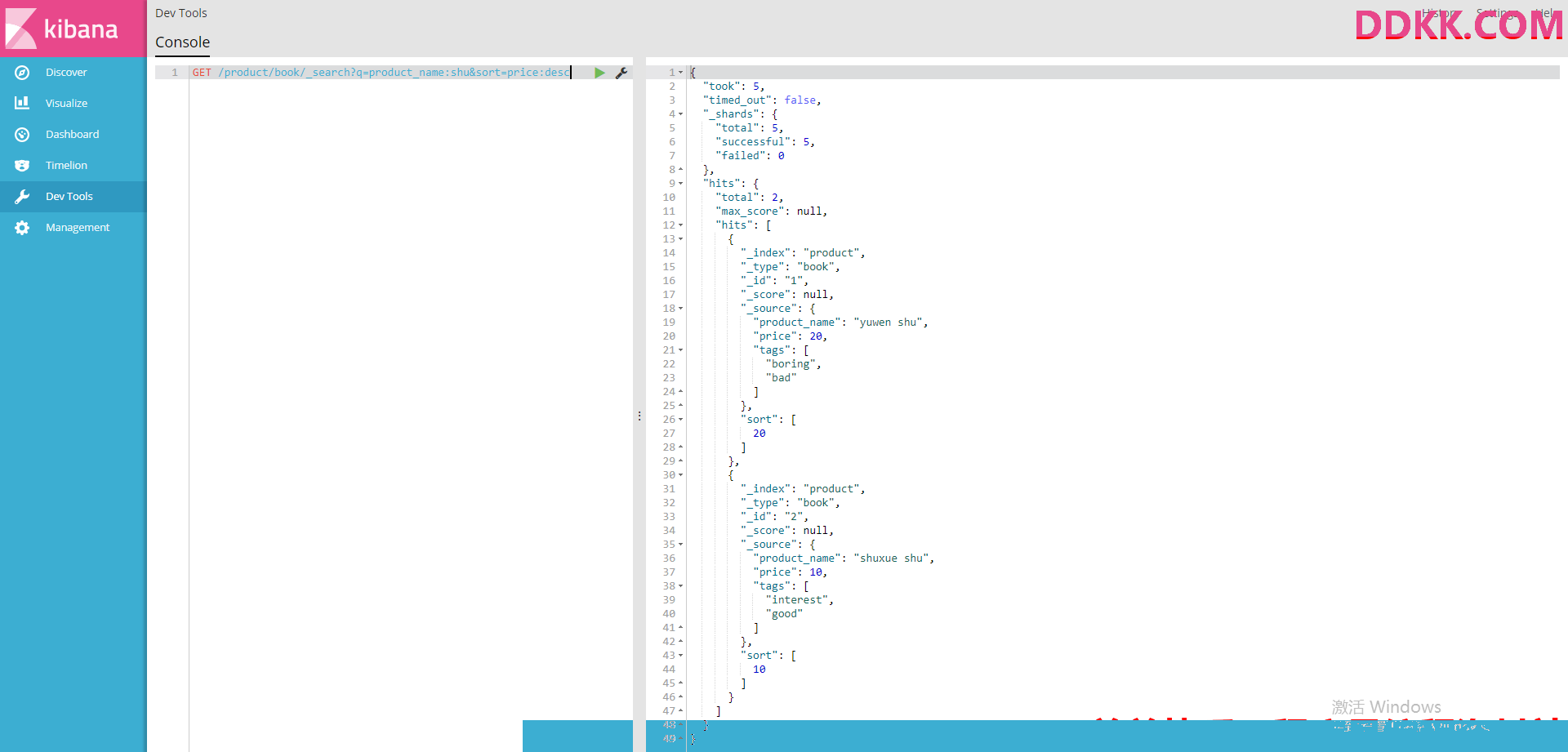
#带条件时,类似http的get方法,把条件拼在请求后面
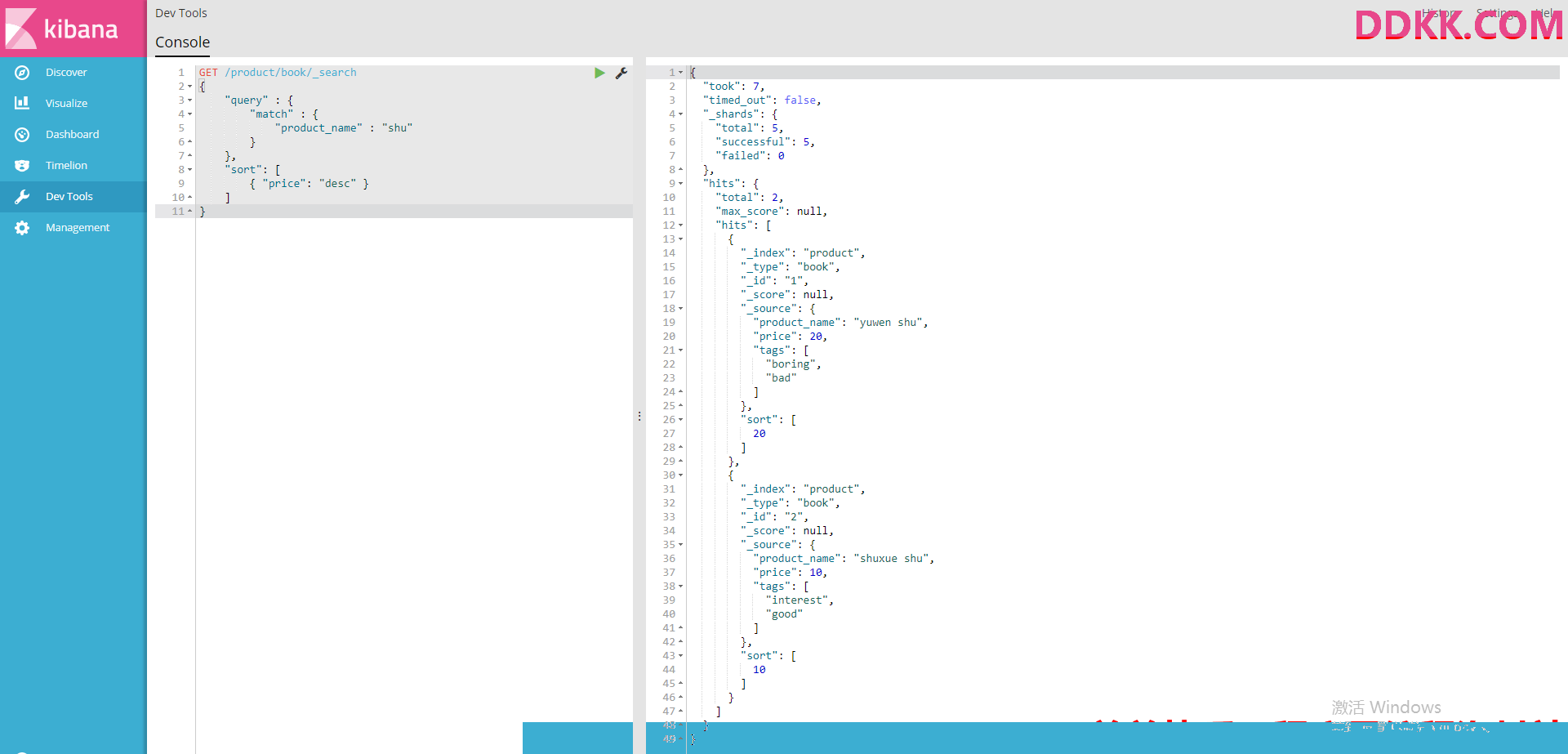
#搜索商品名称中包含shu的商品,按照售价降序排序
GET /product/book/_search?q=product_name:shu&sort=price:desc
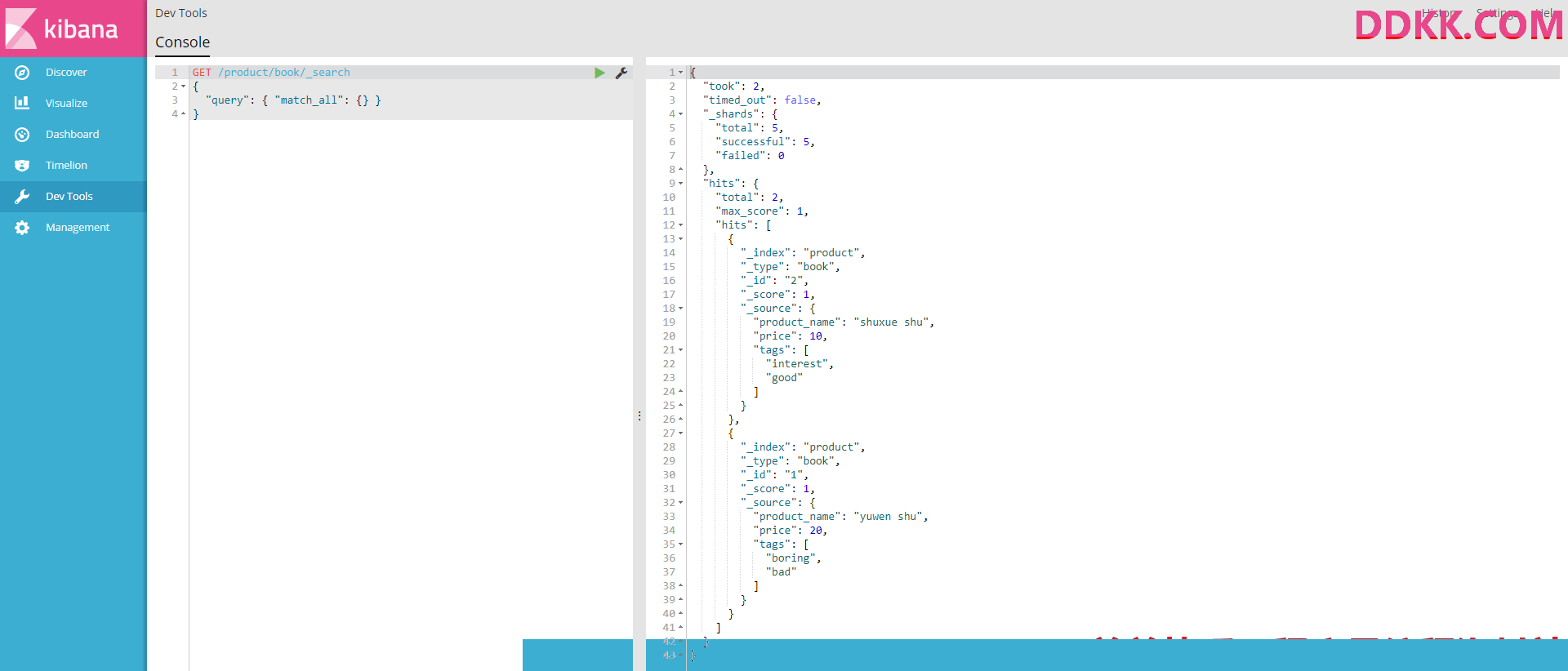
2、query DSL
