21、ElasticSearch 实战:分词-分词&安装ik分词
接第20节
4、分词
一个tokenizer (分词器)接收一个字符流,将之分割为独立的 tokens (词元,通常是独立的单词),然后输出 tokens流。
例如,whitespace tokenizer 遇到空白字符时分割文本。它会将文本"Quick brown fox!"分割为[Quick, brown, fox!l。
该tokenizer (分词器)还负责记录各个 term (词条)的顺序或 position位置(用于 phrase短语和 word proximity 词近邻查询) ,以及 term (词条)所代表的原始 word (单词)的 start(起始)和 end (结束)的 character offsets (字符偏移量) (用于高亮显示搜索的内容)。
Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers (自定义分词器) 。
测试ES 默认的标准分词器:
英文:
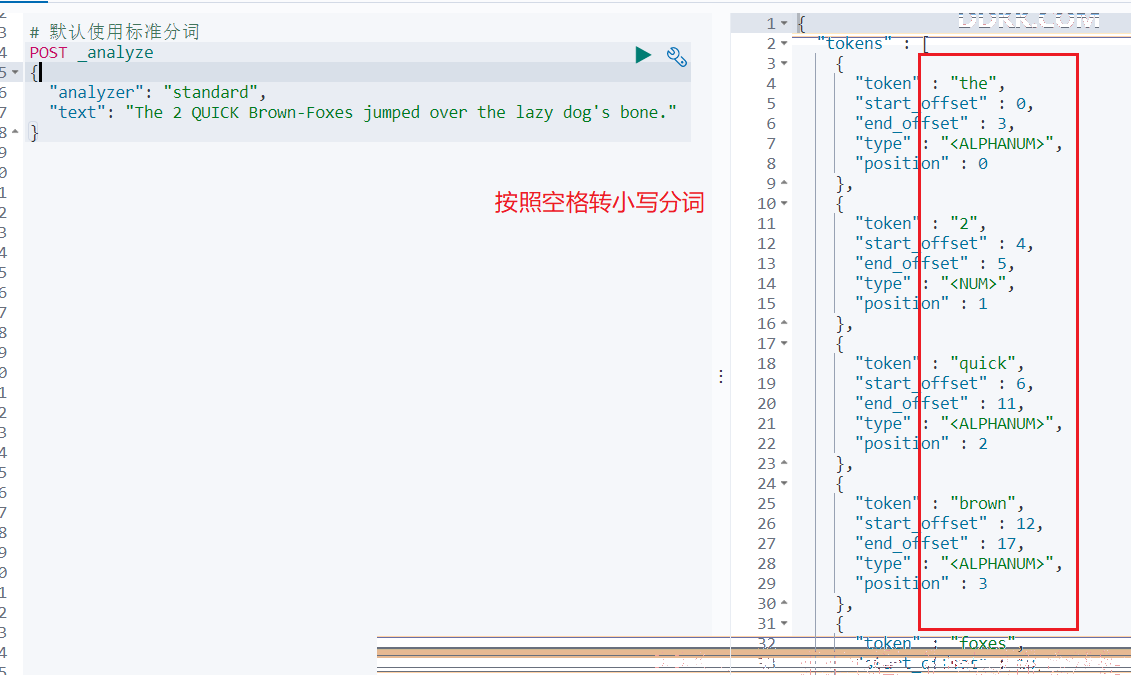
POST _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
