13、RabbitMQ 实战 - 集群+单机搭建(window)
拜读了网上很多前辈的文章,对RabbitMQ的集群有了一点点认识.
好多文章都说到,RabbitMQ的集群分为普通集群和镜像集群,有的还加了两种:单机集群和主从集群.
我看来看去,看了半天,怎么感觉,其实RabbitMQ的集群实际就一种:普通集群.
至于单机集群,无非是在一台机器上模拟普通集群,
镜像集群,不过是RabbitMQ的HA方案而已,因为这种集群方式在部署的时候,其实是通过配置参数,让队列可以"真正的"在多个节点上存储.(而普通集群,队列实际只会存储在一个节点).
主从集群,则是在镜像集群的基础上,加一层负载均衡而已.
个人愚见,也许不对.
一.原理
RabbitMQ的集群的设计目的是在增加更多节点时,能线性的增加性能(CPU,内存)和容量(内存,磁盘).同时,一个节点宕机了,其他节点依然可以提供 RabbitMQ 的服务.
所以,队列的完整数据只会保存在创建它的那个节点上,其他节点只会保存该队列的元数据和一个指向这个队列的指针而已.
一个队列的完整数据包括队列的元数据和队列的内容:

RabbitMQ一共有4种类型的元数据,并且,RabbitMQ集群会始终同步这4种元数据.
- 队列元数据:队列的名称和声明队列时设置的属性(是否持久化、是否自动删除、队列所属的节点)
- 交换机元数据:交换机的名称、类型、属性(是否持久化等)
- 绑定元数据:一张简单的表格展示了如何将消息路由到队列.包含的列有 交换机名称、交换机类型、路由键、队列名称等
- vhost元数据:为vhost内队列、交换机和绑定提供命名空间和安全属性
因此,当用户访问其中任何一个RabbitMQ节点时,通过rabbitmqctl查询到的queue,user,exchange,vhost等信息都是相同的.
下图是一个有3个节点的集群,可以看到,消息保存在节点1.
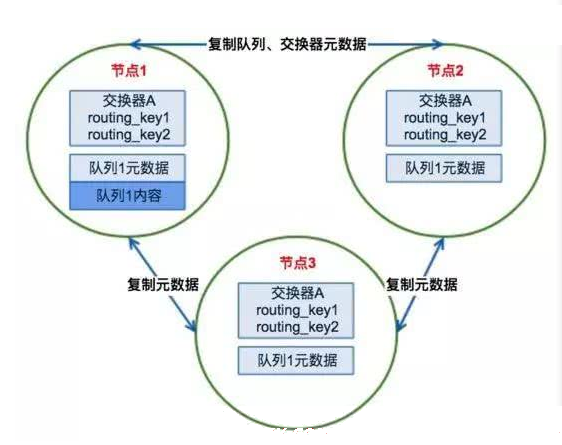
当消费者从节点2获取消息时,RabbitMQ 会把节点1的消息取出来,传递到节点2,再发送给消费者.这种方式的最大问题在于,如果节点1宕机了,那么节点2和节点3就无法获取到节点1中还未消费的消息了.
如果做了队列持久化及消息持久化,那么必须等到节点1恢复后,才能被消费,并且在节点1恢复之前,其它节点不能再创建节点1已经创建过的队列;
如果队列没有持久化,消息就会失丢.
因此,这种默认的集群模式更适合非持久化队列,只有该队列是非持久话的,客户端才能重新连接到集群里的其他节点,并重新创建该队列.假如该队列是持久化的,那么只能将故障节点恢复起来.否则,永远无法创建同名的队列.
为了证明上面说的话,我们通过搭建一个单机集群,来模拟这个场景 .
二.搭建单机集群
1.配置Hosts节点
127、 0.0.1node1;
127、 0.0.1node2;
2.复制两份 RabbitMQ ,分别取名"-1","-2"
这里我们约定 "-1" 是 node1 的 RabbitMQ,"-2"是 node2 的 RabbitMQ.
3.修改 node1 的 rabbitmq-env.bat 文件
文件路径 : rabbitmq_server-3.7.10-1\sbin\rabbitmq-env.bat
在16 行加如下配置:
set RABBITMQ_CONFIG_FILE=!RABBITMQ_HOME!\etc\rabbitmq-node1
set RABBITMQ_BASE=!RABBITMQ_BASE!\rabbitmq-cluster
set RABBITMQ_NODENAME=rabbit1@node1
set RABBITMQ_NODE_PORT=5672
再上个图,清楚些.