用json来组装查询条件,可以构建各种复杂的语法,比query string search强大很多
#查询所有商品
GET /product/book/_search
{
"query": { "match_all": {} }
}
#查询商品名称包含shu的商品,按照价格降序排序
GET /product/book/_search
{
"query" : {
"match" : {
"product_name" : "shu"
}
},
"sort": [
{ "price": "desc" }
]
}
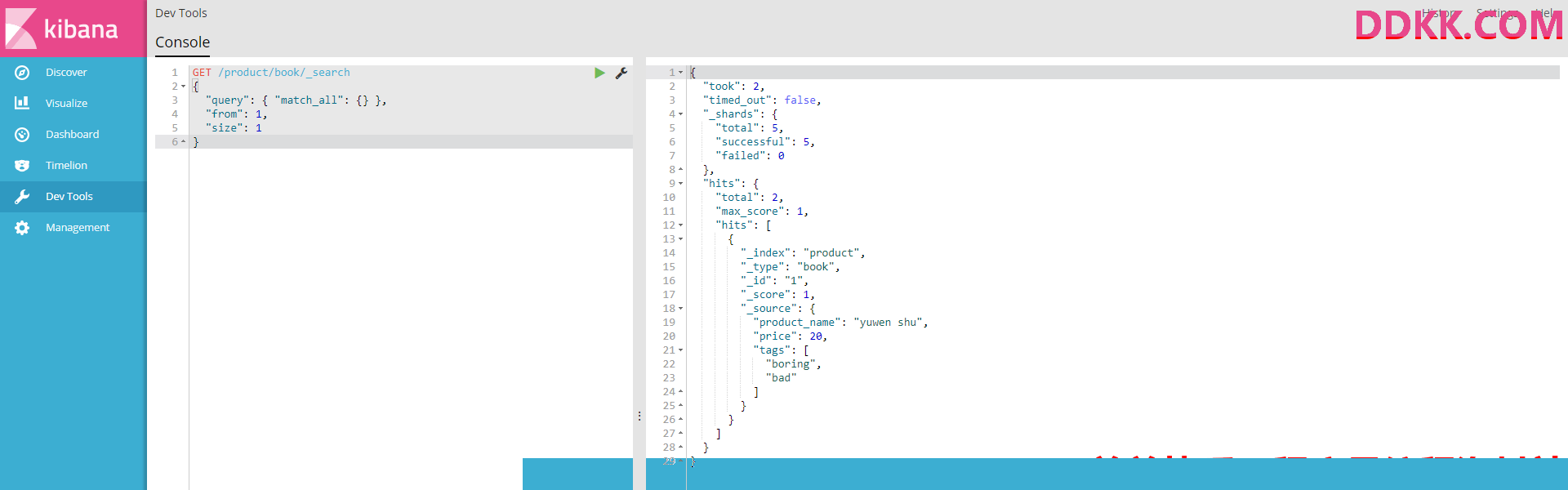
#分页查询商品,每页1条数据,查第2页
GET /product/book/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
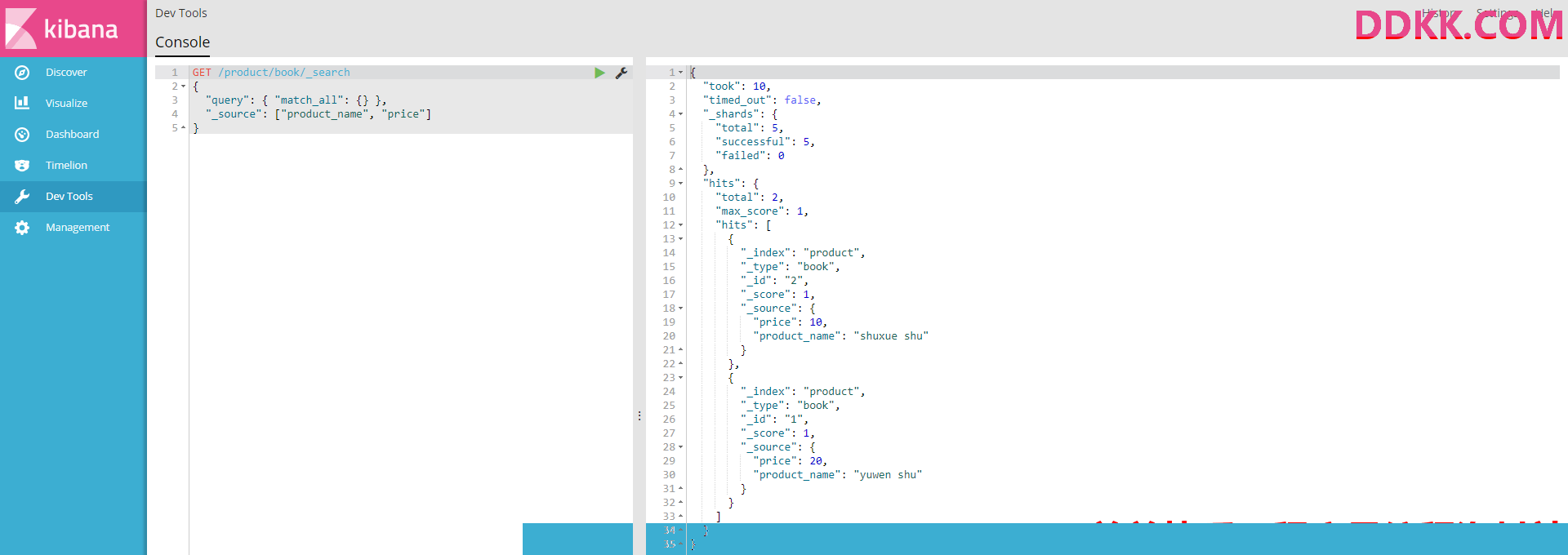
#指定查询结果只要商品名称和价格两个字段
GET /product/book/_search
{
"query": { "match_all": {} },