中文:
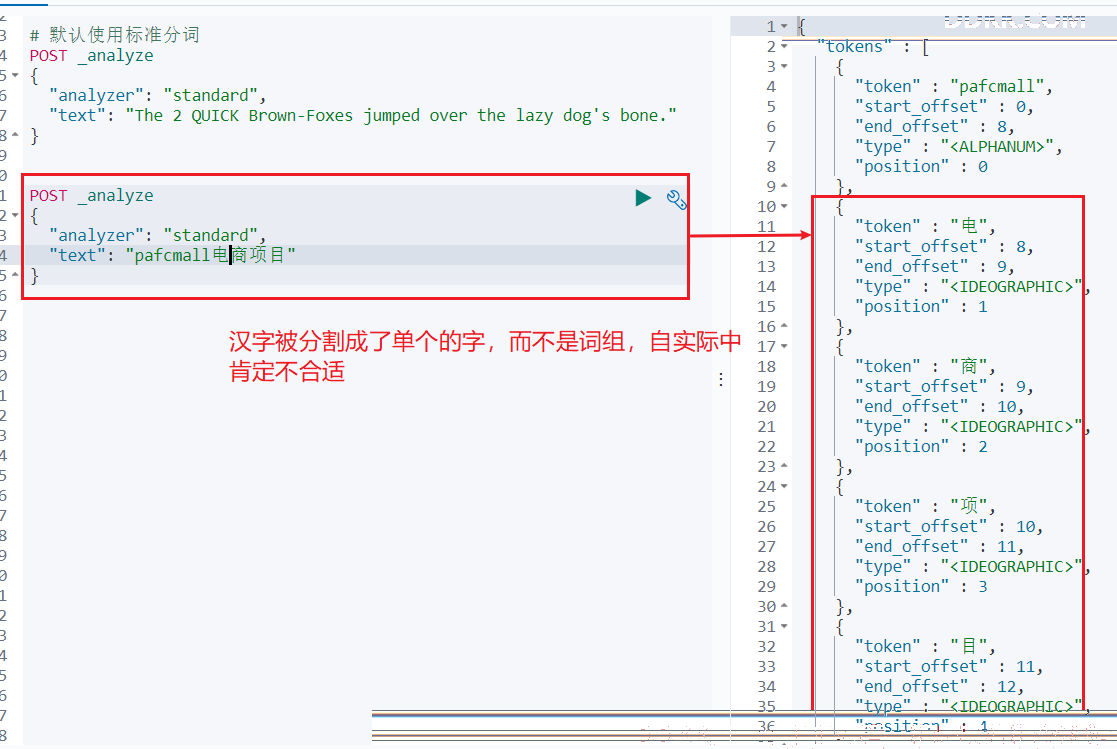
POST _analyze
{
"analyzer": "standard",
"text": "pafcmall电商项目"
}
1)、安装 ik 分词器
注意:不能用默认 elasticsearch-plugin install xxx.zip 进行自动安装
进入https://github.com/medcl/elasticsearch-analysis-ik/releases
找到对应的 es 版本安装