注意第19行, 是 rabbit1@node1 ,不是 rabbit@node1 ,单机集群,@前面一定要不一样,否则会"痛不欲生"...
4.修改 node1 的 rabbitmq-node1.config 文件
首先进入 rabbitmq_server-3.7.10-1\etc 文件夹,安装的时候会有一个官方示例文件 : rabbitmq.config.example
复制一份,改个名 : rabbitmq-node1.config
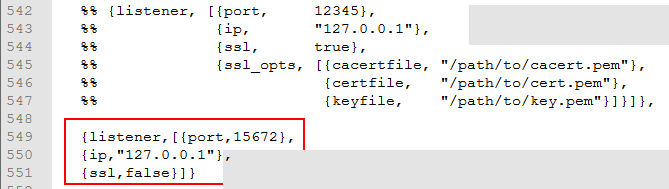
在542 行加如下配置:
{listener,[{port,15672},
{ip,"127.0.0.1"},
{ssl,false}]}
注意,我的 RabbitMQ 版本是 3.7.10 ,版本不一样,行数不一样,截个图,就是在这几行注释下面 :
5.启动 node1
1)关闭启动的 RabbitMQ
由于电脑上已经以window服务的方式启动了RabbitMQ,为了方便演示单机集群的搭建,所以我们需要将它关闭掉.
rabbitmq-service stop
,
2)启动 node 1 的 RabbitMQ
进入node1 的 sbin 文件夹,也就是 rabbitmq_server-3.7.10-1\sbin 文件夹,然后我们以后台应用的方式启动.
rabbitmq-server -detached

验证一下:
在浏览器地址栏输入 http://localhost:15672/#/
如果没有启动管理后台插件,需要先启动它 : rabbitmq-plugins enable rabbitmq_management (由于之前已经启动过了,所以我这里就不需要再启动了)
默认的账号密码都是 guest
在管理后台可以看到,node1 已经成功启动了.

6.修改 node2 的配置文件
按照第3,4步的方式修改,只是把管理后台的端口由 15672 改成 15673,当然,文件名要改成 rabbitmq-node2.config
{listener,[{port,15673},
{ip,"127.0.0.1"},
{ssl,false}]}
rabbitmq-env.bat 文件修改如下,红色标注,特别注意 rabbit2@node2
set RABBITMQ_CONFIG_FILE=!RABBITMQ_HOME!\etc\rabbitmq-node2
set RABBITMQ_BASE=!RABBITMQ_BASE!\rabbitmq-cluster
set RABBITMQ_NODENAME=rabbit2@node2
set RABBITMQ_NODE_PORT=5673
7.启动 node2
参考第5步的第2小步启动.
验证一下:
在浏览器地址栏输入 http://localhost:15673/#/
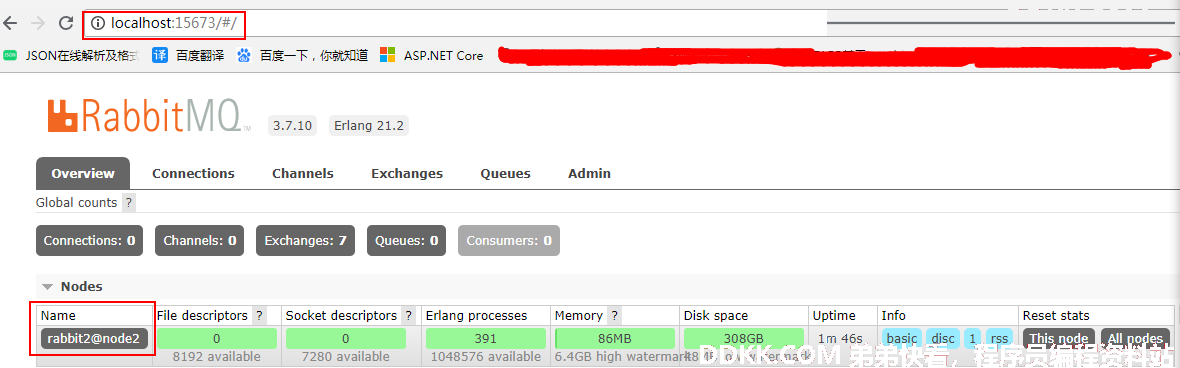
没毛病!
8.将 node2 加入集群
1)关闭 node2
rabbitmqctl stop_app

