04、Kubernetes - 实战:为什么不直接使用 Pod、Job/CronJob 定义、使用 YAML 描述 Job/CronJob、在 Kubernetes 里操作 Job/CronJob
1. 为什么不直接使用 Pod
Kubernetes 的核心对象 Pod,用来编排一个或多个容器,让这些容器共享网络、存储等资源,总是共同调度,从而紧密协同工作。
因为Pod 比容器更能够表示实际的应用,所以 Kubernetes 不会在容器层面来编排业务,而是把 Pod 作为在集群里调度运维的最小单位。
虽然面向对象的设计思想多用于软件开发,但它放到 Kubernetes 里却意外地合适。因为 Kubernetes 使用 YAML 来描述资源,把业务简化成了一个个的对象,内部有属性,外部有联系,也需要互相协作,只不过我们不需要编程,完全由 Kubernetes 自动处理(其实 Kubernetes 的 Go 语言内部实现就大量应用了面向对象)。
面向对象的设计有许多基本原则,其中有两条我认为比较恰当地描述了 Kubernetes 对象设计思路,一个是“单一职责”,另一个是“组合优于继承”。
- “单一职责”的意思是对象应该只专注于做好一件事情,不要贪大求全,保持足够小的粒度才更方便复用和管理。
- “组合优于继承”的意思是应该尽量让对象在运行时产生联系,保持松耦合,而不要用硬编码的方式固定对象的关系。
应用这两条原则,我们再来看 Kubernetes 的资源对象就会很清晰了。因为 Pod 已经是一个相对完善的对象,专门负责管理容器,那么我们就不应该再“画蛇添足”地盲目为它扩充功能,而是要保持它的独立性,容器之外的功能就需要定义其他的对象,把 Pod 作为它的一个成员“组合”进去。
2. Job/CronJob
Kubernetes 里的两种新对象:Job 和 CronJob,它们就组合了 Pod,实现了对离线业务的处理。
- “在线业务”类型的应用有很多,比如 Nginx、Node.js、MySQL、Redis 等等,一旦运行起来基本上不会停,也就是永远在线。
- “离线业务”的特点是必定会退出,不会无期限地运行下去,所以它的调度策略也就与“在线业务”存在很大的不同,需要考虑运行超时、状态检查、失败重试、获取计算结果等管理事项。
而这些业务特性与容器管理没有必然的联系,如果由 Pod 来实现就会承担不必要的义务,违反了“单一职责”,所以我们应该把这部分功能分离到另外一个对象上实现,让这个对象去控制 Pod 的运行,完成附加的工作。
“离线业务”也可以分为两种。一种是“临时任务”,跑完就完事了,下次有需求了说一声再重新安排;另一种是“定时任务”,可以按时按点周期运行,不需要过多干预。
对应到Kubernetes 里:
- “临时任务”就是 API 对象 Job;
- “定时任务”就是 API 对象 CronJob;
使用这两个对象你就能够在 Kubernetes 里调度管理任意的离线业务了。
3. 使用 YAML 描述 Job
Job 的 YAML “文件头”部分还是那几个必备字段,简单说一下:
- apiVersion 不是 v1,而是 batch/v1。
- kind 是 Job,这个和对象的名字是一致的。
- metadata 里仍然要有 name 标记名字,也可以用 labels 添加任意的标签。
job/Cronjob 的 apiVersion 字段是 batch/v1,表示它们不属于核心对象组 core group,而是批处理对象组 batch group 。
还可以使用命令 kubectl explain job 来看它的字段说明。不过想要生成 YAML 样板文件的话不能使用 kubectl run,因为 kubectl run 只能创建 Pod,要创建 Pod 以外的其他 API 对象,需要使用命令 kubectl create,再加上对象的类型名。
比如用busybox 创建一个 echo-job ,命令就是这样的:
export out="--dry-run=client -o yaml" 定义Shell变量
kubectl create job echo-job --image=busybox $out
会生成一个基本的 YAML 文件,保存之后做点修改,就有了一个 Job 对象:
apiVersion: batch/v1
kind: Job
metadata:
name: echo-job
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-job
imagePullPolicy: IfNotPresent
command: ["/bin/echo"]
args: ["hello", "world"]
