07、Kafka 实战 - Kafka Broker之Kafka副本
1 副本基本信息
Kafka 副本可以提高数据可靠性。分为Leader 和 Follower;Kafka 生产者只会把数据发往 Leader,然后 Follower 找Leader 进行同步数据。
Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从ISR 中选举新的Leader。
OSR,表示Follower 与Leader 副本同步时,延迟过多的副本。
2 Leader选举流程
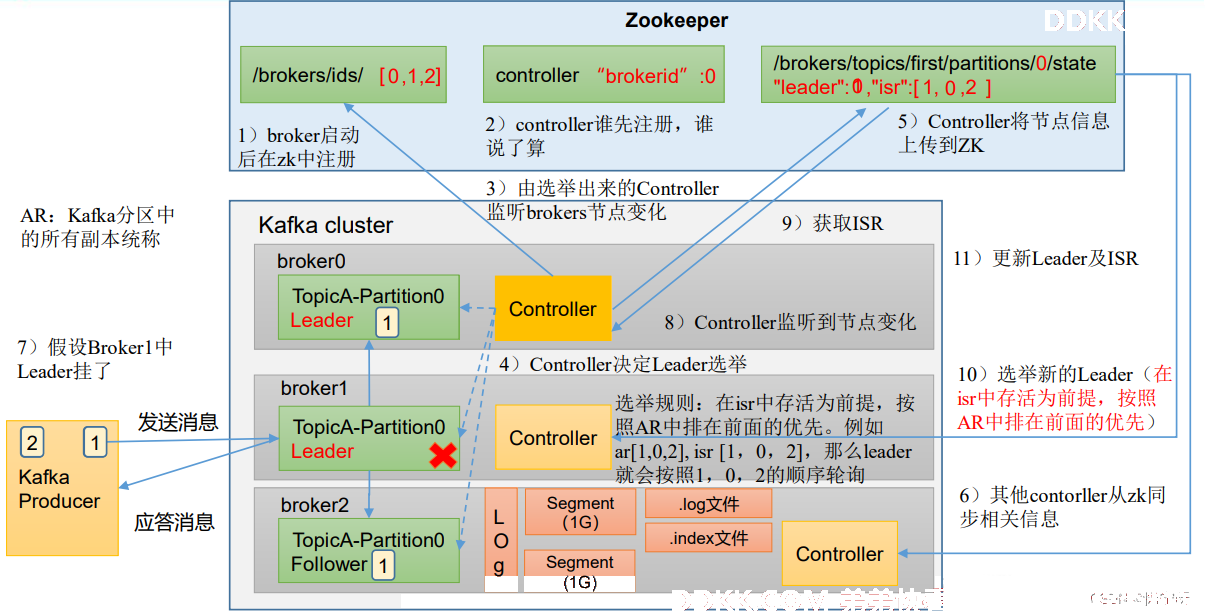
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader,负责管理集群 broker 的上下线、所有 topic 的分区副本分配和 Leader 选举等工作。
Controller 的信息同步工作是依赖于Zookeeper 的。
Zookeeper集群与Kafka集群间的通信:
1、 Kafka集群的每个broker启动之后都会向zookeeper进行注册。
2、 注册完毕之后开始选择controller节点(争先抢占方式)。
3、 选举出来的controller监听/brokers/ids/节点的变化。
4、 监控完毕之后根据选举规则开始真正的选举Leader。
5、 Controller将节点的Leader信息和isr信息写到zookeeper上。
6、 其它的controller节点会冲zookeeper上拉取数据进行同步(防止controllerLeader挂了,随时上位)。
7、 生产者往集群发送数据,发送数据之后Leader主动与Follower进行同步(底层通过LOG进行存储,实际为segment,分为.log文件和.index文件)再进行应答。
