02、Kafka 实战 - kafka架构以及应用场景
什么是kafka
Apache Kafka是一个分布式发布,订阅消息系统,并且也是一个强大的队列,可以处理高并的数据,并使您能够将消息从一个端点传递到另一个端点。Kafka非常适合处理离线和在线消息消费。 Kafka消息可以持久化的保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上,用Raft协议保证集群的高可用, 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
一、Kafka的优势如下:
多生产者和多消费者
基于磁盘的数据存储,换句话说,Kafka 的数据天生就是持久化的。
高伸缩性,Kafka 一开始就被设计成一个具有灵活伸缩性的系统,对在线集群的伸缩丝毫不影响整体系统的可用性。
高性能,结合横向扩展生产者、消费者和 broker,Kafka 可以轻松处理巨大的信息流(LinkedIn 公司每天处理万亿级数据),同时保证亚秒级的消息 延迟。
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
可扩展性:kafka集群支持热扩展;
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
容错性:允许集群中节点故障(若副本数量为n,则允许n-1个节点故障);
高并发:支持数千个客户端同时读写。
二、Kafka适合以下应用场景:
消息系统 :解耦生产者和消费者、缓存消息等;
用户活动跟踪 :kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库;这样就可以根据这些数据为机 器学习提供数据,更新搜素结果等等(头条、淘宝等总会推送你感兴趣的内容,其实在数据分析之前就已经做了活动跟踪)。
运营指标和日志收集 :kafka也经常用来记录运营监控数据,或者收集应用日志信息。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;通过 Kafka 路由到专门的日志搜索系统,比如 ES。(国内用得较多)
提交日志 :收集其他系统的变动日志,比如数据库。可以把数据库的更新发布到 Kafka 上,应用通过监控事件流来接收数据库的实时更新,或者通过事件流将数 据库的更新复制到远程系统。 还可以当其他系统发生了崩溃,通过重放日志来恢复系统的状态。(异地灾备
流式处理 :操作实时数据流,进行统计、转换、复杂计算等等。随着大数据技术的不断发展和成熟,无论是传统企业还是互联网公司都已经不再满足于离线批 处理,实时流处理的需求和重要性日益增长 。 近年来业界一直在探索实时流计算引擎和 API,比如这几年火爆的 Spark Streaming、Kafka Streaming、Beam 和 Flink,其中阿里双 11 会场展示的实时 销售金额,就用的是流计算,是基于 Flink,然后阿里在其上定制化的 Blink。
下面来看看kafka的架构图
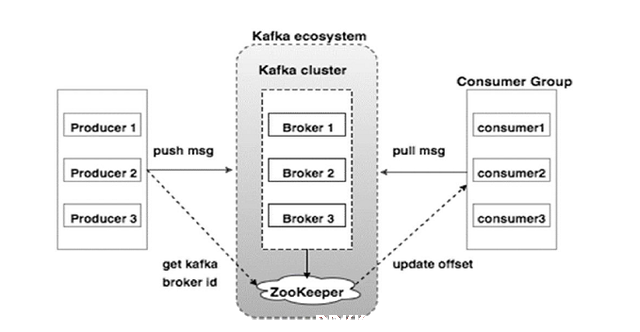
在此图中,可以看到kafka主要由4部分组成,生产者(producer),zookeeper,代理(broker),消费者(consumer)。下面非常介绍4个组件的功能和作用
生产者负责发布消息到Kafka Broker。zookperkafka与Zookeeper级联,通过Zookeeper管理级联配置,选举Leader,并管理和协调生产者和消费者去使用broker。BrokerKafka集群包含一个或多个服务实例,这些服务实例被称为Broker。是Kafka当中具体处理数据的单元。Kafka支持Broker的水平扩展。一般Broker数据越多,集群的吞吐力就越强。消费者从Kafka Broker读取消息的客户端