15、MyBatis 源码分析 - scripting 包
动态SQL 是 Mybatis 的强大特性之一。如果在项目中使用的是原生的 JDBC,那么如果想要根据不同条件拼接 SQL 语句,是非常单调且痛苦的过程。你可能会发现自己一直在做很多重复的工作。
但是利用动态 SQL,就可以彻底的摆脱这种痛苦了。不过使用动态 SQL 并非是一件易事,但借助可用于任何 SQL 映射语句中的强大的动态 SQL 语句,Mybatis 显著的提升了这一特性的易用性,将本来难用的动态 SQL 变更易用。
Mybatis 动态 SQL 样例如下:
SELECT * FROM BLOG
<where>
state = ‘ACTIVE’
<if test="title != null">
AND title like{title}
</if>
</where>
如何将这段脚本解析为可以交给数据库执行的 SQL 呢?这项工作就是交给 scripting 包来完成的工作。接下来就让我们进入到 scripting 包的学习中来吧。
包结构分析
-
scripting
-
defaults(包)
- DefaultParameterHandler
- RawLanguageDrvier
- RawSqlSource
-
xmltags(包)
- SqlNode、XXXSqlNode
- OgnlCache、OgnlClassResolver、OgnlMemberAccess
- XMLLanguageDriver
- XMLScriptBuilder
-
LanguageDriver
-
LanguageDriverRegistry
-
ScriptingException
scripting 包中最为核心的类就是 LanguageDriver,它是一个接口,通过接口的实现类,就可以生成执行 SQL 所需要的 SqlSource 和 ParameterHandler 。LanguageDriverRegistry 是用来存储所有语言驱动的注册表。
default 子包中包含了 LanguageDriver、SqlSource、ParameterHandler 的默认实现类。
xmltags 子包中也包含了一个 LanguageDriver 的实现类,还有很多辅助类。
LanguageDriver 和 LanguageDriverRegistry
LanguageDriver
如果问scripting 包中有没有一个最重要的类,那么一定是 LanguageDriver,包中的其他类都是围绕这个类所展开的。
// 创建 ParameterHandler 可以给 PreparedStatement 设置参数
ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql);
// 根据脚本生成 SqlSource
SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType);
// 根据脚本生成 SqlSource
SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType);
LanguageDriver 的实现类
Mybatis 自定义的语言驱动有两个:XMLLanguageDriver、RawLanguageDriver。它们之间的关系如下:
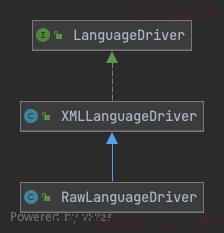
XMLLanguageDriver
这个是Mybatis 语言驱动的默认实现类,可以将动态节点解析为可以直接交给数据库执行的 SQL 语句。
核心方法
// 返回 ParameterHandler 的默认实现
@Override
public ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
return new DefaultParameterHandler(mappedStatement, parameterObject, boundSql);
}
// 解析脚本节点生成 SqlSource,处理在映射文件中声明的 SQL
@Override
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
// 脚本语句,通过 XMLScriptBuilder 进行解析
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
return builder.parseScriptNode();
}
// 解析脚本生成 SqlSource,处理注解中声明的 SQL 语句
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType) {
// 兼容注解中的 SQL 语句,如果是脚本的话,则需要使用脚本驱动进行解析
if (script.startsWith("<script>")) {
XPathParser parser = new XPathParser(script, false, configuration.getVariables(), new XMLMapperEntityResolver());
return createSqlSource(configuration, parser.evalNode("/script"), parameterType);
}
// 如果是非脚本语言
else {
script = PropertyParser.parse(script, configuration.getVariables());
TextSqlNode textSqlNode = new TextSqlNode(script);
// 动态语句则使用 DynamicSqlSource 解析
if (textSqlNode.isDynamic()) {
return new DynamicSqlSource(configuration, textSqlNode);
}
// 非动态语句则使用 RawSqlSource 解析
else {
return new RawSqlSource(configuration, script, parameterType);
}
}
}
可以看到如果是脚本语言的话,都是交给 XMLScriptBuilder 来帮助解析构建为 SqlSource 的。
RawLanguageDriver
RawLanguageDriver 也是 Mybatis 的内置语言驱动实现之一,它和 XMLLanguageDriver 的区别在于,它只允许生成 RawSqlSource,如果解析生成了其他的 SqlSource 实现类的话,就会抛出异常。
代码实现如下,可以发现 RawLanguageDriver 是继承自 XMLLanguageDriver 的,并且也确实都是使用的父类的方法,但是在调用之后会检查生成的 SqlSource 是不是 RawSqlSource,如果不是则会抛出异常。
public class RawLanguageDriver extends XMLLanguageDriver {
@Override
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
SqlSource source = super.createSqlSource(configuration, script, parameterType);
checkIsNotDynamic(source);
return source;
}
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType) {
SqlSource source = super.createSqlSource(configuration, script, parameterType);
checkIsNotDynamic(source);
return source;
}
// SqlSource 类型校验,保证返回的一定是 RawSqlSource
private void checkIsNotDynamic(SqlSource source) {
if (!RawSqlSource.class.equals(source.getClass())) {