"_source": ["product_name", "price"]
}
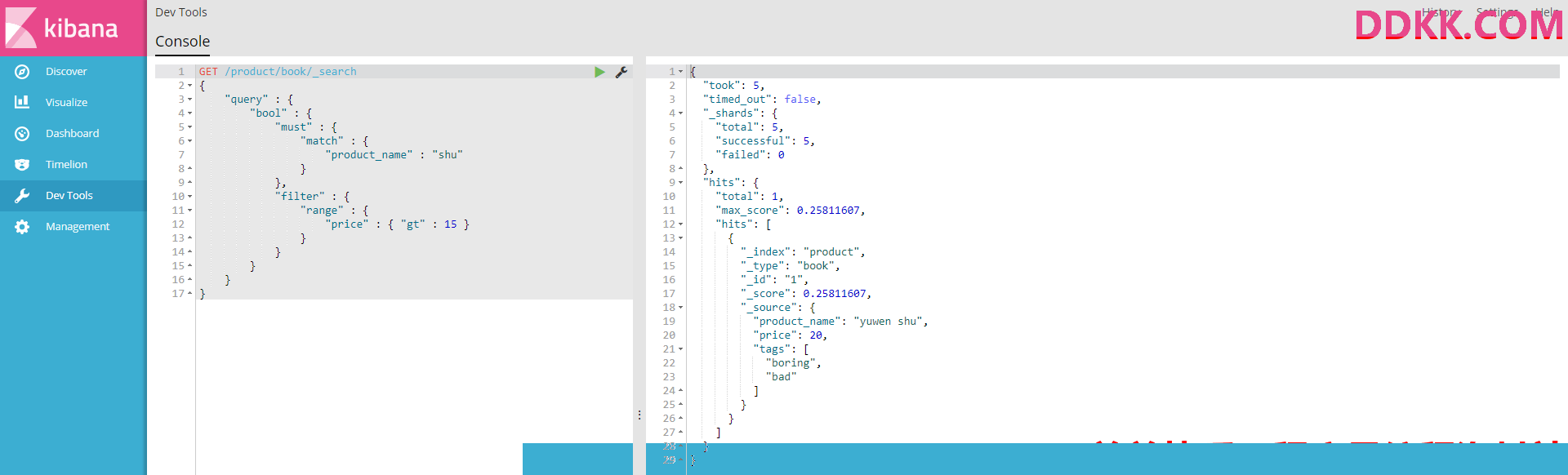
3、query filter
#搜索商品名称包含shu,而且售价大于15元的商品
GET /product/book/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"product_name" : "shu"
}
},
"filter" : {
"range" : {
