3、Hystrix 降级/线程池隔离
思考:当活动服务出现性能问题以后,我们只能眼睁睁看着活动服务被压垮吗?
1、添加@HystrixCommand后,Hystrix是如何实现超时和降级功能?
1、 在某个方法上添加了@HystrixCommand后,该方法会被包裹在Hystrix里,并将该方法放到线程池中类似切面;
**分析:**用户的请求会到达一个带有@HystrixCommand注解的方法,则该方法被放到线程池中进行执行【Hystrix的线程池中默认有10个线程】,该线程池会调用活动服务。
此时如果用户的其他请求到达该另一个被@HystrixCommand修饰的方法时,方法1已经有10个请求占据了10个线程,则方法2的请求会等待。
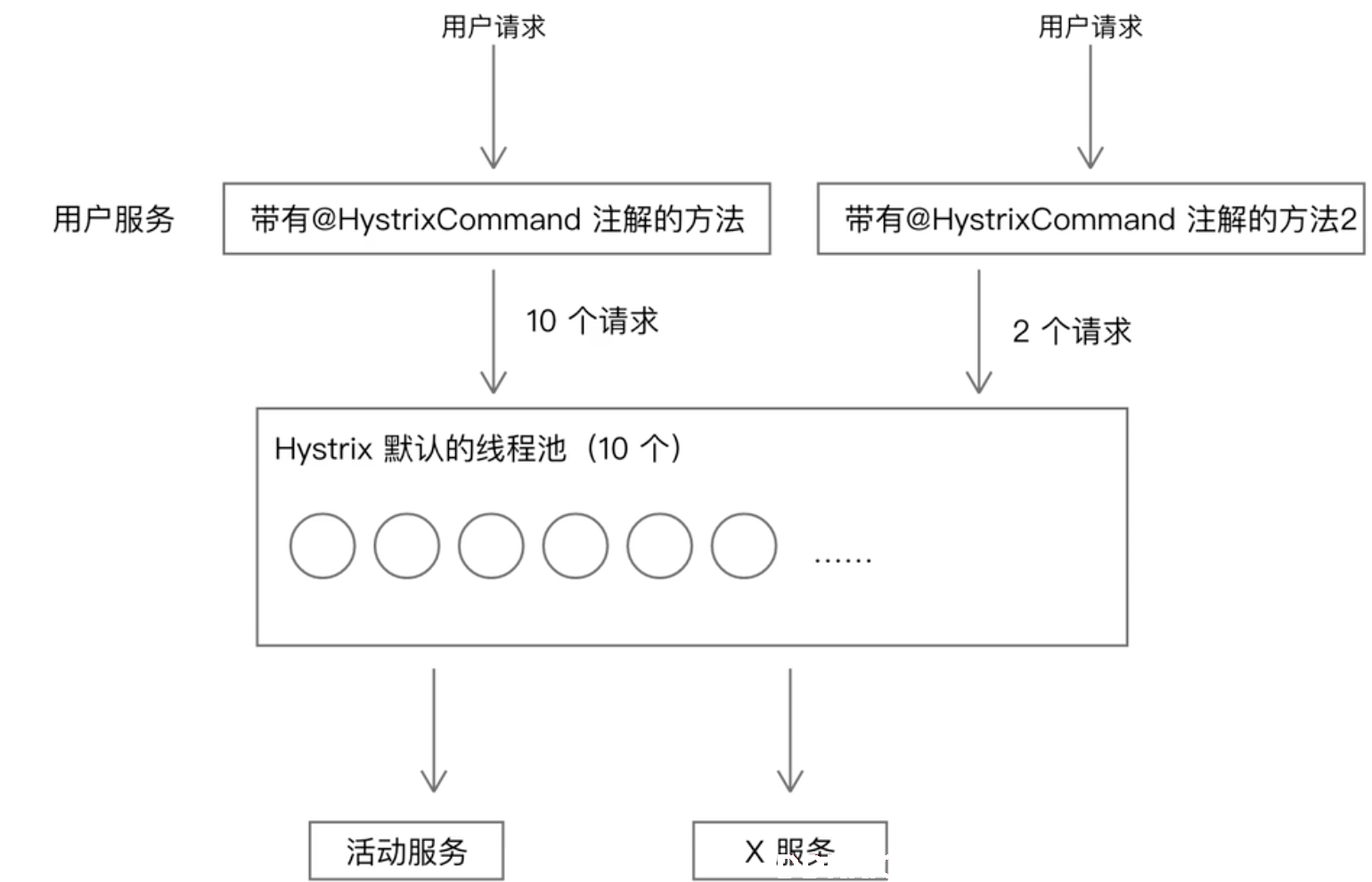
以上模式的问题:所有带有@HystrixCommand注解的方法都用的同一个线程池,而这个线程池的线程数量是有限的,所以,当线程池被方法1占满以后,方法2就无法请求到X服务。
2、 启动服务直观查看线程数量;
2.1、启动