1、 进入es容器内部plugins目录;
docker exec -it 容器id /bin/bash
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
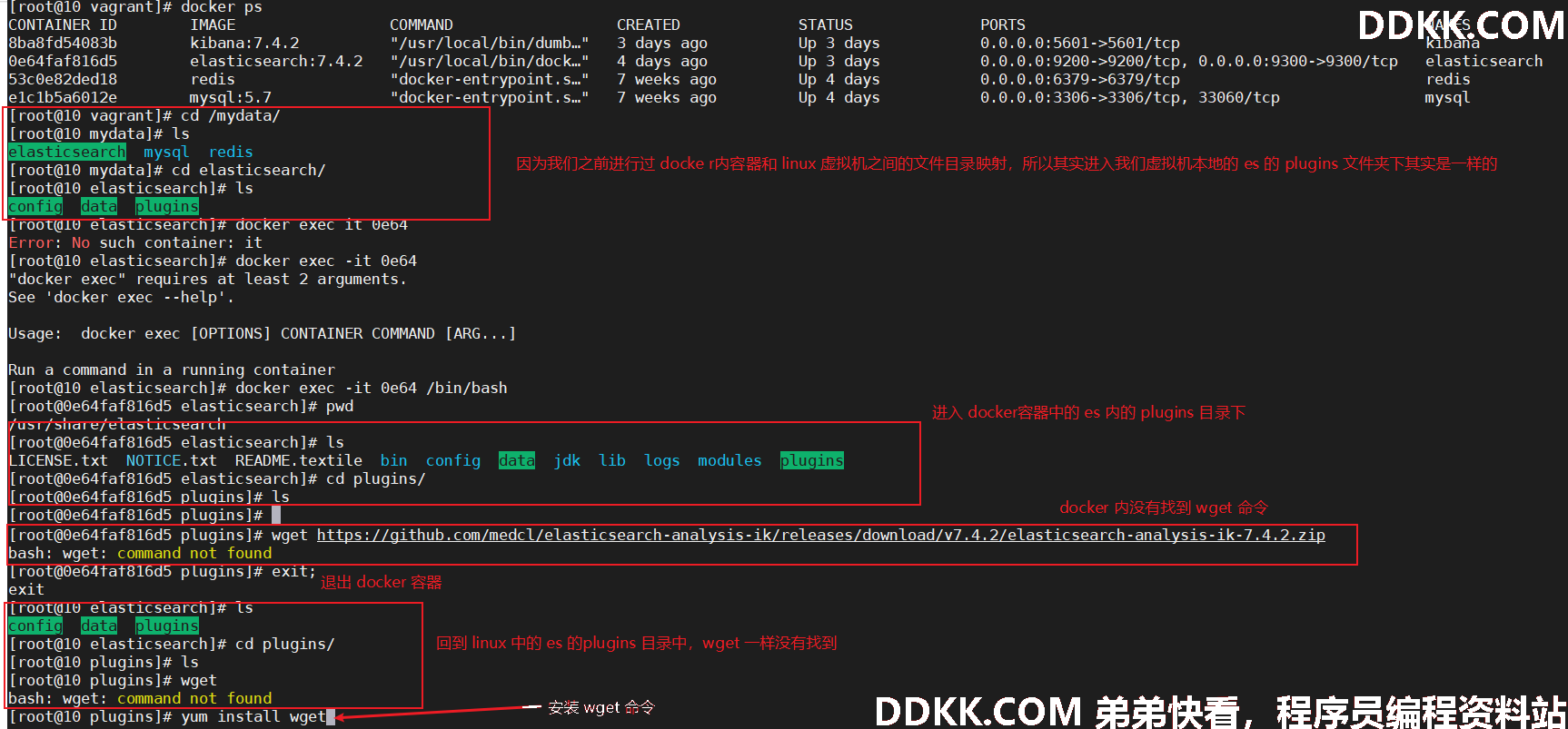
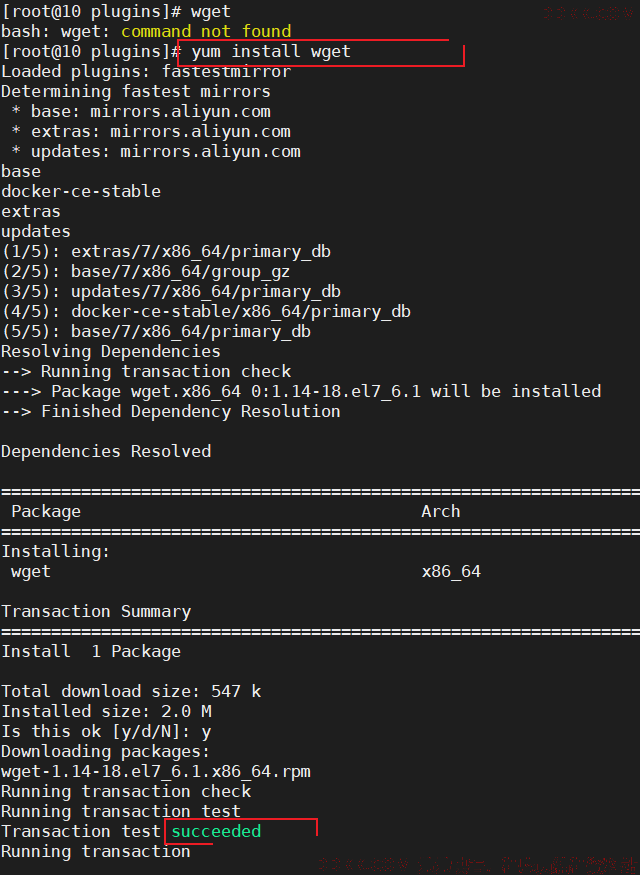
2、 安装wget:;
yum install wget
3、 下载和ES匹配版本的ik分词器:;
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
