04、MyBatis 源码分析 - exceptions 包
源码的分析顺序是和《通用源码阅读指导书:Mybatis源码详解》保持一致的,也就是因为看了这本书写者才下定决心要写这个系列。
名称为 XXX 包,但是实际上在分析的时候可能会有在 XXX 包之外的内容,原因也在之前的文章中提到了,因为类所属包的划分规则不是固定的,之后的文章就不在重复说这一点。
阅前思考
包名称是 exceptions,说明是和异常有关的。粗略看包中的类,有框架中要用的自定义异常和异常相关的辅助类。
为什么需要自定义异常
不知道大家有没有想过为啥需要自定义异常,都抛出 Exception 或者 RuntimeException 不好吧,多省心呀(由于英语不好,写者经常纠结于各种命名)。
存在即合理,那么我们就看看为什么需要自定义异常。
1、 让异常更便于理解:就以常见NullPointerException为例,如果在一处地方抛出了Exception那么我们可能就不能一眼看出到底是什么引发的这个异常;
2、 可以针对性的处理:有些异常是我们可以预见的,在Java里面就是受检异常,我们知道有哪些异常会发生,然后我们就可以针对某一个感兴趣的异常去处理例如:发生业务相关异常的时候,我们就需要将异常信息封装然后返回给前端如果发生了未知的异常或者系统级的异常,那么我们就需要将返回一个公共的信息‘服务器异常,请联系管理员’这种,我们不能让用户看到很长一串的异常信息,这样用户体验会很差,用户也看不懂;
Mybatis 异常体系
Mybatis 异常结构图(看不清楚可以放大)

最顶层的是 PersistenceException,Mybatis 中所有的异常都继承了它(当然了不是所有的异常都在 exceptions 包下,而是各个包可能都存在)。可以发现 Mybatis 异常划分是非常细的,说明 细致的划分异常是非常重要的(毕竟优秀的开源框架都这么干)。
ExceptionFactory
在exceptions 包下还有一个 ExceptionFactory,最开始看到时还是非常好奇的,毕竟创建异常还需要弄一个工厂类出来吗,不是直接 new 就好了吗。
public class ExceptionFactory {
private ExceptionFactory() {
// 由于 ExceptionFactory 只有静态方法,所以不需要实例化
}
public static RuntimeException wrapException(String message, Exception e) {
return new PersistenceException(ErrorContext.instance().message(message).cause(e).toString(), e);
}
}
我们可以看到这个类中只有一个方法也就是 wrapException(),随便查看一处方法的调用处的代码(Mac 下是 alt + 鼠标左键方法名称,可以查看方法的调用情况)
// SqlSessionFactoryBuilder
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
// 资源回收
}
}
我们可以看到,在捕获到异常以后,就将这个异常包装为一个 PersistenceException 再抛出去,可以看出这是将一个受检异常转换为了一个非受检异常。并且发现在 wrapException 中还做了一些处理,其中使用了 ErrorContext ,它的作用是记录异常信息的,马上我们就会去解析它。
由此我们可以推断出 ExceptionFactory 的功能:将受检异常转换为了非受检异常、收集详细的异常信息。
ErrorContext
从字面上来看,是错误上下文的意思。一般来说异常信息和调用栈类似,层层深入,所以可能某一个地方发生了异常却可能会打印很长一串的信息,因为只要异常没有被捕获就会被一直向上抛出。
所以从异常信息我们其实是可以看出来,在调用哪个方法时,发生了什么异常,不过并不知道异常发生的上下文,可以简单的理解为请求参数,你顶多只知道当前方法的请求参数,但是不知道调用者的请求参数是啥。
例如下图:
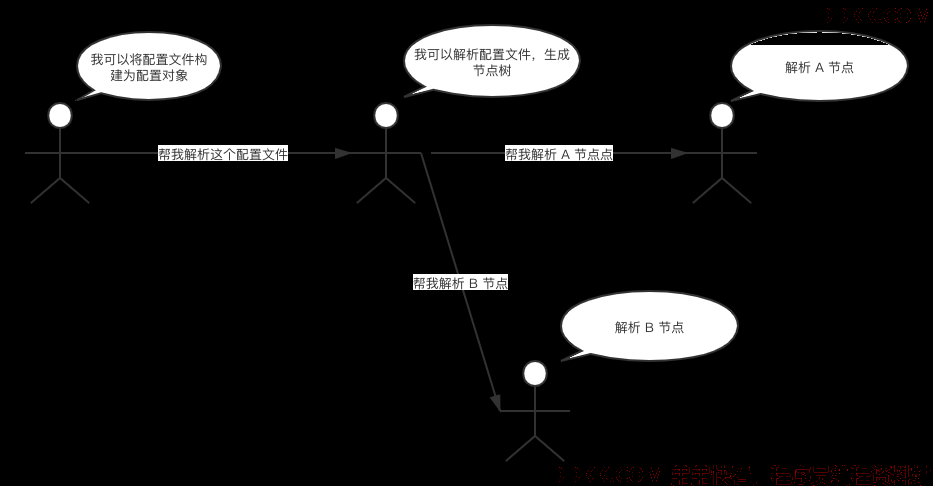
如果是普通的异常记录方式,在解析 B 节点的时候发生了异常,那么我们抛出 new Exception("解析 B 节点时发生了异常,格式不正确"); 那么如果有很多类似的配置文件都需要解析,难道我们每个都要去查看一下是不是格式有问题吗。但是如果我们在每个步骤都记录了相关信息,那么我们就可以看到这种信息 构建配置文件,解析配置文件 xxx.xml 中 B 节点时发生了异常,格式不正确 那么我们就可以很快找到问题的所在。
ErrorContext 的作用就是如此,在每个步骤都记录一点信息,再最后拼接起来(所以信息记录的顺序不重要),当出现异常的时候就能立马找到问题所在了。
代码分析
一般在进行代码分析的时候,我们不会把所有代码都贴出来,而是只贴出来我认为可能不太容易理解的部分,如果对其他内容感兴趣的话,大家可以自己去看完整的代码。并且基础的 Java 工具类我也不会在这里去解析它的作用,如果大家有兴趣去 google 一下更快。
public class ErrorContext {
// 每个线程都持有一个 ErrorContext,防止出现并发问题
private static final ThreadLocal<ErrorContext> LOCAL = ThreadLocal.withInitial(ErrorContext::new);
// 暂存的 ErrorContext
private ErrorContext stored;
// 一些记录的信息
...
/*
功能:暂存当前的 ErrorContext,类似于线程切换时,暂存上下文
例如,当在执行主分支的时候,要去执行一个重要的子分支,
并且子分支的异常体系是独立于主分支的,也就是可能出现子分支的异常会覆盖主分支的异常。
为了避免这种情况,就执行前,我们需要将主分支的内容先暂存起来,避免出现了混乱。
*/
public ErrorContext store() {
ErrorContext newContext = new ErrorContext();
newContext.stored = this;
LOCAL.set(newContext);
return LOCAL.get();
}
/*
功能:取出暂存的 ErrorContext,类似于线程切换回来时,恢复上下文
例如,子分支执行结束后,要恢复到主分支的运行状态,就需要将暂存的内容启用。
*/
public ErrorContext recall() {
if (stored != null) {
LOCAL.set(stored);
stored = null;
}
return LOCAL.get();
}
...
}