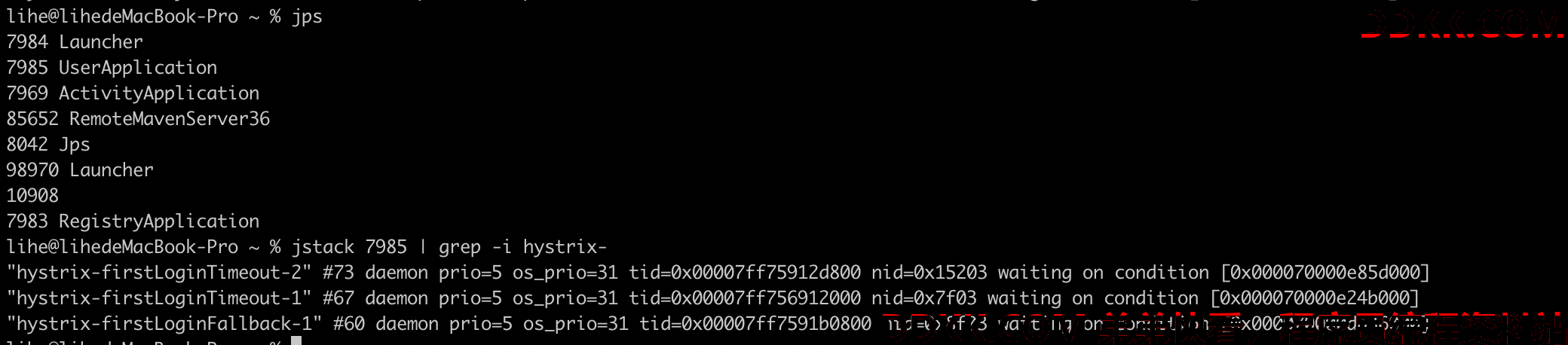
2.2、打印启动的进程。jps:当前用户下的java进程

2.3、进行多次请求fallback接口

2.4、查看线程数。jstack:查看指定进程(pid)的堆栈信息

2.5、多次请求timeout接口

2.6、查看仍只有10个线程

结论:用户请求的两个方法公用一个线程池。此时有性能问题的服务,当请求过多时,会导致正常的服务无法访问。
如何解决这个问题?
1、 增加线程数:不可行,因为如果将线程数从10增加到100,而请求方法1的请求有10000个,此时仍然影响方法2的调用;
2、 方法间的线程池隔离:以下隔离方式Hystrix称为舱壁模式即(bulkhead)![ ][nbsp7];
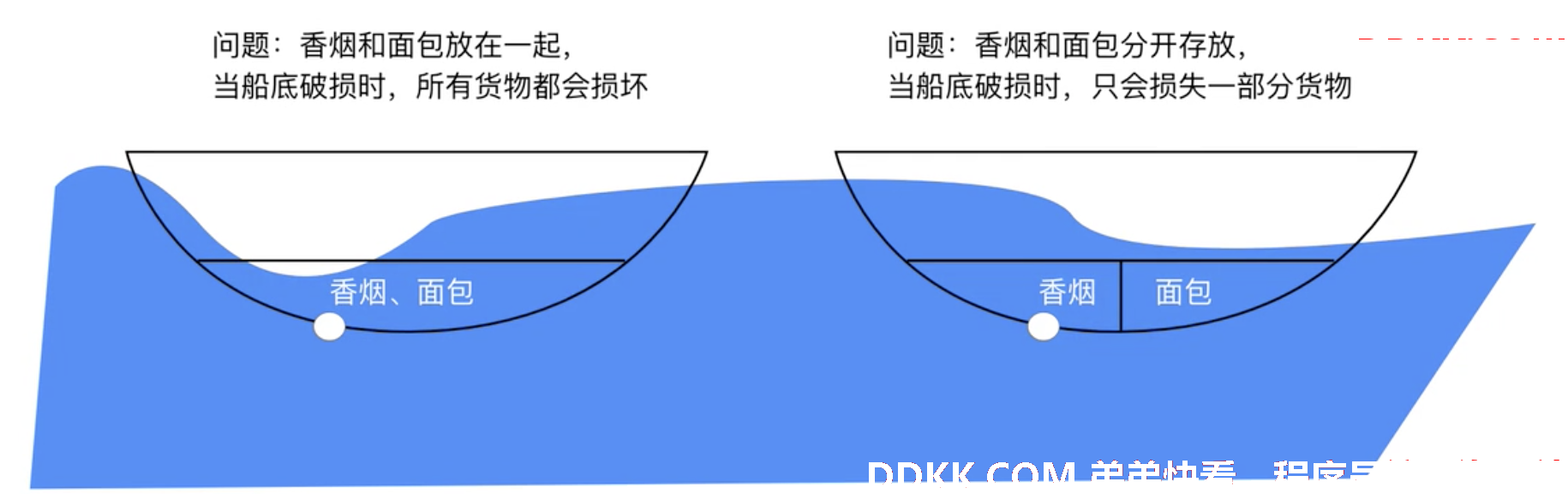
3、线程池隔离
1、 通过使用@HystrixCommand使每个方法单独设置线程池;
@HystrixCommand(
threadPoolKey = "firstLoginFallback",
threadPoolProperties = {
@HystrixProperty(name = "coreSize",value = "1"),
@HystrixProperty(name="maxQueueSize",value = "20")
},
fallbackMethod = "firstLoginFallback0")
@Service
public class ActivityServiceBulkhead {
@Autowired
private RestTemplate restTemplate;
/**
* 调用活动服务,完成初次登陆,奖励发放
**/
public String firstLogin(Long userId){
//使用服务名,实际上Spring会将服务名转为对应ip
return restTemplate.postForObject("http://activity/firstLoginActivity", userId, String.class);
}
/**
* 调用活动服务,完成初次登陆,奖励发放
* 定义超时时间,让用户服务不再等待活动服务的响应
* 这样的话,可以及时释放资源。
* 使用hystrix,设置超时时间超过2s时则不继续等待调用,直接返回
* HystrixThreadPoolProperties类中Setter中(可以进去找配置)