throw new BuilderException("Dynamic content is not allowed when using RAW language");
}
}
}
LanguageDriverRegistry
Mybatis 从 3.2 版本开始支持插入脚本语言,也就是说允许你使用自定义的语言驱动,并基于这种语言来编写动态 SQL。那么就需要一张注册表类来管理这些语言驱动,不管是 Mybatis 自带的还是用户自定义的。
LanguageDriverRegistry 的作用就是如此,它记录了所有待使用的语言驱动。
核心成员变量
// 语言驱动注册表,保存了所有可使用的语言驱动
private final Map<Class<? extends LanguageDriver>, LanguageDriver> LANGUAGE_DRIVER_MAP = new HashMap<>();
// 默认语言驱动,在没有指定用什么语言驱动解析时,就会使用这个语言驱动
private Class<? extends LanguageDriver> defaultDriverClass;
核心方法
// 注册驱动到注册表中
public void register(Class<? extends LanguageDriver> cls) {
if (cls == null) {
throw new IllegalArgumentException("null is not a valid Language Driver");
}
LANGUAGE_DRIVER_MAP.computeIfAbsent(cls, k -> {
return k.getDeclaredConstructor().newInstance();
});
}
// 注册驱动到注册表中
public void register(LanguageDriver instance) {
if (instance == null) {
throw new IllegalArgumentException("null is not a valid Language Driver");
}
Class<? extends LanguageDriver> cls = instance.getClass();
if (!LANGUAGE_DRIVER_MAP.containsKey(cls)) {
LANGUAGE_DRIVER_MAP.put(cls, instance);
}
}
// 从驱动表中获取驱动
public LanguageDriver getDriver(Class<? extends LanguageDriver> cls) {
return LANGUAGE_DRIVER_MAP.get(cls);
}
// 获取默认驱动
public LanguageDriver getDefaultDriver() {
return getDriver(getDefaultDriverClass());
}
xmltags 子包
在xmltags 子包中包含了语言驱动接口的默认实现类 XMLLanguageDriver 以及相关工具类。
SQL 节点树的构建
映射文件中的数据库操作语句如下代码所示,它实际上是由众多的 SQL 节点组成的一颗节点树。而这棵树的构建工作是交给 XMLScriptBuilder 来完成的。
SELECT * FROM BLOG
<where>
state = ‘ACTIVE’
<if test="title != null">
AND title like{title}
</if>
</where>
XMLScriptBuilder 核心成员变量
// 要解析构建的XML节点
private final XNode context;
// 当前节点是否为动态节点,如果 SQL 中有 ${} 或者有 <if>、<foreach> 等动态节点时为 true
private boolean isDynamic;
// 输入参数类型
private final Class<?> parameterType;
// 保存节点对应的节点处理器
private final Map<String, NodeHandler> nodeHandlerMap = new HashMap<>();
节点树的构建过程详解
public SqlSource parseScriptNode() {
// 解析节点
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
// 如果是动态节点
if (isDynamic) {
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
}
// 如果不是动态节点
else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
// 解析当前节点的子节点
protected MixedSqlNode parseDynamicTags(XNode node) {
// 存储构建好的 Sql 节点
List<SqlNode> contents = new ArrayList<>();
NodeList children = node.getNode().getChildNodes();
// 如果有子节点,则递归解析
for (int i = 0; i < children.getLength(); i++) {
XNode child = node.newXNode(children.item(i));
// 如果是文本节点,则直接封装到 StaticTextSqlNode 中
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
isDynamic = true;
} else {
contents.add(new StaticTextSqlNode(data));
}
}
// 如果是元素节点,则需要找到对应的节点处理器处理
else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) {
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
handler.handleNode(child, contents);
isDynamic = true;
}
}
return new MixedSqlNode(contents);
}
节点处理器
根据不同的元素节点会选用不同的节点处理器去处理它,处理的过程就是将脚本语言转换为可以交给数据库执行的 SQL。在 XMLScriptBuilder 内部声明不同的节点处理器,用于处理不同类型的节点,它们都实现了一个公共的接口,也就是 NodeHandler。
声明的节点处理器如下:

节点和节点处理器的对应关系如下:
<trim/> -- TrimHandler
<where/> -- WhereHandler
<set/> -- SetHandler
<foreach/> -- ForEachHandler
<if/> -- IfHandler
<choose/> -- ChooseHandler
<when/> -- IfHandler
<otherwise/> -- OtherwiseHandler
<bind/> -- BindHandler
NodeHandler#
private interface NodeHandler {
// 处理节点
void handleNode(XNode nodeToHandle, List<SqlNode> targetContents);
}
- nodeToHandle:待处理的节点。
- targetContents:NodeHandler 是 XMLScriptBuilder 的内部类,XMLScriptBuilder 讲构建的工作交给了每一个节点处理器,节点处理器在处理结束后会构建一个对应类型的 SqlNode,而 targetContents 就是用来存储节点处理器生成的 SqlNode。
ChooseHandler 和 TrimHandler
由于NodeHandler 的实现类的逻辑都比较简单,所以挑选了两个比较典型的实现类进行分析。
ChooseHandler
private class ChooseHandler implements NodeHandler {
