16、Kafka 实战 - Kafka集成外部系统之集成Flume
Flume 是一个在大数据开发中非常常用的组件。可以用于 Kafka 的生产者,也可以用于 Kafka 的消费者。
Flume安装和部署:https://blog.csdn.net/qq_18625571/article/details/131678589?spm=1001.2014.3001.5501
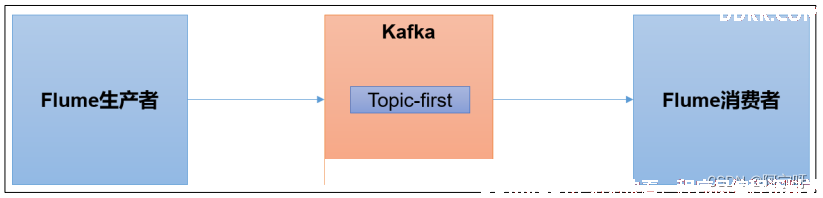
1 Flume生产者

1、 在hadoop102启动Kafka集群。
zk.sh start
kf.sh start
2、 在hadoop103启动Kafka消费者。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --topic first
3、 在hadoop102上安装Flume:https://blog.csdn.net/qq_18625571/article/details/131678589?spm=1001.2014.3001.5501 第一章Flume安装部署。
4、 在/opt/module/flume-1.9.0/job目录下创建配置文件file_to_kafka.conf。
# 1 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2 配置 source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
# 3 配置 channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 4 配置 sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# 5 拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
5、 启动Flume
bin/flume-ng agent -c conf/ -n a1 -f job/file_to_kafka.conf
6、 向/opt/module/applog/app.log 里追加数据,查看 kafka 消费者消费情况。
mkdir applog
echo hello >> /opt/module/applog/app.log
7、 观察 kafka 消费者,能够看到消费的 hello 数据。
2 Flume消费者
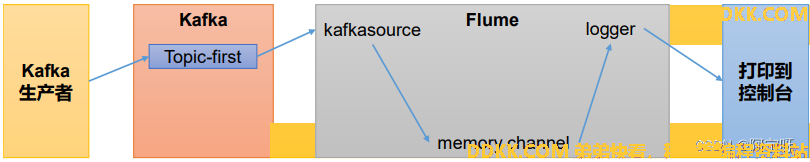
1、 在 hadoop102 节点的 Flume 的/opt/module/flume/job 目录下创建 kafka_to_file.conf。
# 1 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2 配置 source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 50
a1.sources.r1.batchDurationMillis = 200
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092
a1.sources.r1.kafka.topics = first
a1.sources.r1.kafka.consumer.group.id = custom.g.id
# 3 配置 channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 4 配置 sink
a1.sinks.k1.type = logger
# 5 拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2、 启动 Flume。
bin/flume-ng agent -c conf/ -n a1 -f job/kafka_to_file.conf -Dflume.root.logger=INFO,console
3、 启动 kafka 生产者,并输入数据,例如:hello world
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
4、 观察控制台输出的日志