"price" : { "gt" : 15 }
}
}
}
}
}
4、full-text search(全文检索)
GET /product/book/_search
{
"query" : {
"match" : {
"product_name" : "yuwen shu"
}
}
}
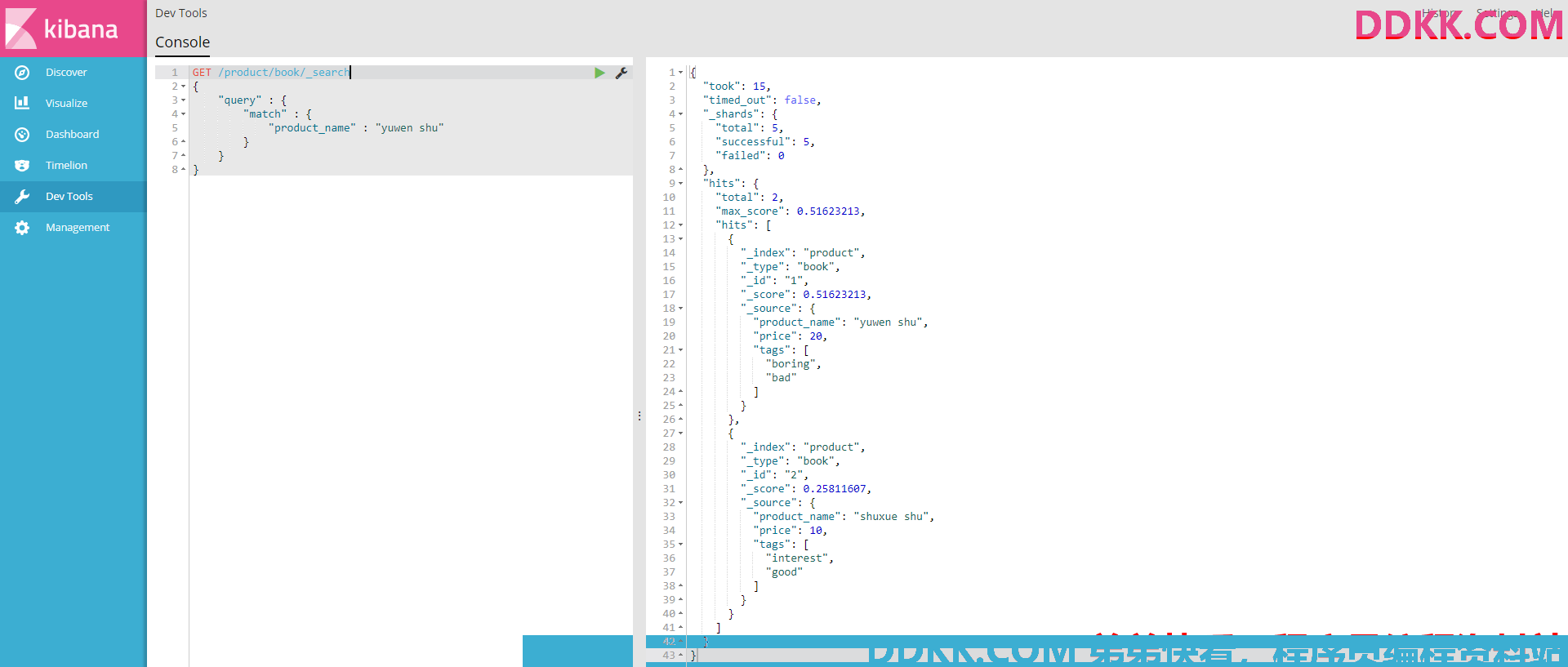
可以看到我们搜索的是yuwen shu但是shuxue shu也被搜索出来了,结果显示yuwen shu的score=0.51623213,shuxue shu的score=0.25811607。