* threadPoolKey:该属性为方法单独定义线程池,当key存在时直接使用定义过的线程池,不存在时新创建线程池
* threadPoolProperties:为线程池定义属性
* coreSize:允许有多少个线程
* maxQueueSize:当线程占满,允许排队的请求数量
**/
@HystrixCommand(
threadPoolKey = "firstLoginTimeout",
threadPoolProperties = {
@HystrixProperty(name = "coreSize",value = "2"),
@HystrixProperty(name="maxQueueSize",value = "20")
},
commandProperties = {
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",value = "2000")
})
public String firstLoginTimeout(Long userId){
//使用服务名,实际上Spring会将服务名转为对应ip
return restTemplate.postForObject("http://activity/firstLoginActivityTimeout", userId, String.class);
}
/**
* 需要提供一个备用方案,当活动服务不可用时,执行备用方案,即降级
**/
@HystrixCommand(
threadPoolKey = "firstLoginFallback",
threadPoolProperties = {
@HystrixProperty(name = "coreSize",value = "1"),
@HystrixProperty(name="maxQueueSize",value = "20")
},
fallbackMethod = "firstLoginFallback0")
public String firstLoginFallback(Long userId){
//使用服务名,实际上Spring会将服务名转为对应ip
return restTemplate.postForObject("http://activity/firstLoginActivityError", userId, String.class);
}
public String firstLoginFallback0(Long userId){
return "活动备用方案--降级";
}
}
2、 启动成功;