public ChooseHandler() {
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 保存 WhereSqlNode
List<SqlNode> whenSqlNodes = new ArrayList<>();
// 保存 OtherwiseSqlNode
List<SqlNode> otherwiseSqlNodes = new ArrayList<>();
handleWhenOtherwiseNodes(nodeToHandle, whenSqlNodes, otherwiseSqlNodes);
// 从 OtherwiseSqlNode 中得到唯一的默认节点
SqlNode defaultSqlNode = getDefaultSqlNode(otherwiseSqlNodes);
// 构建 ChooseSqlNode
ChooseSqlNode chooseSqlNode = new ChooseSqlNode(whenSqlNodes, defaultSqlNode);
targetContents.add(chooseSqlNode);
}
private void handleWhenOtherwiseNodes(XNode chooseSqlNode, List<SqlNode> ifSqlNodes, List<SqlNode> defaultSqlNodes) {
List<XNode> children = chooseSqlNode.getChildren();
for (XNode child : children) {
// 根据不同的节点类型选用不同的节点处理器
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler instanceof IfHandler) {
handler.handleNode(child, ifSqlNodes);
} else if (handler instanceof OtherwiseHandler) {
handler.handleNode(child, defaultSqlNodes);
}
}
}
private SqlNode getDefaultSqlNode(List<SqlNode> defaultSqlNodes) {
// 默认的 SqlNode 有且只有一个
SqlNode defaultSqlNode = null;
if (defaultSqlNodes.size() == 1) {
defaultSqlNode = defaultSqlNodes.get(0);
} else if (defaultSqlNodes.size() > 1) {
throw new BuilderException("Too many default (otherwise) elements in choose statement.");
}
return defaultSqlNode;
}
}
TrimHandler
private class TrimHandler implements NodeHandler {
public TrimHandler() {
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 解析所有子节点
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// 提取声明的属性
String prefix = nodeToHandle.getStringAttribute("prefix");
String prefixOverrides = nodeToHandle.getStringAttribute("prefixOverrides");
String suffix = nodeToHandle.getStringAttribute("suffix");
String suffixOverrides = nodeToHandle.getStringAttribute("suffixOverrides");
// 构建 TrimSqlNode
TrimSqlNode trim = new TrimSqlNode(configuration, mixedSqlNode, prefix, prefixOverrides, suffix, suffixOverrides);
targetContents.add(trim);
}
}
SqlNode 的执行环境
只要使用过 Mybatis 的人就知道,动态 SQL 最重要的一点就是根据入参的值来决定最后生成的 SQL。也就是说 SqlNode 执行的时候是需要环境参数的,而这个环境其实就是入参。
SqlNode 会根据入参的值来决定自身的执行逻辑。在 Mybatis 中是通过 DynamicContext 在 SqlNode 之间传递入参,并且其中还存放了 SqlNode 处理过程后生成的 SQL 语句。
核心成员变量
// bindings 的 key,对应的 value 为原入参
public static final String PARAMETER_OBJECT_KEY = "_parameter";
// bindings 的 key,对应的 value 为当前环境下生效的 databaseId
public static final String DATABASE_ID_KEY = "_databaseId";
// 用来存储入参和动态增加的变量
private final ContextMap bindings;
// 用来存储 SqlNode 处理结束后生成的 sql
private final StringJoiner sqlBuilder = new StringJoiner(" ");
// 用来提供唯一编号,通过每次获取后自增来保证得到的编号唯一
private int uniqueNumber = 0;
Sql 节点
经过XMLScriptBuilder 处理后,就会将节点构建为对应的 SqlNode。其中保存了节点本身的信息和子节点。所有的 Sql 节点都实现了 SqlNode 这个公共接口。
SqlNode 接口中只声明了一个 apply 方法,入参就是我们前面提到的 DynamicContext,出参是一个布尔类型的值,但只有 <choose> 节点才有使用到这个出参。
boolean apply(DynamicContext context);
SqlNode 的所有实现类如下图所示。

节点、节点处理器和对应的映射实体类关系如下:
<trim/> -> TrimHandler -> TrimSqlNode
<where/> -> WhereHandler -> WhereSqlNode
<set/> -> SetHandler -> SetSqlNode
<foreach/> -> ForEachHandler -> ForEachSqlNode
<if/> -> IfHandler -> IfSqlNode
<choose/> -> ChooseHandler -> ChooseSqlNode
<otherwise> -> OtherwiseHandler -> TextSqlNode/StaticTextSqlNode
<bind> -> BindHandler -> VarDecSqlNode
SQL 语句 -> XMLScriptBuilder -> TextSqlNode/StaticTextSqlNode
注:区分静态文本节点还是文本节点,是通过判断语句中是否包含 “${}”,如果包含则是文本节点,不包含则是静态文本节点。
- 静态文本节点:SELECT id, name, age, email FROM user WHERE id = #{id}
- 文本节点:SELECT id, name, age, email FROM user WHERE id =
${userId}
可能有的小伙伴发现 MixedSqlNode 没有包含在其中,其实是因为它是一个很特殊的 SqlNode,可以认为它是一个容器,它能保存任意多个 SqlNode,并且它本身不做任何的处理,它的只会指挥包含的 SqlNode 去处理。正是由于它的这两个特性,导致它可以作为通用的返回值。
