33、JVM 调优实战 - 如何查看JVM的Full GC日志
1. 示例代码
package com.webcode;
public class Demo4 {
public static void main(String[] args){
byte[] array1 = new byte[4 * 1024 * 1024];
array1 = null;
byte[] array2 = new byte[2 * 1024 * 1024];
byte[] array3 = new byte[2 * 1024 * 1024];
byte[] array4 = new byte[2 * 1024 * 1024];
byte[] array5 = new byte[128 * 1024];
byte[] array6 = new byte[2 * 1024 * 1024];
}
}
2. GC日志
采用如下JVM参数来运行上述程序:
-XX:NewSize=10485760 -XX:MaxNewSize=10485760 -XX:InitialHeapSize=20971520 -XX:MaxHeapSize=20971520 -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 -XX:PretenureSizeThreshold=3145728 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
这里最关键的一个参数,是 “-XX:PretenureSizeThreshold=3145728” ,该参数设置大对象阈值为3MB,也就是超过3MB,就直接进入老年代。
运行之后的GC日志如下:
0.113: [GC (Allocation Failure) 0.113: [ParNew (promotion failed): 7256K->7953K(9216K), 0.0028080 secs]0.116: [CMS: 8194K->6805K(10240K), 0.0035630 secs] 11352K->6805K(19456K), [Metaspace: 2644K->2644K(1056768K)], 0.0068409 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Heap
par new generation total 9216K, used 2130K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
concurrent mark-sweep generation total 10240K, used 6805K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 2651K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 286K, capacity 386K, committed 512K, reserved 1048576K
3. 日志分析
首先看如下代码:
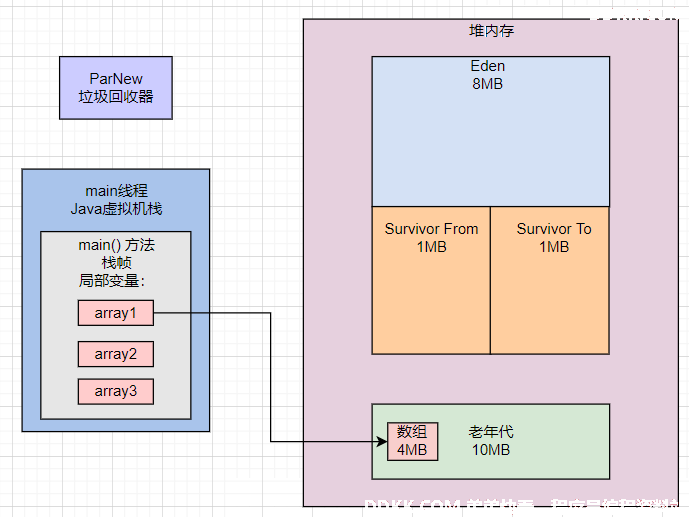
byte[] array1 = new byte[4 * 1024 * 1024];
array1 = null;
这行代码直接分配了一个4MB的大对象,此时这个对象会直接进入老年代,接着array1不再引用这个对象。
如下图所示:
接着看如下代码:
byte[] array2 = new byte[2 * 1024 * 1024];
byte[] array3 = new byte[2 * 1024 * 1024];
byte[] array4 = new byte[2 * 1024 * 1024];
byte[] array5 = new byte[128 * 1024];
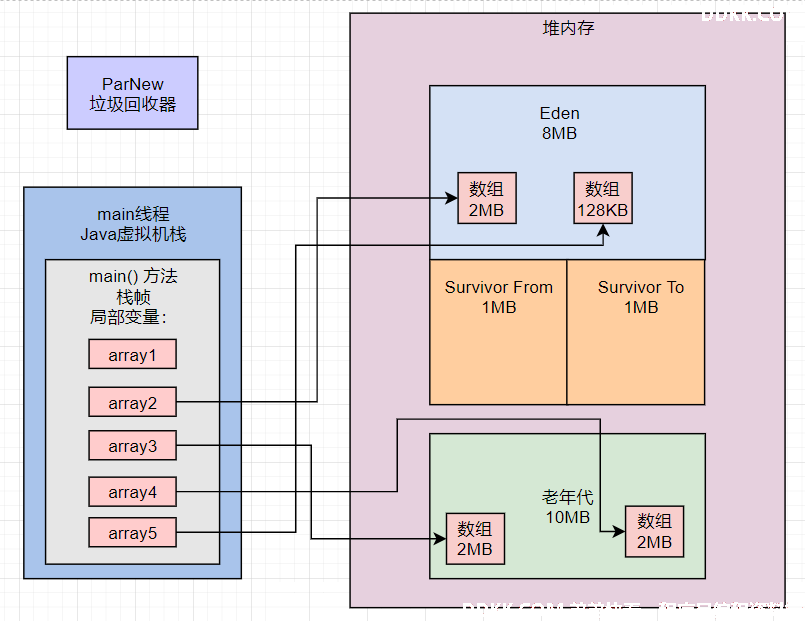
连续分配了4个数组,其中3个是2MB的数组,1个是128KB的数组,如下图所示,全部会进入Eden区域中。

