07、Solr API 使用(分页,高亮)
Solr Deep Paging(深分页)
长期以来,我们一直有一个深分页问题。如果直接跳到很靠后的页数,查询速度会比较慢。这是因为Solr的需要为查询从开始遍历所有数据。直到Solr的4.7这个问题一直没有一个很好的解决方案。直到solr4.7引入了游标才解决这个问题。游标是一个动态结构,不需要存储在服务器上。游标包含了查询的结果的偏移量,因此,Solr的不再需要每次从头开始遍历结果直到我们想要的记录,游标的功能可以大幅提升深翻页的性能。
在第一个查询中,我们需要传递一个额外的参数- cursorMark = *,告诉Solr返回游标。在返回中除了搜索结果,我们还可以得到nextCursorMark信息。
http://192.168.137.168:8080/solr/collection1/select?q=*:*&rows=2&sort=stu_name asc,id asc&cursorMark=*

下一页查询时,使用上一次查询返回的nextCursorMark。
http://192.168.137.168:8080/solr/collection1/select?q=*:*&rows=2&sort=stu_name asc,id asc&cursorMark=AoIlamVycnkqMTAwMDAwMDAwNQ==

高亮
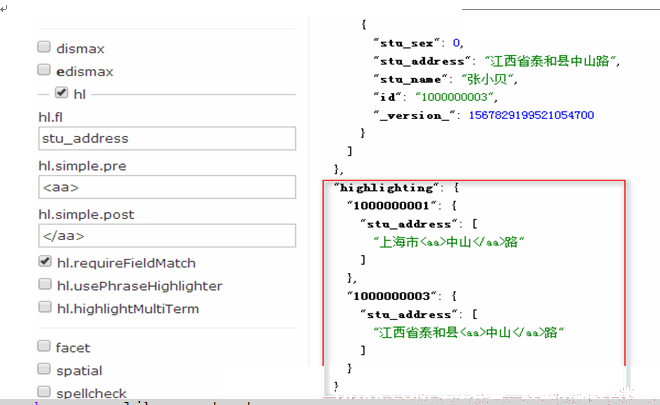
hl是否高亮,hl=true,表示采用高亮
hl.fl 设定高亮显示的字段,用空格或逗号隔开的字段列表。要启用某个字段的highlight功能,就得保证该字段在schema中是stored。如果该参数未被给出,那么就会高亮默认字段,standard查询解析器时,会用df参数,dismax查询解析器时,会用qf参数。你可以使用星号去方便的高亮所有字段。如果你使用了通配符,那么要考虑启用hl.requiredFieldMatch选项。
hl.requireFieldMatch 如果置为true,除非用hl.fl指定了该字段,查询结果才会被高亮。它的默认值是false。
hl.usePhraseHighlighter 如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。
hl.highlightMultiTerm 如果使用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为false,同时hl.usePhraseHighlighter要为true。
hl.fragsize 返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回。
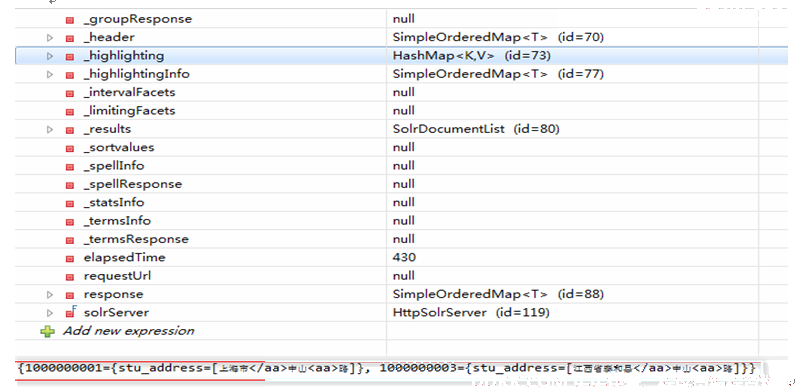
Solr高亮设置后执行查询,其实就是多了highlighting的字段,并没有改变原来返回的字段内容。
SolrJ有三种高亮类型:
如果要对某field做高亮显示,必须对该field设置stored=true
Standard Highlighter,根据查询的docIdSet,获取Documents,并获取当前document的需要高亮的field的value,根据query的term和该field的value做匹配算法
FastVector Highlighter,效率比普通的高亮显示要高;需要定义termvector(占用空间和IO),包括position和offset,根据query term的termvector到field value中做快速的定位标记,进而实现快速的高亮显示
Postings Highlighter,由于高亮显示需要对field设置为store=true,所有对于单节点数据量比较大并且该字段比较大的话,会消耗大量的IO操作,那么可以把该字段存储在另外的地方,比如Hbase,在外部做高亮显示的匹配。
package cn.ljh.ssm.test;
import java.util.List;
import java.util.Map;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.junit.Test;
public class SolrHighlightingTest {
@Test
public void testQueryStudent(){
try {
HttpSolrServer server = HttpSolrServerSingleton.getInstance();
SolrQuery query = new SolrQuery();
query.setQuery("stu_address:中山");
query.setHighlight(true); //开启高亮
query.setHighlightFragsize(10); //返回的字符个数
query.setHighlightRequireFieldMatch(true);
query.setHighlightSimplePost("<aa>"); //前缀
query.setHighlightSimplePre("</aa>"); //后缀
query.setParam("hl.fl", "stu_address"); //高亮字段
QueryResponse req = server.query(query);
SolrDocumentList list= req.getResults();
Map<String, Map<String, List<String>>> map=req.getHighlighting();
for (SolrDocument doc : list) {
System.out.println(map.get(doc.getFieldValue("id").toString()));
}
} catch (SolrServerException e) {
e.printStackTrace();
}
}
}