接下来我们会挨个分析 SqlNode 揭开它们看似神秘的面纱。
StaticTextSqlNode 和 TextSqlNode
StaticTextSqlNode(静态文本节点)是功能最简单的一个节点,由于它只包含了 “#{}”,所以它不需要做任何的处理,只需要将内容拼接到 SQL 后就行了。代码实现如下:
@Override
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}
TextSqlNode(文本节点)和静态文本节点不同,因为文本节点中还能包含 “${}”,所以在执行的时候需要替换为对应的值。代码实现如下:
@Override
public boolean apply(DynamicContext context) {
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
context.appendSql(parser.parse(text));
return true;
}
private static class BindingTokenParser implements TokenHandler {
// 动态上下文
private DynamicContext context;
// 注入检查拦截器,在当前版本中的 Mybatis 还没有被使用到
private Pattern injectionFilter;
@Override
public String handleToken(String content) {
// 得到原始的入参
Object parameter = context.getBindings().get("_parameter");
if (parameter == null) {
context.getBindings().put("value", null);
} else if (SimpleTypeRegistry.isSimpleType(parameter.getClass())) {
context.getBindings().put("value", parameter);
}
// 得到 content 对应的 value
Object value = OgnlCache.getValue(content, context.getBindings());
String srtValue = value == null ? "" : String.valueOf(value);
// 注入检查,在当前版本中的 Mybatis 还没有被使用到
checkInjection(srtValue);
return srtValue;
}
}
IfSqlNode
<if test=""> 是使用的最多的一个节点了,等同于 Java 语言中的 if ,如果 test 属性中内容执行结果为 true 的话,那么就执行子节点的内容。
成员变量
// 表达式执行器
private final ExpressionEvaluator evaluator;
// 需要执行的表达式
private final String test;
// 当前节点
private final SqlNode contents;
表达式解析器是用来执行表达式的,在这篇文章中不会去讲解如何实现的,我们只需要知道实际上是使用 Ognl 来实现的表达式解析。如果有感兴趣的小伙伴可以去了解一下。
核心方法
@Override
public boolean apply(DynamicContext context) {
// 执行表达式,如果返回 true,则解析节点
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
TrimSqlNode
TrimSqlNode 是一个辅助类型的功能性节点,因为它不对应一个具体的 SQL 关键字,只是为了解决在动态 SQL 拼接过程中产生的"副作用",如下代码所示。由于 SQL 是动态拼接的,所以并不知道哪一个 if 会生效,我们就必须要在其前面加上 AND 关键字。
但是这样就会带来另一个问题,假设只有第三个 <if> 生效了,那么最终生成的 SQL 就是这样的,SELECT * FROM user WHERE AND user.sex ={sex} AND user.del_flag = 1,可以发现多了一个 AND 关键字,导致这条 SQL 是会报错的。
<select id="selectPage">
SELECT * FROM user
WHERE
<if test="id != null">
AND user.id ={id}
</if>
<if test="name != null and name != ''">
AND user.name LIKE CONCAT('%',{name}, '%')
</if>
<if test="sex != null">
AND user.sex ={sex}
</if>
-- 用户没有被删除
AND user.del_flag = 1
</select>
但是Mybatis 也给我们提供了解决方案,也就是使用 <trim>。修改后的代码如下所示,可以发现在 <trim> 中我们设置了 prefixOverrides 的值为 AND,代表我们想要覆盖或者说删除所包含节点生成 SQL 开头的 AND 字符。当然,针对这类问题,其实 Mybatis 还为我们设计了一个更专业的 <where> 和 <set> 元素来解决,马上我们就会讲到。
<select id="selectPage">
SELECT * FROM user
WHERE
<trim prefixOverrides="AND" >
<if test="id != null">
AND user.id ={id}
</if>
<if test="name != null and name != ''">
AND user.name LIKE CONCAT('%',{name}, '%')
</if>
<if test="sex != null">
AND user.sex ={sex}
</if>
AND user.del_flag = 1
</trim>
</select>
了解了<trim> 节点的作用,我们就来分析分析代码的实现吧,看看 TrimSqlNode 是如何介入到所有子节点的 SQL 生成的,在子节点处理完成后对这其生成的 SQL “掐头去尾”。
成员变量
// 要处理 SQL 节点
private final SqlNode contents;
// 要添加的前缀
private final String prefix;
// 要添加的后缀
private final String suffix;
// 要覆盖的前缀,入参是一个字符串,但是会按照 '|' 进行分割,也就是说其实可以声明需要覆盖的多个可能性
private final List<String> prefixesToOverride;
// 要覆盖的后缀,入参是一个字符出,但是会按照 '|' 进行分割,也就是说其实可以声明需要覆盖的多个可能性
private final List<String> suffixesToOverride;
// 全局配置信息
private final Configuration configuration;
如何实现的覆盖前缀和后缀
其实这个点才是 TrimSqlNode 最经典的一点,它巧妙的运用了代理模式,在内部拦截了本应该拼接在主 DynamicContext 的请求,先将子节点生成的 SQL 暂存在另一个 StringBuilder 中,等待所有的子节点处理完成后,在对暂存的 SQL 前缀和后缀进行覆盖,在拼接到主 DynamicContext 后。
接下来让我们直接来看代码:
@Override
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
filteredDynamicContext.applyAll();
return result;
}
private class FilteredDynamicContext extends DynamicContext {
// 被代理的动态上下文
private DynamicContext delegate;
// 暂存子节点处理生成的 SQL
private StringBuilder sqlBuffer;
...