8、 当Leader节点挂了之后controller监控到节点变化。
9、 Controller从zookeeper上拉取Leader信息和isr信息。
10、 Controller根据拉取的信息和选举规则再重新选举Leader。
11、 选举出来新的Leader之后更新zookeeper中的信息。
(0)启动hadoop105中的Kafka。
bin/kafka-server-start.sh -daemon ./config/server.properties
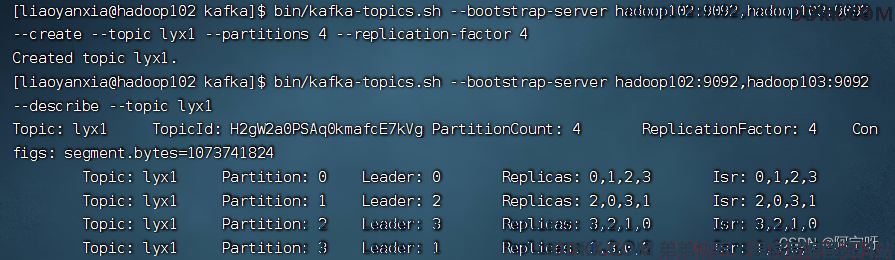
1、 创建一个新的topic,4个分区,4个副本
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --create --topic lyx1 --partitions 4 --replication-factor 4
2、 查看Leader分布情况
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --describe --topic lyx1
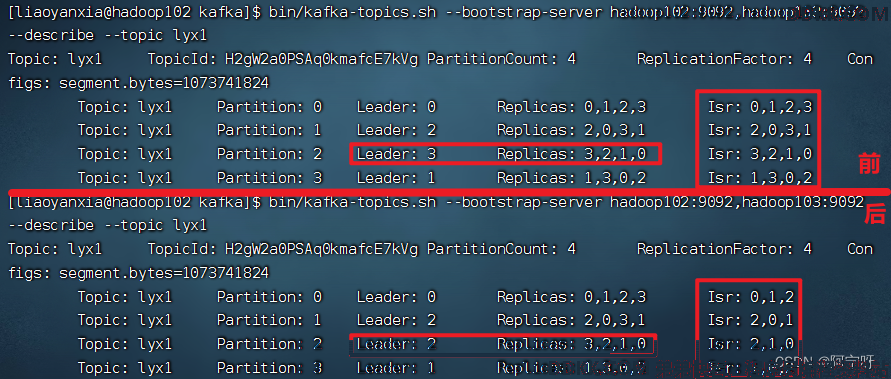
3、 停止掉hadoop105的kafka进程,并查看Leader分区情况
bin/kafka-server-stop.sh
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --describe --topic lyx1
4、 停止掉hadoop104的kafka进程,并查看Leader分区情况
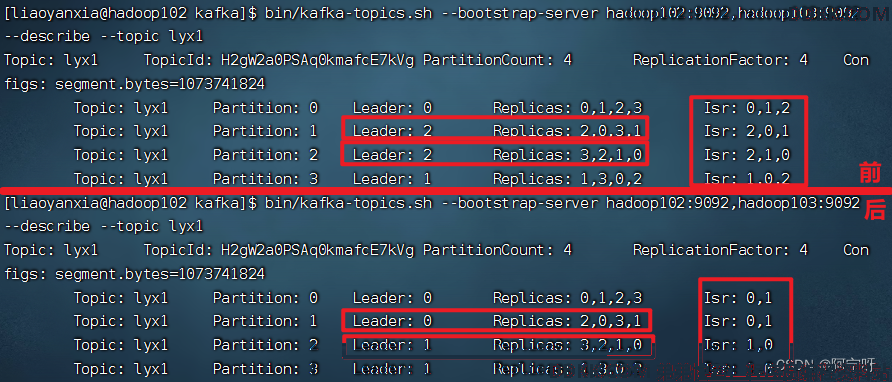
5、 启动hadoop105的kafka进程,并查看Leader分区情况