3、 发请求;
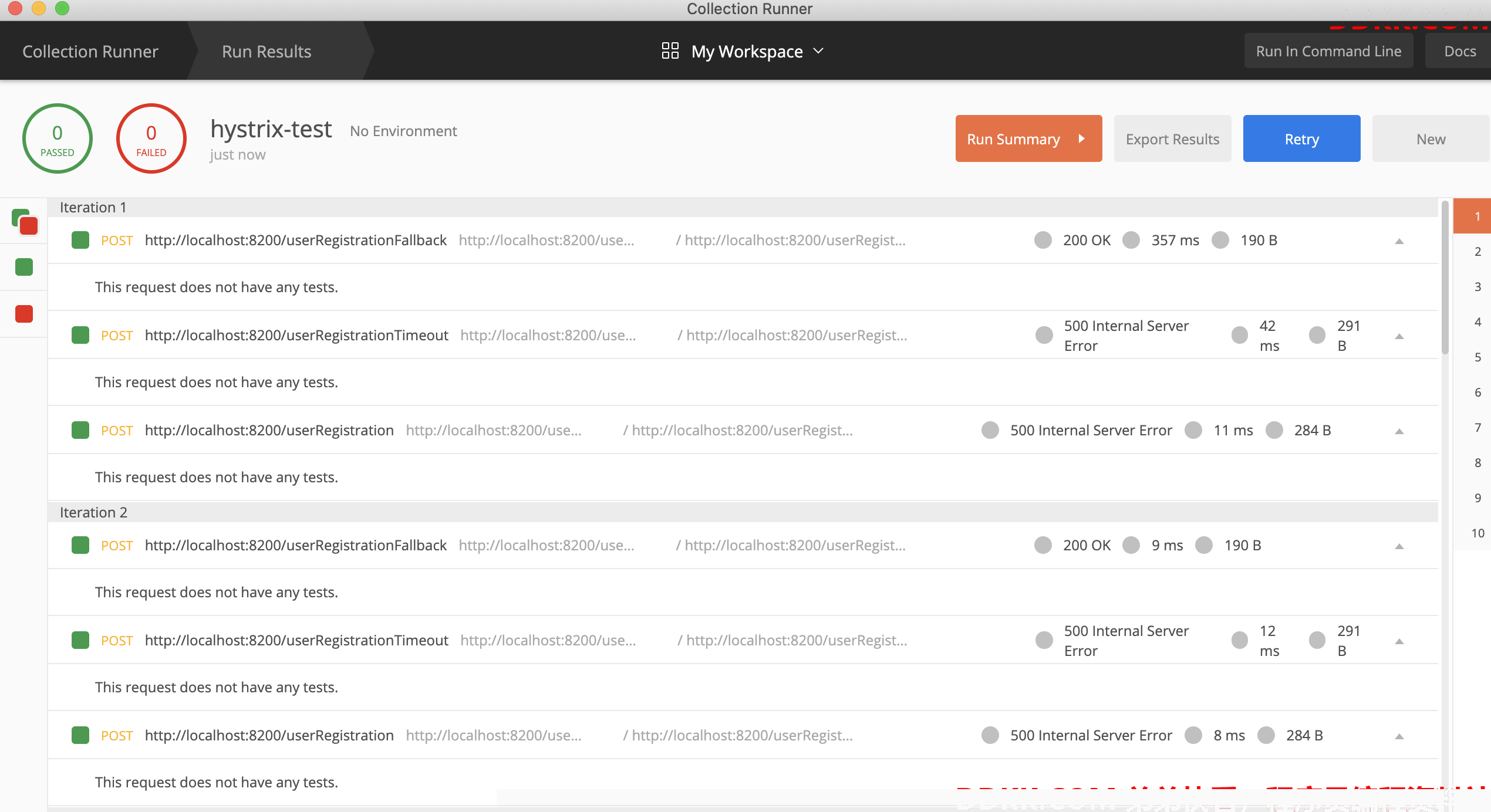
4、 实际线程数:此时只有3个;
4、Hystrix工作流程
思考:当活动服务出现性能问题以后,我们只能眼睁睁看着活动服务被压垮吗?
我们希望是什么样子呢?
如果活动服务出现性能问题,如果用户服务不继续请求,那么活动服务肯定不会被压垮;如果用户服务继续请求,很可能会压垮,而且是无意义的压垮
当调用出现错误时