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
// 将 SQL 字符串大写,方便判断是否以指定的字符串开头或结束
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
// 如果不为空才需要覆盖
if (trimmedUppercaseSql.length() > 0) {
// 覆盖前缀
applyPrefix(sqlBuffer, trimmedUppercaseSql);
// 覆盖后缀
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
@Override
public Map<String, Object> getBindings() {
return delegate.getBindings();
}
@Override
public void bind(String name, Object value) {
delegate.bind(name, value);
}
@Override
public int getUniqueNumber() {
return delegate.getUniqueNumber();
}
// 只对 appendSql 做了拦截处理
@Override
public void appendSql(String sql) {
sqlBuffer.append(sql);
}
@Override
public String getSql() {
return delegate.getSql();
}
}
通过观察源码可以发现,FilteredDynamicContext 覆盖了 DynamicContext 的所有公共方法,除了 appendSql 方法做了拦截,其他的方法都是通过调用代理类来实现了的。
在最后所有子节点处理结束后,才开始进行覆盖处理,覆盖的代码很简单,其实就是判断是否以指定字符串开头或者结尾,如果是的话就删除,删除后就拼接前缀和后缀,就这就实现了覆盖。
WhereSqlNode 和 SetSqlNode
刚才我们讲到了 TrimSqlNode 它是一个通用的解决方案,但是通用就意味着需要配置,所以现在我就给你们介绍两个专业的解决方案,它们可以做到零配置,实现我们想要的效果。
WhereSqlNode 解决的问题就是在动态拼接 WHERE 关键词后面的紧随的筛选条件时,第一个筛选条件的前面有 AND 或者是 OR 关键字问题。我们来对比一下使用 <trim> 和使用 <where> 的方案。
-- 使用 <trim>
<select id="selectPage">
SELECT * FROM user
<trim prefix="WHERE" prefixOverrides="AND">
<if test="id != null">
AND user.id ={id}
</if>
<if test="name != null and name != ''">
AND user.name LIKE CONCAT('%',{name}, '%')
</if>
<if test="sex != null">
AND user.sex ={sex}
</if>
</trim>
</select>
-- 使用 <where>
<select id="selectPage">
SELECT * FROM user
<where>
<if test="id != null">
AND user.id ={id}
</if>
<if test="name != null and name != ''">
AND user.name LIKE CONCAT('%',{name}, '%')
</if>
<if test="sex != null">
AND user.sex ={sex}
</if>
</where>
</select>
可以发现使用 <where> 完全不需要做任何配置,并且需要覆盖的前缀可以是 AND 也可以是 OR,而使用 <trim> 的话,还需要配置两个属性值。

然而WhereSqlNode 的实现却是特别的简单,因为它直接继承了 TrimSqlNode,并且设置了默认的参数。代码如下:
public class WhereSqlNode extends TrimSqlNode {
// 需要覆盖的前缀
private static List<String> prefixList = Arrays.asList("AND ","OR ","AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
// 只需要传递 configuration 和需要解析的节点,其他的都交给我来配置吧
public WhereSqlNode(Configuration configuration, SqlNode contents) {
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
SetSqlNode 解决的问题就是在动态拼接 SET 关键词后面的紧随的设置字段,第一个设置条件的前面有 , 或者最后一个设置条件后有 , 的问题。我们来对比一下使用 <trim> 和使用 <set> 的方案。
-- 使用 <trim>
<update id="update">
UPDATE user
<trim prefix="SET" suffixOverrides=",">
<if test="user.name != null and user.name != ''">
user.name ={user.name},
</if>
</trim>
WHERE user.id ={user.id}
</update>
-- 使用 <set>
<update id="update">
UPDATE user
<set>
<if test="user.name != null and user.name != ''">
user.name ={user.name},
</if>
</set>
</update>
WHERE user.id ={user.id}
可以发现使用 <set> 也完全不需要做任何配置,并且需要覆盖前缀或者后缀的, ,而使用 <trim> 的话,还需要配置两个属性值。
ChooseSqlNode
ChooseSqlNode 是依托于 IfSqlNode 之上的,利用它可以实现 if else if else 的效果。使用样例如下所示,这里使用的 <when> 实际上效果和 <if> 一样,只是换了一个名字而已,后面的逻辑实现也是通过的 IfSqlNode。
-- 将中文的性别转换为对应的编号
<choose>
<when test="sex = '男'">
AND user.sex = 0
</when>
<when test="sex = '女'">
AND user.sex = 1
</when>
<otherwise>
AND user.sex = 2
</otherwise>
</choose>
实现if else if else 的代码逻辑如下:
@Override
public boolean apply(DynamicContext context) {
for (SqlNode sqlNode : ifSqlNodes) {
if (sqlNode.apply(context)) {
// 只要有一个 <when> 判断通过了,那么就结束方法
return true;
}
}
// 如果没有一个 <when> 判断通过,则调用 <otherwise>
if (defaultSqlNode != null) {
defaultSqlNode.apply(context);
return true;
}
return false;
}
ForEachSqlNode
ForEachSqlNode 等同于 Java 语言中的 for 循环。一般我们会用它来实现 IN (...),样例如下,就是这样的代码,最后能给我们生成这样的字符串:"(1, 2, 3, 4)"
-- collection 要遍历的集合,可以是 Collection 可以是数组也可以是 Map 对象
-- open 要添加的前缀
-- close 要添加的后缀
-- separator 分隔符
<foreach collection="ids" open="(" close=")" separator="," item="id">