你会注意到 Job 的描述与 Pod 很像,但又有些不一样,主要的区别就在 spec 字段里,多了一个 template 字段,然后又是一个 spec,显得有点怪。
如果你理解了刚才说的面向对象设计思想,就会明白这种做法的道理。它其实就是在 Job 对象里应用了组合模式,template 字段定义了一个“应用模板”,里面嵌入了一个 Pod,这样 Job 就可以从这个模板来创建出 Pod。
而这个Pod 因为受 Job 的管理控制,不直接和 apiserver 打交道,也就没必要重复 apiVersion 等“头字段”,只需要定义好关键的 spec,描述清楚容器相关的信息就可以了,可以说是一个“无头”的 Pod 对象。
其实这个 echo-job 里并没有太多额外的功能,只是把 Pod 做了个简单的包装:

图片来源:https://time.geekbang.org/column/article/531566
总的来说,这里的 Pod 工作非常简单,在 containers 里写好名字和镜像,command 执行 /bin/echo,输出“hello world”。
不过,因为 Job 业务的特殊性,所以我们还要在 spec 里多加一个字段 restartPolicy,确定 Pod 运行失败时的策略,OnFailure 是失败原地重启容器,而 Never 则是不重启容器,让 Job 去重新调度生成一个新的 Pod。
4. 在 Kubernetes 里操作 Job
现在让我们来创建 Job 对象,运行这个简单的离线作业,用的命令还是 kubectl apply:
kubectl apply -f job.yml
创建之后 Kubernetes 就会从 YAML 的模板定义中提取 Pod,在 Job 的控制下运行 Pod,你可以用 kubectl get job、kubectl get pod 来分别查看 Job 和 Pod 的状态:
$ kubectl apply -f job.yml
job.batch/echo-job created
wohu@dev:~/k8s$ kubectl get pod
NAME READY STATUS RESTARTS AGE
echo-job-lt2sq 0/1 Completed 0 6s
ngx 1/1 Running 0 5h37m
wohu@dev:~/k8s$ kubectl get job
NAME COMPLETIONS DURATION AGE
echo-job 1/1 2s 11s
wohu@dev:~/k8s$
可以看到,因为 Pod 被 Job 管理,它就不会反复重启报错了,而是会显示为 Completed 表示任务完成,而 Job 里也会列出运行成功的作业数量,这里只有一个作业,所以就是 1/1。
还可以看到,Pod 被自动关联了一个名字,用的是 Job 的名字(echo-job)再加上一个随机字符串(lt2sq),这当然也是 Job 管理的“功劳”,免去了我们手工定义的麻烦,这样我们就可以使用命令 kubectl logs 来获取 Pod 的运行结果:
$ kubectl logs echo-job-lt2sq
hello world
Kubernetes 的这套 YAML 描述对象的框架提供了非常多的灵活性,可以在 Job 级别、Pod 级别添加任意的字段来定制业务,这种优势是简单的容器技术无法相比的。比如下面这些字段,其他更详细的信息可以参考 Job 文档
- activeDeadlineSeconds,设置 Pod 运行的超时时间。
- backoffLimit,设置 Pod 的失败重试次数。
- completions,Job 完成需要运行多少个 Pod,默认是 1 个。
- parallelism,它与 completions 相关,表示允许并发运行的 Pod 数量,避免过多占用资源。
要注意这 4 个字段并不在 template 字段下,而是在 spec 字段下,所以它们是属于 Job 级别的,用来控制模板里的 Pod 对象。
下面我再创建一个 Job 对象,名字叫“sleep-job”,它随机睡眠一段时间再退出,模拟运行时间较长的作业(比如 MapReduce)。Job 的参数设置成 15 秒超时,最多重试 2 次,总共需要运行完 4 个 Pod,但同一时刻最多并发 2 个 Pod:
apiVersion: batch/v1
kind: Job
metadata:
name: sleep-job
spec:
activeDeadlineSeconds: 15
backoffLimit: 2
completions: 4
parallelism: 2
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-job