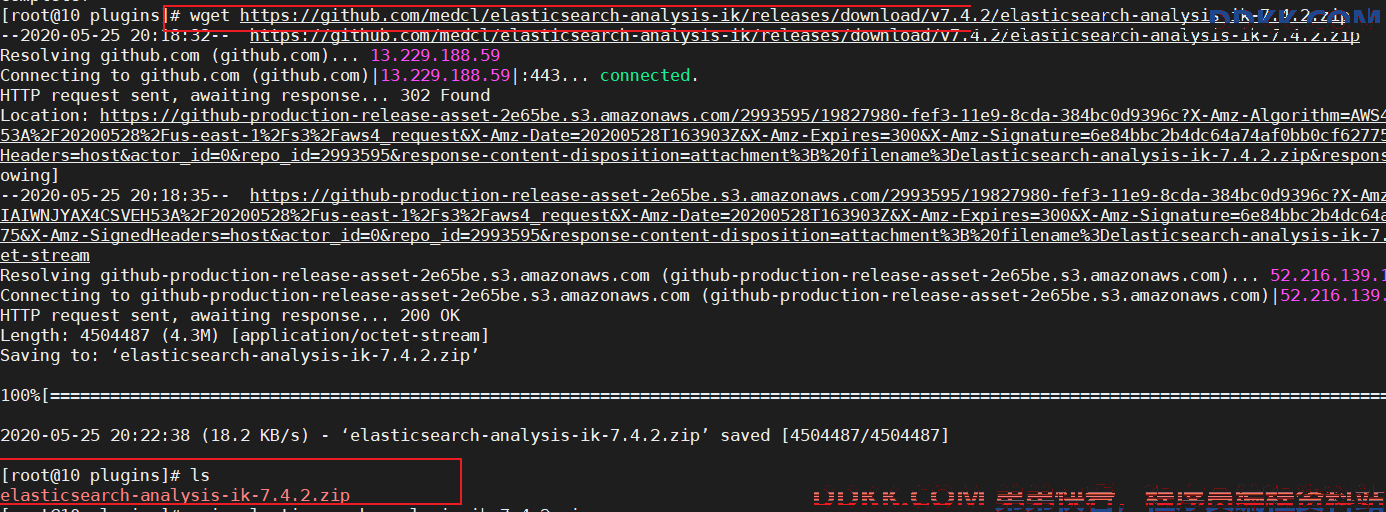
4、 unzip下载文件并解压;
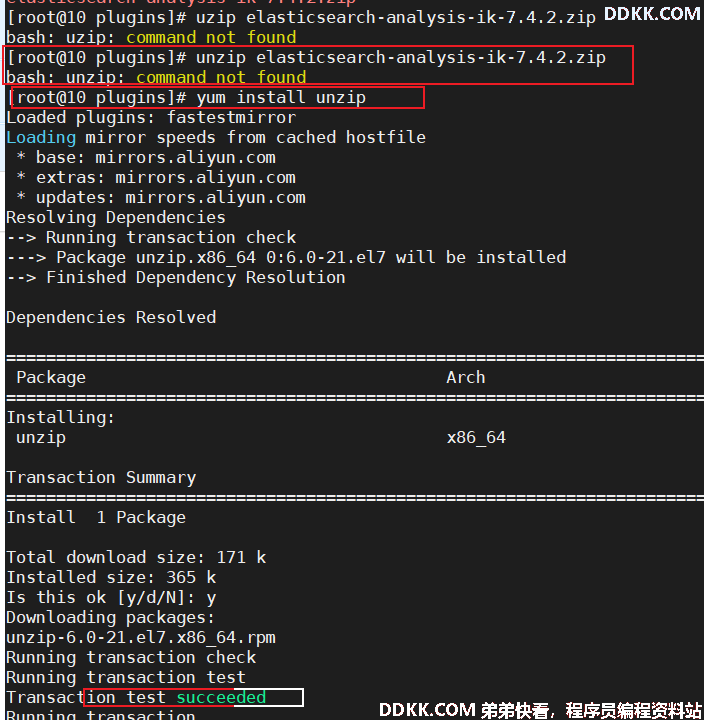
1)、使用 unzip 解压 elasticsearch-analysis-ik-7.4.2.zip 发现 unzip 命令还未安装,先安装 unzip
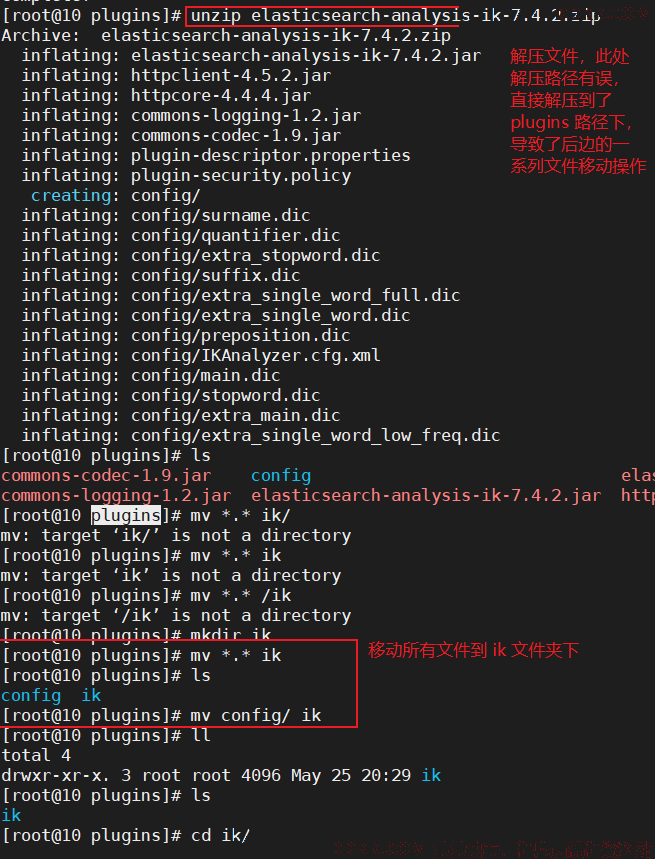
2)、解压文件到 plugins 目录下的 ik 目录