{id}
</foreach>
成员变量
// 表达式执行器
private final ExpressionEvaluator evaluator;
// 集合表达式,存储 <foreach> 标签 collection 属性的值
private final String collectionExpression;
// 当前节点
private final SqlNode contents;
// 要添加的前缀
private final String open;
// 要添加的后缀
private final String close;
// 元素之间的分隔符
private final String separator;
// 集合成员
private final String item;
// 代表序号的名称
private final String index;
// 全局配置信息
private final Configuration configuration;
实现代码主要逻辑如下
@Override
public boolean apply(DynamicContext context) {
Map<String, Object> bindings = context.getBindings();
// 得到需要遍历的集合
final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings);
// 如果集合为空,则不做处理
if (!iterable.iterator().hasNext()) {
return true;
}
boolean first = true;
// 拼接前缀 '('
applyOpen(context);
int i = 0;
for (Object o : iterable) {
DynamicContext oldContext = context;
// 如果是一个或者没有分隔符则不需要添加前缀
if (first || separator == null) {
context = new PrefixedContext(context, "");
} else {
context = new PrefixedContext(context, separator);
}
// 得到唯一数字
int uniqueNumber = context.getUniqueNumber();
// 如果类型是 Map.Entry
if (o instanceof Map.Entry) {
@SuppressWarnings("unchecked")
Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
applyIndex(context, mapEntry.getKey(), uniqueNumber);
applyItem(context, mapEntry.getValue(), uniqueNumber);
} else {
applyIndex(context, i, uniqueNumber);
applyItem(context, o, uniqueNumber);
}
// 拼接元素{__frch_id_uniqueNumber}
contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
// 拼接分隔符 ','
if (first) {
first = !((PrefixedContext) context).isPrefixApplied();
}
context = oldContext;
i++;
}
// 拼接后缀 ')'
applyClose(context);
context.getBindings().remove(item);
context.getBindings().remove(index);
return true;
}
// 添加变量
private void applyIndex(DynamicContext context, Object o, int i) {
if (index != null) {
/*
其实2 代码不难理解,稍微难以理解的可能是1 代码
因为在这个地方添加了值,在 foreach 节点处理完毕后又会把它删除
要知道如果是 "#{id}" 的话会被直接替换为 "#{__frch_id_index}"
但是如果是 ${id} 的话,就直接替换为具体的值,所以在这里添加的值其实是为了后面如果有声明了 ${id} 而准备的
*/
context.bind(index, o); //1
// itemizeItem() 是为了生成全局唯一的名称,防止重复
context.bind(itemizeItem(index, i), o); //2
}
}
// 添加变量
private void applyItem(DynamicContext context, Object o, int i) {
if (item != null) {
context.bind(item, o);
context.bind(itemizeItem(item, i), o);
}
}
// 生成唯一的名称
private static String itemizeItem(String item, int i) {
return ITEM_PREFIX + item + "_" + i;
}
在ForEachSqlNode 中,通过装饰者模式实现了分隔符的拼接。如果是第一个元素则拼接空字符串,如果不是第一个则拼接分隔符。将原本的 DynamicContext 用 PrefixedContext 封装,只在 appendSql 方法做了处理,代码实现如下:
private class PrefixedContext extends DynamicContext {
@Override
public void appendSql(String sql) {
// 由于 appendSql 可能会被调用多次
// 只有第一次调用 appendSql 才需要拼接前缀
if (!prefixApplied && sql != null && sql.trim().length() > 0) {
delegate.appendSql(prefix);
prefixApplied = true;
}
delegate.appendSql(sql);
}
}
在 ForEachSqlNode 中,如果直接拼接其子节点的内容的话,那么最后拼接的效果就会是这样 (#{id},#{id},#{id}),替换占位符后的效果就是 (1,2,3)。这样并不是我们想要的,所以我们需要将每个 #{id} 替换为唯一的值,来保证不会相互影响。
而 FilteredDynamicContext 作用就是如此,它同样是也是采用了装饰者模式,将子节点处理后的 SQL 中的 “#{id}” 进行替换。代码实现逻辑如下:
private static class FilteredDynamicContext extends DynamicContext {
// 被代理对象
private final DynamicContext delegate;
// 唯一的ID
private final int index;
// 元素下标的名称
private final String itemIndex;
// 元素名称
private final String item;
@Override
public void appendSql(String sql) {
/*
假设写的是
<foreach collection="ids" open="(" close=")" separator="," item="id">
{id}
</foreach>
下面的代码的作用就是将{id} 替换为{__frch_id_index}
注:index是一个数字,代表序号
*/
GenericTokenParser parser = new GenericTokenParser("#{", "}", content -> {
String newContent = content.replaceFirst("^\\s*" + item + "(?![^.,:\\s])", itemizeItem(item, index));
// 如果有声明 itemIndex 则尝试替换 itemIndex