bin/kafka-server-start.sh -daemon ./config/server.properties
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --describe --topic lyx1
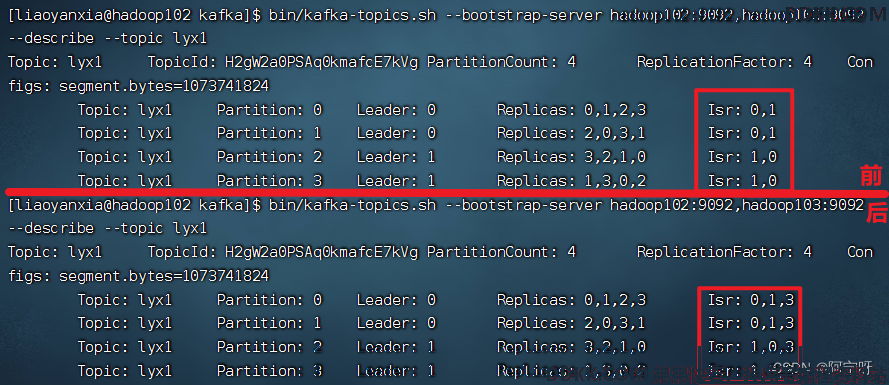
6、 启动hadoop104的kafka进程,并查看Leader分区情况
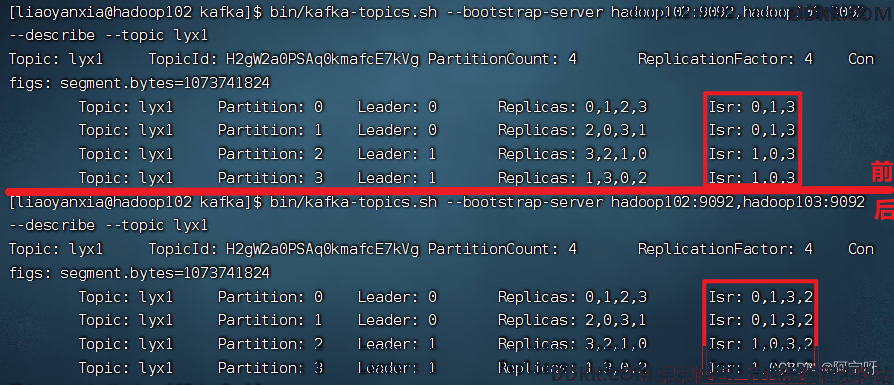
综上,ISR为和 Leader 保持同步的 Follower 集合,即表示存活的集合。Replicas为AR,在选举Leader时以Isr中从存活为前提,按AR中顺序进行轮询。
3 Leader和Follower故障处理
LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1。
HW(High Watermark):所有副本中最小的LEO 。
3.1 Follower故障
1、 初始:Leader先接受数据再进行同步到副本,此时消费者能看到的最大offset为4,即HW-1,LEO和HW如下:
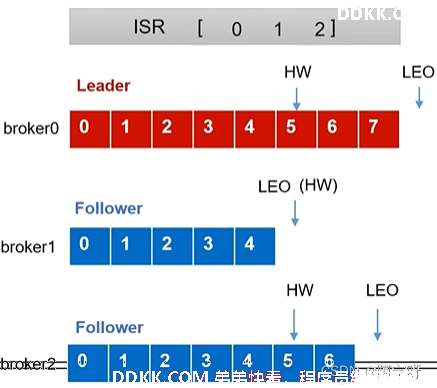
2、 Follower发生故障后被临时踢出ISR。
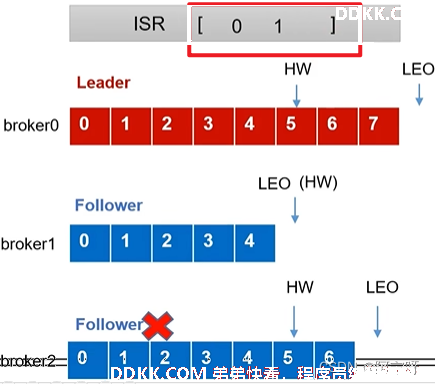
3、 期间Leader和Follower继续接受数据。
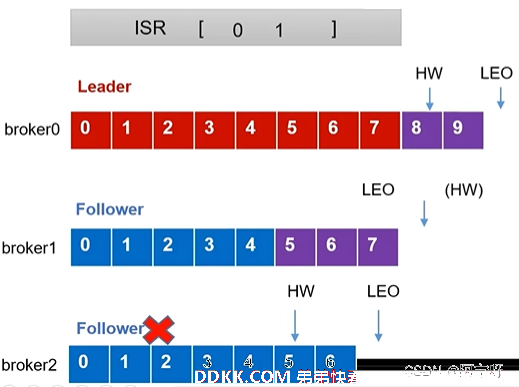
4、 故障Follower恢复后,Follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取去掉(认为是没有验证过的),从HW开始向Leader进行同步。