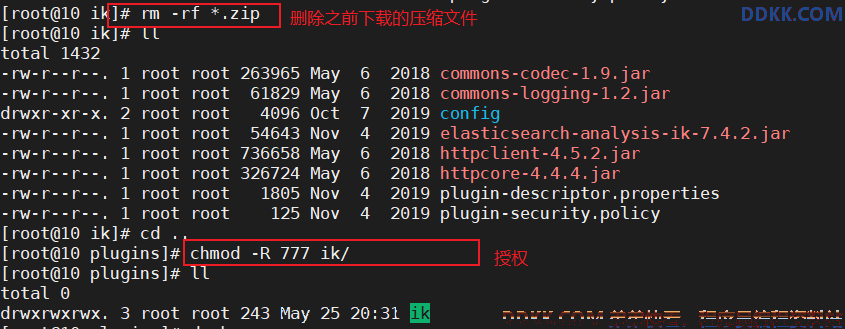
3)删除压缩包,并给 ik 目录及其文件授权
rm -rf *.zip
chmod -R 777 ik/
5、 可以确认是否安装好了分词器;
cd../bin
elasticsearch plugin list:即可列出系统的分词器
1)、进入docker中的es容器内
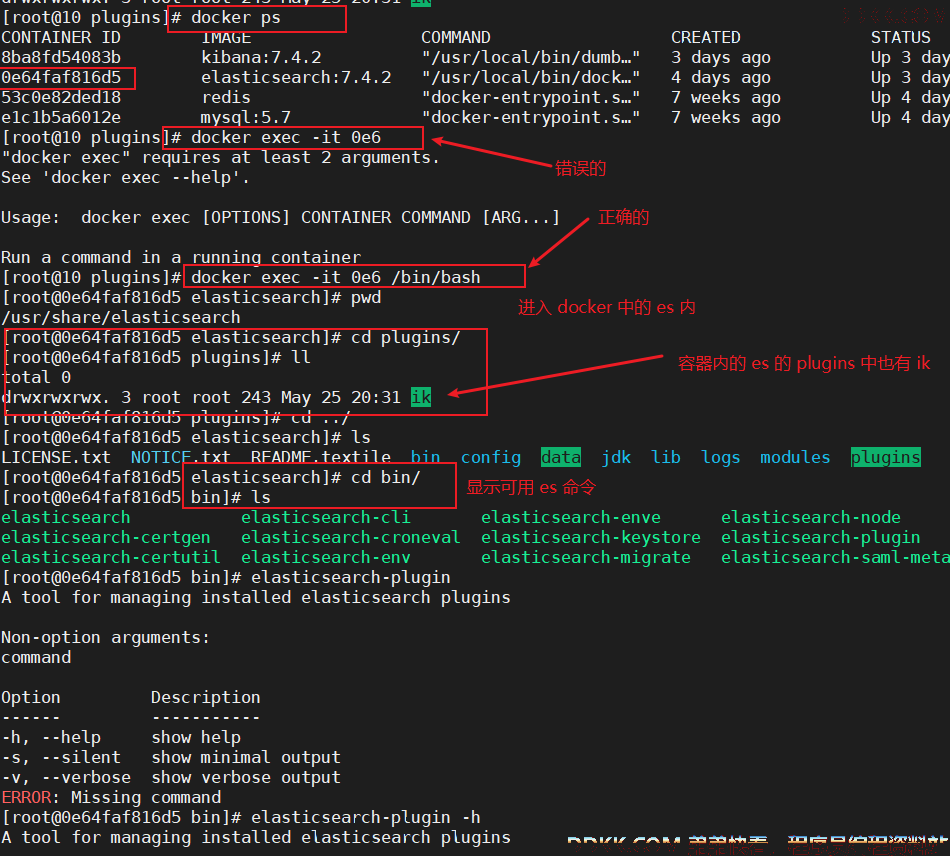
2)、列出系统的分词器

6、 重启ES使ik分词器生效;
docker restart elasticsearch