if (itemIndex != null && newContent.equals(content)) {
newContent = content.replaceFirst("^\\s*" + itemIndex + "(?![^.,:\\s])", itemizeItem(itemIndex, index));
}
return "#{" + newContent + "}";
});
delegate.appendSql(parser.parse(sql));
}
}
VarDeclSqlNode
VarDeclSqlNode 是一个辅助类的 SqlNode 因为它的作用不是拼接 SQL,而是添加一个环境变量到上下文中。代码实现如下:
public class VarDeclSqlNode implements SqlNode {
// 变量名称
private final String name;
// 表达式,可以得到变量值
private final String expression;
@Override
public boolean apply(DynamicContext context) {
// 变量值
final Object value = OgnlCache.getValue(expression, context.getBindings());
// 将变量添加到当前上下文环境中
context.bind(name, value);
return true;
}
}
MixedSqlNode
MixedSqlNode 是一个特殊的 SqlNode,因为它是一个容器,可以包含多个 SqlNode,并且指挥它们按顺序执行。
public class MixedSqlNode implements SqlNode {
// 保存所有代执行的 SqlNode
private final List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
contents.forEach(node -> node.apply(context));
return true;
}
}
defaults 子包
在该包中包含了一些实现类。DefaultParameterHandler、RawLanguageDriver、RawSqlSource。RawLanguageDriver 在前面已经解析了,RawSqlSource 打算发到后面和其他的 SqlSource 实现类一起讲解。所以在这里只会讲解 DefaultParameterHandler。
DefaultParameterHandler
如果当前语句采用的是 PreparedStatement。那么在执行前需要为语句中的每个 ? 设置对应的值,而 DefaultParameterHandler 的作用就是如此。代码实现如下:
所有成员变量
// 类型处理器注册表
private final TypeHandlerRegistry typeHandlerRegistry;
// 映射语句用于存储数据库操作节点的信息
private final MappedStatement mappedStatement;
// 参数对象
private final Object parameterObject;
// BoundSql对象(包含SQL语句、参数、实参信息)
private final BoundSql boundSql;
// 全局配置信息
private final Configuration configuration;
设置参数的代码实现如下:
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
// 从 BoundSql 中得到请求参数映射列表
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// ParameterMode.OUT 只用于 CallableStatement
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
// 取出属性名称
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
// 从附加参数中获取属性值,附加参数有如下两个来源
// 1. 动态SQL中生成的参数,<foreach> 中声明的{index} 或者{item}
// 2. 通过 <bind> 直接添加的参数
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
// 参数对象有指定的 typeHandler,则参数值就是对象本身
value = parameterObject;
} else {
// 参数对象是复杂类型,取出参数对象的该属性值
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 确定该参数的处理器
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
// 此方法最终根据参数类型,调用java.sql.PreparedStatement类中的参数赋值方法,对SQL语句中的参数赋值
typeHandler.setParameter(ps, i + 1, value, jdbcType);
}
}
}
}
Mybatis 构建一个可执行 SQL 的主线流程
已经讲了那么多篇文章了,其实我们已经将 Mybatis 如何构建一个可执行 SQL 的主线流程的各个步骤都讲到了,不过由于之前都是零散的,所以在这里我们会集中的分析这一流程。
首先我们先看下面的这个图,从这张图中我们可以清晰的看出,从解析配置文件开始到得到一条可执行的 SQL 的过程经历了哪些流程。
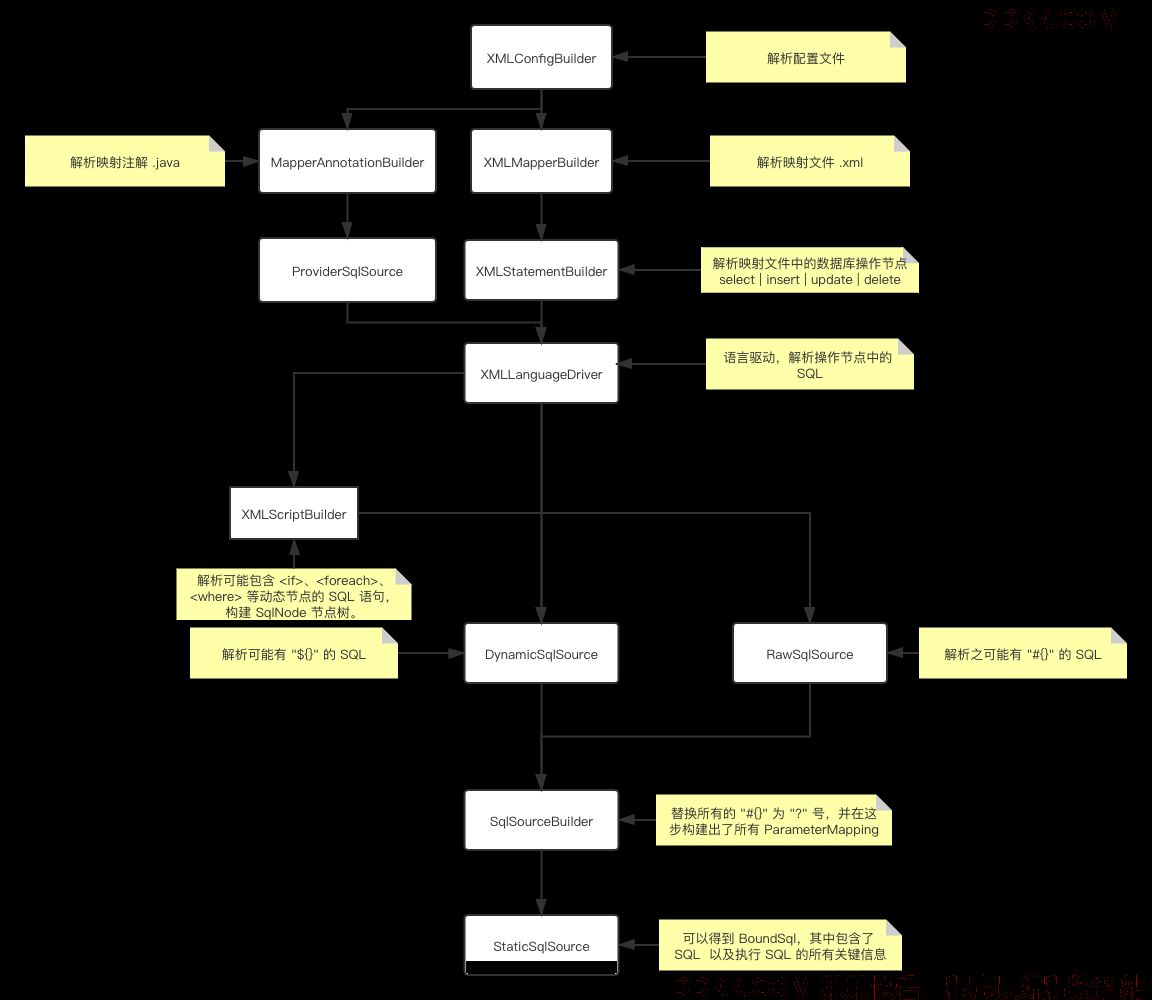
其中大部分的类我们都有讲到,现在我们重点关注其中出现的各个 SqlSource。
ProviderSqlSource
只有在映射方法上声明了 XXXProvider 注解时才会使用到它,它会调用对应的 Provider 方法,得到 Sql 语句,然后调用 LanguageDriver。代码的实现如下:
@Override
public BoundSql getBoundSql(Object parameterObject) {
SqlSource sqlSource = createSqlSource(parameterObject);
return sqlSource.getBoundSql(parameterObject);
}
// 创建 SqlSource
private SqlSource createSqlSource(Object parameterObject) {
/* 1. 得到 SQL 语句 */
String sql;
// 如果请求参数为 Map 类型
if (parameterObject instanceof Map) {
int bindParameterCount = providerMethodParameterTypes.length - (providerContext == null ? 0 : 1);
// 排除 ProviderContext 只有一个参数,并且参数的类型也是 Map 类型,则封装到 Object[] 中然后调用方法
if (bindParameterCount == 1
&& providerMethodParameterTypes[Integer.valueOf(0).equals(providerContextIndex) ? 1 : 0].isAssignableFrom(parameterObject.getClass())) {
sql = invokeProviderMethod(extractProviderMethodArguments(parameterObject));
}
else {
// 尝试从 Map 的内容中构建出 ProviderMethod 的请求参数
@SuppressWarnings("unchecked")
Map<String, Object> params = (Map<String, Object>) parameterObject;
sql = invokeProviderMethod(extractProviderMethodArguments(params, providerMethodArgumentNames));