这是因为当我们往product_name写入yuwen shu和shuxue shu的时候,es自动给我们建立了倒排索引,结构为:
| 关键词 | ids |
|---|---|
| yuwen | 1 |
| shuxue | 2 |
| shu | 1,2 |
在我们搜索yuwen shu的时候,分别用yuwen和shu去倒排索引里面找,关键词yuwen找到id=1的document,关键词shu找到id=1,2的document,因此这两个document都会被检索出来且搜索串拆解后的关键词两次匹配到id=1的document,因此id=1的document分数比较高。
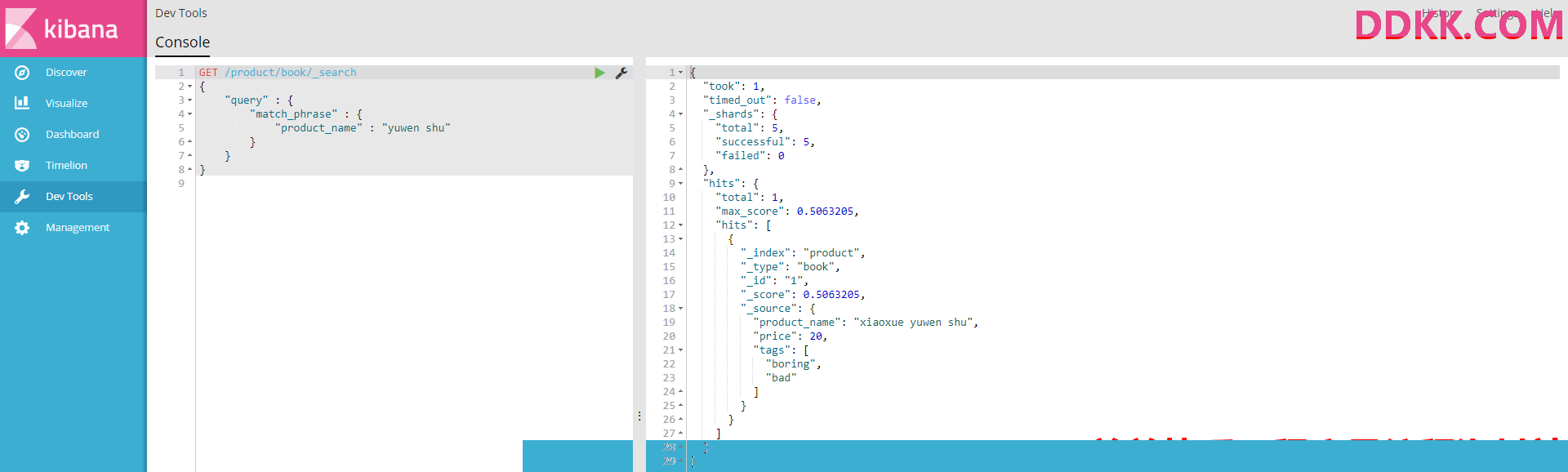
5、phrase search(短语搜索)
要求指定字段的文本中包含搜索串,才算匹配上
#查找商品名称包含wen shu的商品
GET /product/book/_search
{
"query" : {
"match_phrase" : {