2)、测试分词器
- 使用默认分词:
POST _analyze
{
"analyzer": "standard",
"text": "pafcmall电商项目"
}
结果: 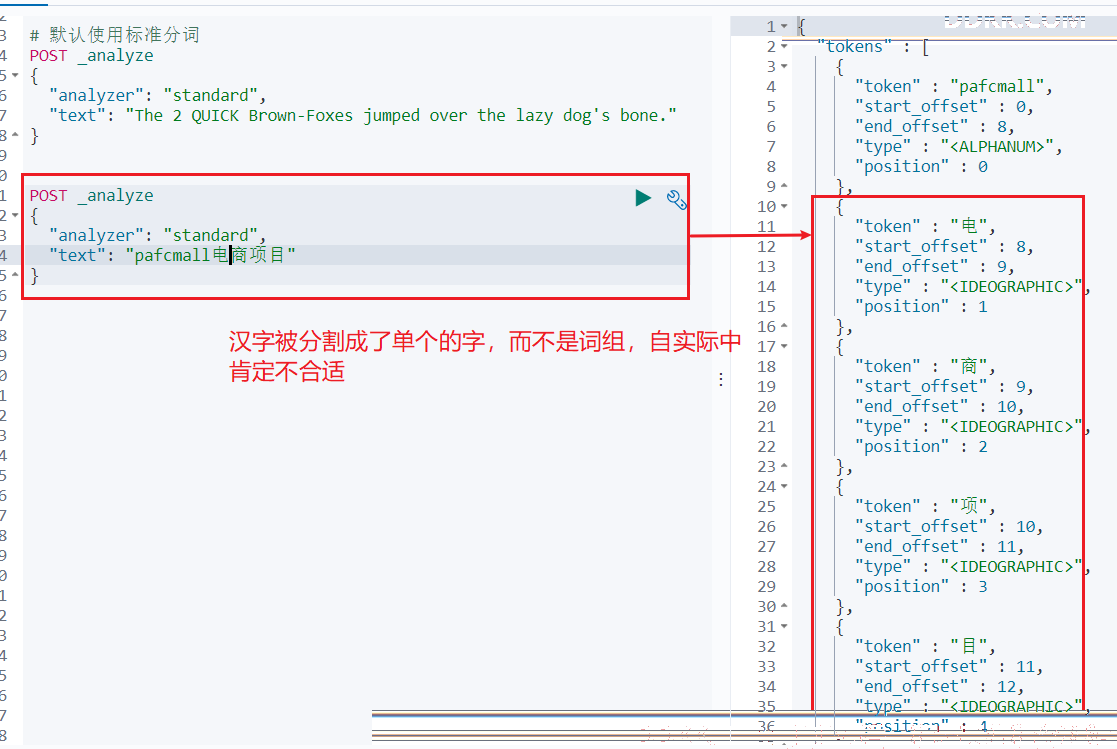
- ik智能分词:
POST _analyze
{
"analyzer": "ik_smart",
"text": "pafcmall电商项目"
}
结果: 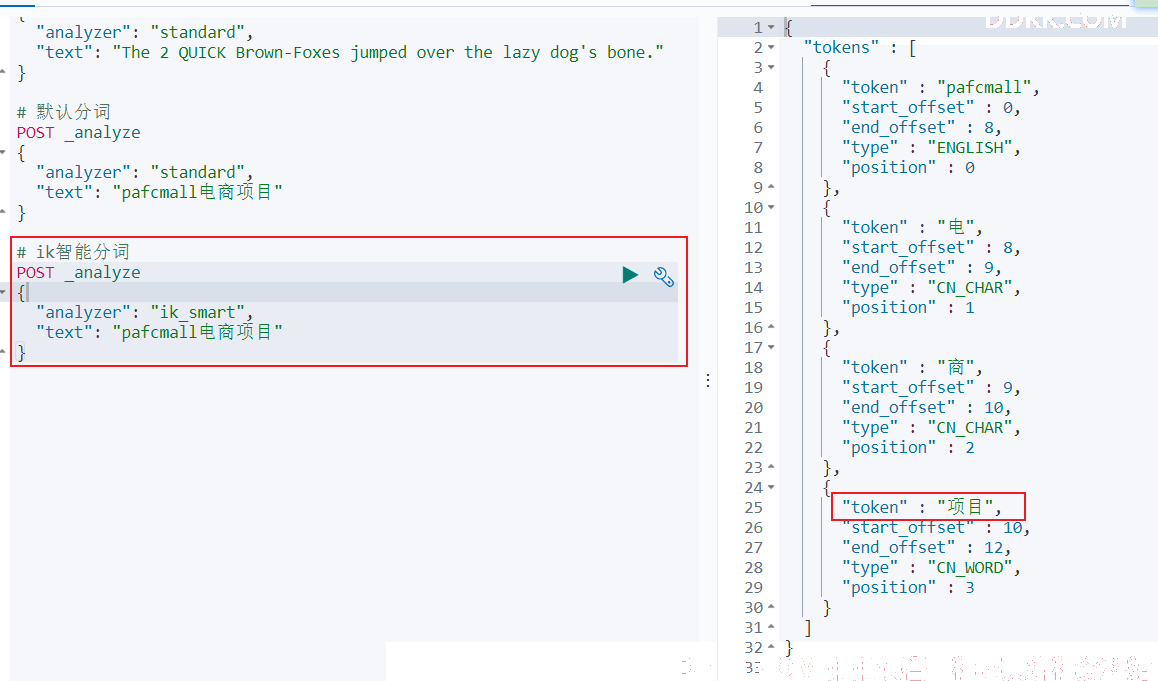