2)将 node2 加入到 node1
rabbitmqctl join_cluster rabbit1@node1

3)启动 node2
先停止rabbitmqctl stop
在启动rabbitmq-server -detached
4)打开 15672 和 15673 管理后台验证:
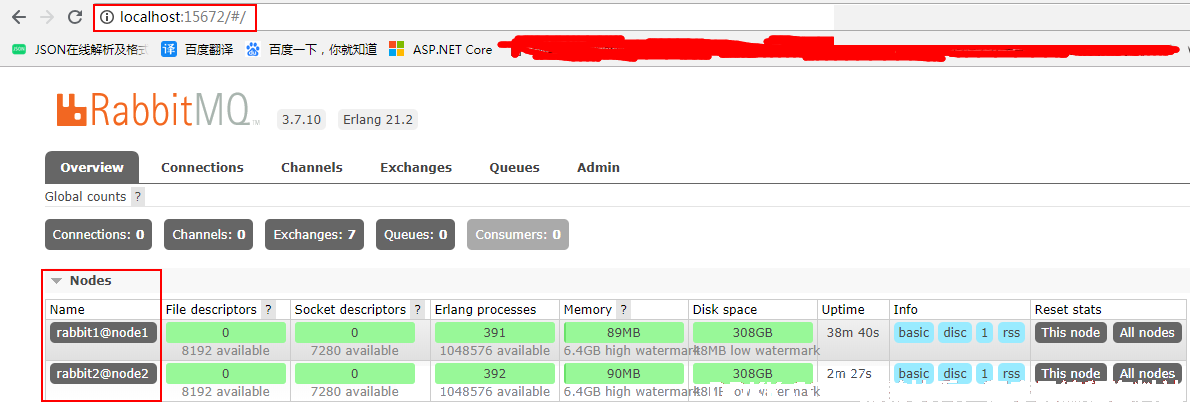
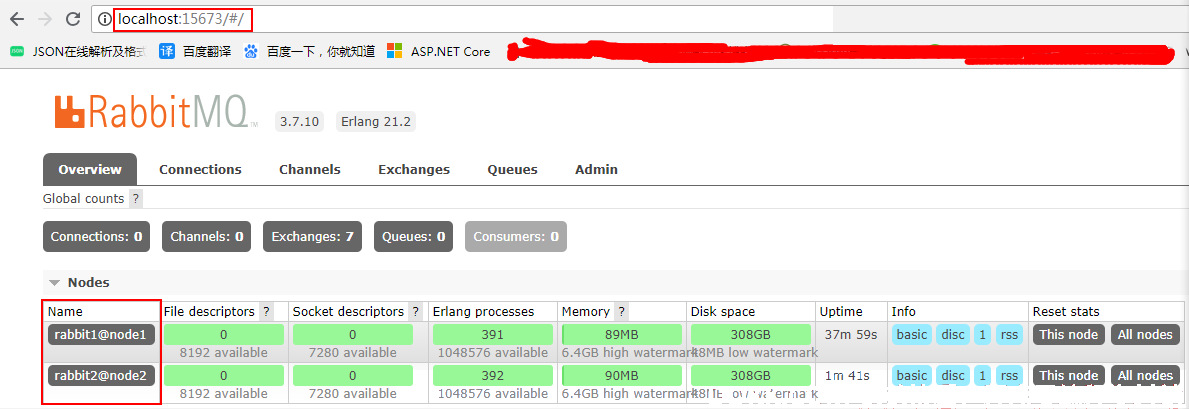
三.节点操作
增加
1、 rabbitmq-server-detached---.erlang.cooike的权限,400属主rabbitmq;
2、 rabbitmqctlstop_app;
3、 rabbitmqctljoin_cluster--ramrabbit@rabbitmq1;
4、 rabbitmqctlstart_app;
5、 rabbitmqctlcluster_status;
删除
1、 rabbitmq-server-detached正常运行的节点省略此步.;
2、 rabbitmqctlstop_app;
3、 rabbitmqctlreset;
硬删除
直接删掉集群中的某个节点
rabbitmqctl forget_cluster_node node_name