}
}
// 没有声明入参,直接无参调用
else if (providerMethodParameterTypes.length == 0) {
sql = invokeProviderMethod();
}
// 只有一个入参的
else if (providerMethodParameterTypes.length == 1) {
// 如果不是传递 ProviderContext,则传递请求参数过去
if (providerContext == null) {
sql = invokeProviderMethod(parameterObject);
}
// 如果是声明的 ProviderContext,则传递 ProviderContext
else {
sql = invokeProviderMethod(providerContext);
}
}
// 如果声明了两个入参
else if (providerMethodParameterTypes.length == 2) {
sql = invokeProviderMethod(extractProviderMethodArguments(parameterObject));
} else {
throw new BuilderException("Cannot invoke SqlProvider method '" + providerMethod
+ "' with specify parameter '" + (parameterObject == null ? null : parameterObject.getClass())
+ "' because SqlProvider method arguments for '" + mapperMethod + "' is an invalid combination.");
}
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
/* 2. 调用 LanguageDriver 得到 SqlSource */
return languageDriver.createSqlSource(configuration, sql, parameterType);
}
DynamicSqlSource
如果SQL 中有 ${} 或者有 、 等节点时会使用当前类。关键代码如下:
@Override
public BoundSql getBoundSql(Object parameterObject) {
// 构建动态上下文
DynamicContext context = new DynamicContext(configuration, parameterObject);
rootSqlNode.apply(context);
// 替换 SQL 中的{},并构建对应的 ParameterMapping,生成最终的 StaticSqlSource
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
// 得到 StaticSqlSource
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
// 得到 BoundSql
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
// 由于可能包含动态节点,所以要将动态节点生成的变量添加到 BoundSql 的附加参数上
// 在实际执行时可能会用到
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}
RawSqlSource
如果 SQL 中只可能有 “#{}” 的话,则会使用当前类。代码如下:
public class RawSqlSource implements SqlSource {
private final SqlSource sqlSource;
public RawSqlSource(Configuration configuration, SqlNode rootSqlNode, Class<?> parameterType) {
this(configuration, getSql(configuration, rootSqlNode), parameterType);
}
public RawSqlSource(Configuration configuration, String sql, Class<?> parameterType) {
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> clazz = parameterType == null ? Object.class : parameterType;
// 解析生成 StaticSqlSource
sqlSource = sqlSourceParser.parse(sql, clazz, new HashMap<>());
}
// 得到 Sql 语句
private static String getSql(Configuration configuration, SqlNode rootSqlNode) {
// 由于 SqlNode 中不包含动态节点或者 "${}",所以不需要入参就能构建出 Sql 语句
DynamicContext context = new DynamicContext(configuration, null);
rootSqlNode.apply(context);
return context.getSql();
}
@Override
public BoundSql getBoundSql(Object parameterObject) {
return sqlSource.getBoundSql(parameterObject);
}
}
StaticSqlSource
当前类中保存的 SQL 就是能直接交给数据库执行的 SQL 语句了。已经替换掉了所有动态语句、${}、#{},能直接构建出 BoundSql 不需要再借用其他的 SqlSource 实现类。代码如下:
public StaticSqlSource(Configuration configuration, String sql, List<ParameterMapping> parameterMappings) {
this.sql = sql;
this.parameterMappings = parameterMappings;
this.configuration = configuration;
}
@Override
public BoundSql getBoundSql(Object parameterObject) {
return new BoundSql(configuration, sql, parameterMappings, parameterObject);
}
DynamicSqlSource 和 RawSqlSource 的区别
其实细心的小伙伴可能发现 DynamicSqlSource 和 RawSqlSource 的执行步骤都是差不多的。
1、 构建出DynamicSqlSource;
2、 让所有的SqlNode进行处理rootSqlNode.apply(context);;
3、 利用SqlSourceBuilder解析SQL并构建出StaticSqlSource;
4、 得到BoundSql;
但是为什么会划分出两个不同的类,主要是根据 SqlNode 处理过程是否需要请求参数,导致 1、2、3 步骤的执行时期不同。
如果节点中包含动态节点的话 SqlNode 的处理必须要请求参数的参与,但是调用 getBoundSql 才会传递请求参数进来,所以所有的步骤都必须要在调用 getBoundSql 才能执行。
但是如果节点中没有动态节点的话,可以将 1、2、3 步骤提前到构建 StaticSqlSource 时。那么在调用 getBoundSql 时就只剩最后一个步骤需要执行。
注:SqlSource 是可以进行复用的,一条SQL都有唯一的 SqlNode 从解析完成时就已经决定下来了。但是 BoundSql 是会根据请求参数的不同发生变化的。
小结:RawSqlSource 的执行效率高于 DynamicSqlSource,但是 RawSqlSource 的灵活性小于 DynamicSqlSource。