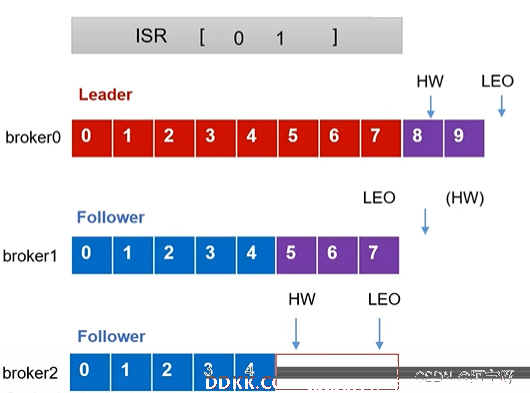
5、 等该Follower的LEO大于等于该Partition的HW,即Follower追上Leader后,就可以重新加入ISR。
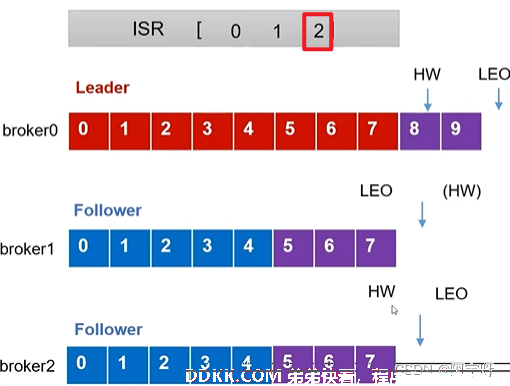
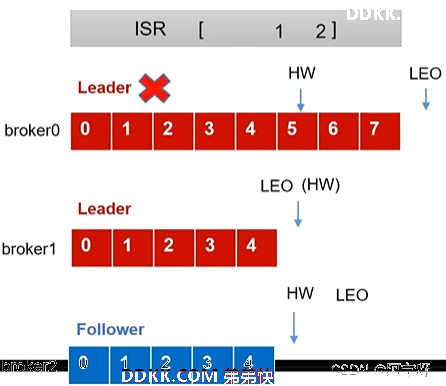
3.2 Leader故障
1、 初始:

2、 Leader发生故障后被临时踢出ISR,从ISR中选一个新的Leader。
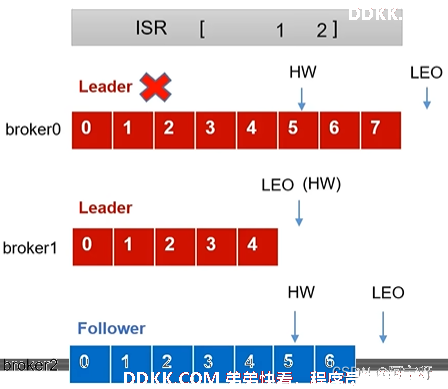
3、 为保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于HW的部分截掉,然后从新的Leader同步数据。
PS:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
故障Leader中的数据5、6、7可能会丢失。
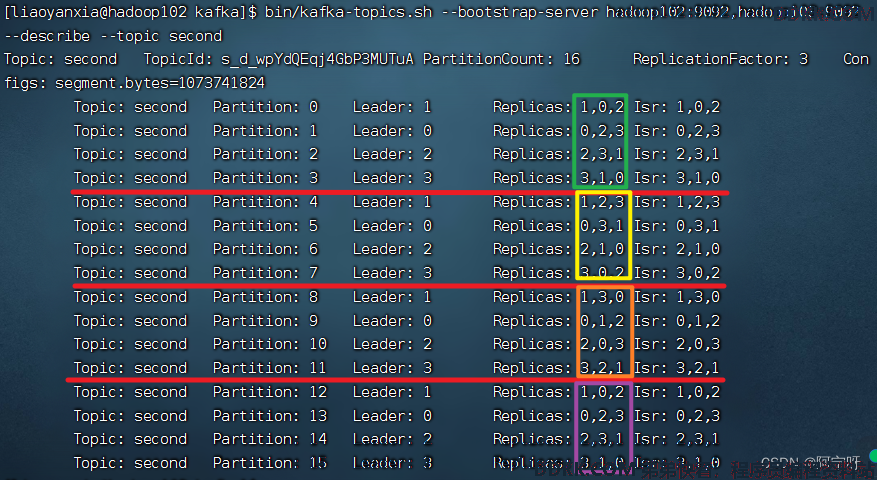
4 分区副本分配
kafka 的分区数大于服务器台数,在 kafka底层分配存储副本情况:
1、 创建16分区,3个副本:
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --create --partitions 16 --replication-factor 3 --topic second
2、 查看分区和副本情况:
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --describe --topic second