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
结果: 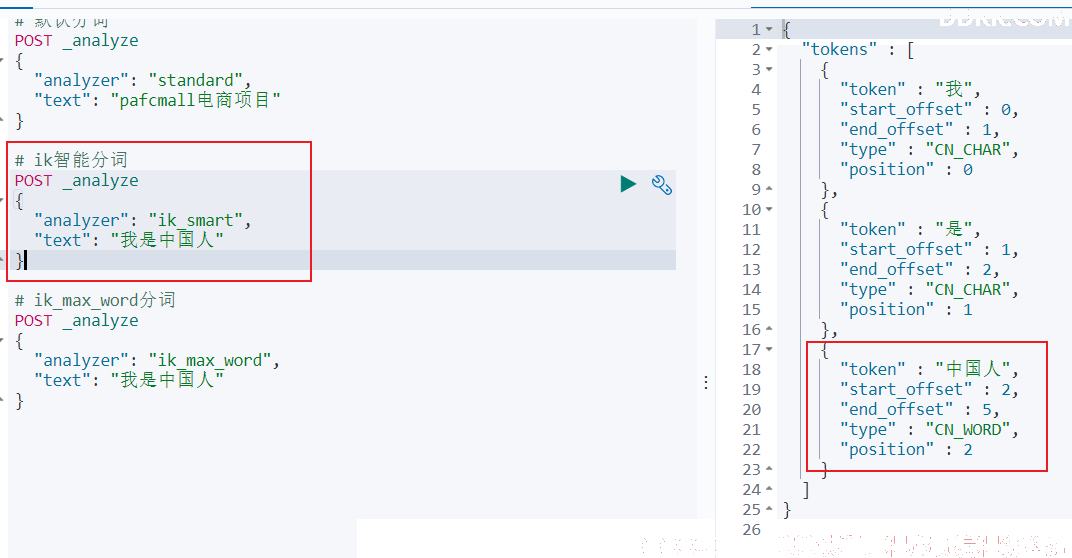
- ik_max_word分词:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
结果: 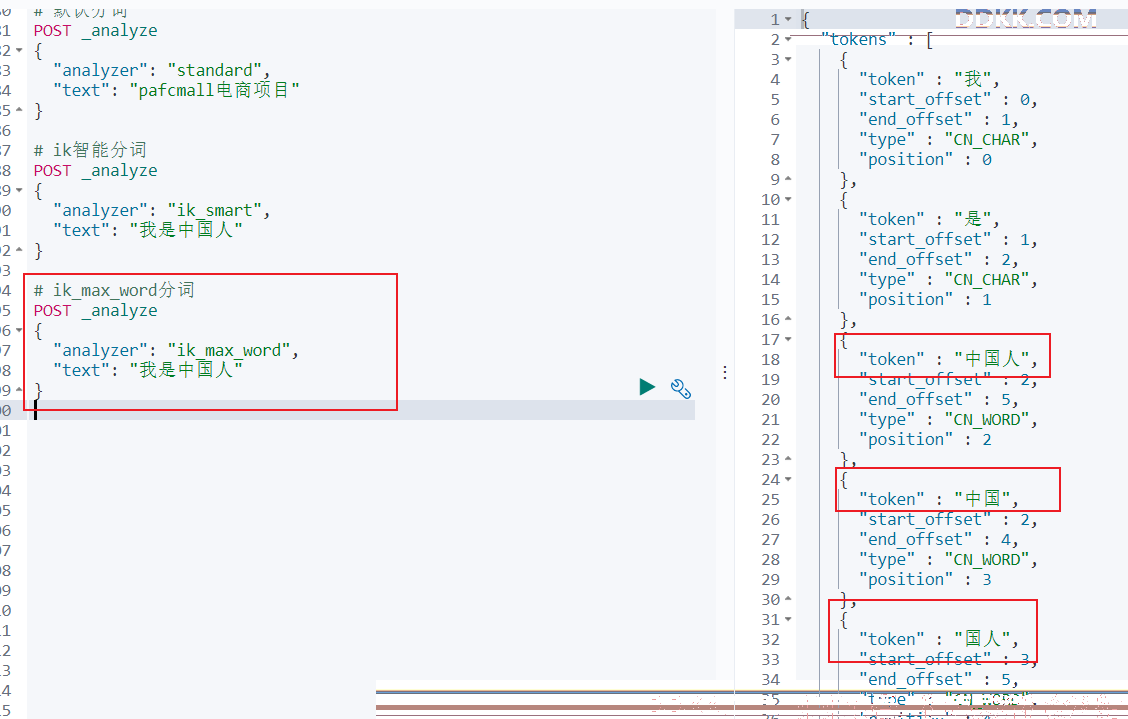
够看出不同的分词器,分词有明显的区别,所以以后定义一个索引不能再使用默认的 mapping 了,要手工建立 mapping,因为要选择分词器。