"product_name" : "yuwen shu"
}
}
}
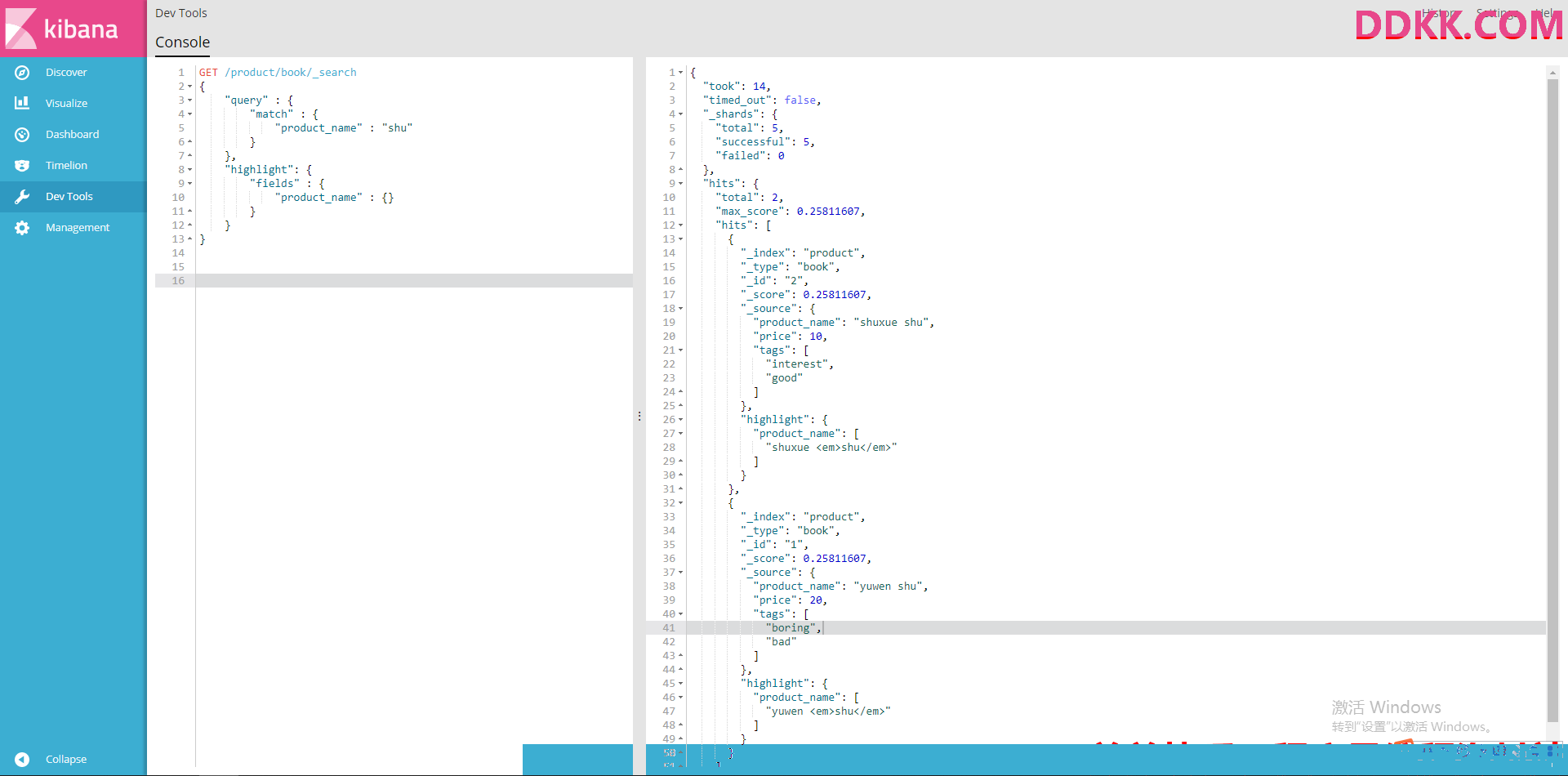
6、highlight search(高亮显示搜索结果)
#搜索产品名称为shu的商品且高亮显示搜索串
GET /product/book/_search
{
"query" : {
"match" : {
"product_name" : "shu"
}
},
"highlight": {
"fields" : {
"product_name" : {}
}
}
}