接着会执行如下代码:byte[] array6 = new byte[2 * 1024 * 1024];。
因为Eden 区已经放不下了,所以此时会触发一次Young GC。对应的GC日志如下:
ParNew (promotion failed): 7256K->7953K(9216K), 0.0028080 secs
这行日志显示,Eden区原来有700多KB的对象,但是回收之后发现一个都回收不掉,因为都被变量引用了。
所以,正常来说一定会直接把这些对象放入到老年代里去,但是此时老年代已经有一个4MB的数组了,不能再放下3个2MB的数组和1个128KB的数组。
接着有如下GC日志:
[CMS: 8194K->6805K(10240K), 0.0035630 secs] 11352K->6805K(19456K), [Metaspace: 2644K->2644K(1056768K)], 0.0068409 secs]
上述日志,说明执行了CMS垃圾回收器的Full GC。也就是对老年代进行Old GC,同时一般会跟一次Young GC关联,并触发一次元数据区(永久代)的GC。
在CMS Full GC之前,就已经触发过Young GC了,此时可以看到Young GC已经有了,接着就是执行针对老年代的Old GC,如下GC日志:
CMS: 8194K->6805K(10240K), 0.0035630 secs
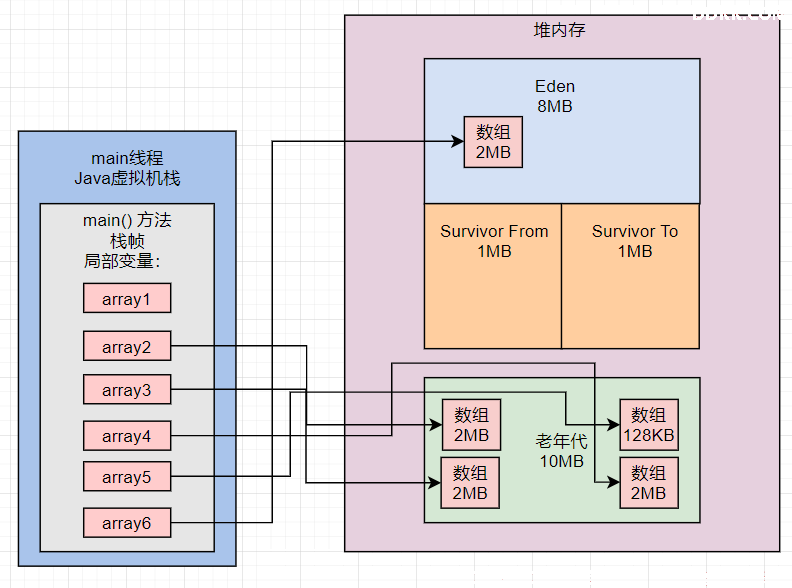
这里看到老年代从8MB左右的对象占用,变成了6MB多的对象占用。这个过程是,在Young GC之后,先把2个2MB的数组放入了老年代,如下图:

此时要继续放1个2MB的数组和1个128KB的数组到老年代,一定会放不下,所以就会触发CMS的Full GC。从而回收掉其中的一个4MB的数组,因为它没有引用了。
接着放入一个2MB的数组和1个128KB的数组,如下图所示:

再结合CMS的垃圾回收日志: CMS: 8194K->6805K(10240K), 0.0035630 secs ,它是从回收前的8MB变成了6MB。
最后在CMS Full GC执行完毕之后,年轻代的对象都进入了老年代,此时最后一行代码要在年轻代分配2MB的数组就可以成功了。
4.深入解析
1、 4MB的大对象Array1给分配内存空间时直接进入老年代,此时不会有GC。因为老年代10M可连续的空闲空间;
2、 当年轻代Eden区域分配完3个2M和1个128K对象后,当分配第四个2M对象时。此时Eden空间不够导致分配失败,触发Minor GC,此时新生代存活的对象6M+128K大于老年代的可用连续空间,但是老年代可用连续空间大于历代新生代进入老年代对象的平均大小0,所以分配担当成功,不需要触发Full GC执行Minor GC;
3、 执行Minor GC年轻代6M+128K对象都存活,但是S0只有1M空间导致存活对象进入老年代;
4、 年轻代先将活着的两个2M对象和128K的对象放入老年代,此时老年代8M+128K,当分配最后一个2M对象触发Full GC,因为可用连续空间小于了2M。此时老年代其中4M大对象可回收2个2M对象和1个128K对象不能回收,Full GC回收完4M对象后再将新生代最后活着的2M对象加入到老年代,所以Minor GC时内存空间是没变的。因为对象都活着,Full GC从8M变成6M。
5.总结
上述案例,当年轻代存活的对象太多放不下老年代了,就会触发CMS的Full GC。