imagePullPolicy: IfNotPresent
command:
- sh
- -c
- sleep $(($RANDOM % 10 + 1)) && echo done
Job 配置细节:
job.spec.containers.template.spec.containers.image是不能指定镜像版本号的,只能指定镜像:完整的镜像:版本号只能由pod定义,否则会从互联网拉取镜像,如果能联网当然没事,离线环境会直接报错无法拉取镜像,虽然你本地确实存在该版本的镜像且imagePullPolicy设置为Never或IfNotPresent。
比如我是离线环境,job里image配置为:- image: busybox:1.35.0,那么就会报错无法拉取镜像。
使用kubectl apply 创建 Job 之后,我们可以用 kubectl get pod -w 来实时观察 Pod 的状态,看到 Pod不断被排队、创建、运行的过程:
kubectl apply -f sleep-job.yml
kubectl get pod -w
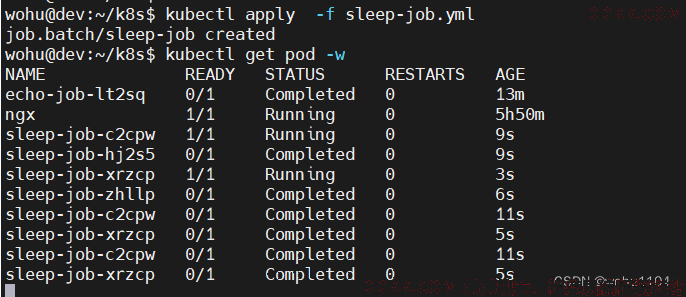
等到4 个 Pod 都运行完毕,我们再用 kubectl get 来看看 Job 和 Pod 的状态
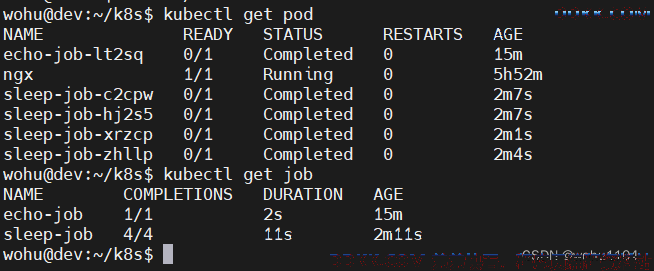
就会看到 Job 的完成数量如同我们预期的是 4,而 4 个 Pod 也都是完成状态。
Job 在运行结束后不会立即删除,这是为了方便获取计算结果,但如果积累过多的已完成 Job 也会消耗系统资源,可以使用字段 ttlSecondsAfterFinished 设置一个保留的时限。
5. 使用 YAML 描述 CronJob
1、 因为CronJob的名字有点长,所以Kubernetes提供了简写cj,这个简写也可以使用命令kubectlapi-resources看到;
2、 CronJob需要定时运行,所以我们在命令行里还需要指定参数--schedule;
直接使用命令 kubectl create 来创建 CronJob 的样板。
export out="--dry-run=client -o yaml" 定义Shell变量
kubectl create cj echo-cj --image=busybox --schedule="" $out
然后我们编辑这个 YAML 样板,生成 CronJob 对象:
apiVersion: batch/v1
kind: CronJob
metadata:
name: echo-cj
spec:
schedule: '*/1 * * * *'
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-cj
imagePullPolicy: IfNotPresent
command: ["/bin/echo"]
args: ["hello", "world"]
我们还是重点关注它的 spec 字段,你会发现它居然连续有三个 spec 嵌套层次:
- 第一个 spec 是 CronJob 自己的对象规格声明。
- 第二个 spec 从属于 jobTemplate,它定义了一个 Job 对象。
- 第三个 spec 从属于 template ,它定义了 Job 里运行的 Pod。
所以,CronJob 其实是又组合了 Job 而生成的新对象

除了定义 Job 对象的 jobTemplate 字段之外,CronJob 还有一个新字段就是 schedule,用来定义任务周期运行的规则。它使用的是标准的 Cron 语法,指定分钟、小时、天、月、周,和 Linux 上的 crontab 是一样的。
除了名字不同,CronJob 和 Job 的用法几乎是一样的,使用 kubectl apply 创建 CronJob,使用 kubectl get cj、kubectl get pod 来查看状态:
kubectl apply -f cronjob.yml
kubectl get cj
kubectl get pod
出于节约资源的考虑,CronJob 不会无限地保留已经运行的 Job,它默认只保留 3 个最近的执行结果,但可以用字段 successfulJobsHistoryLimit 改变。
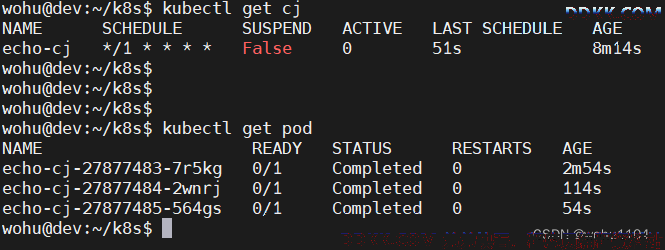
Cron 时间设置语法:https://crontab.guru/
6. 总结
通过这种嵌套方式,Kubernetes 里的这些 API 对象就形成了一个“控制链”:
CronJob 使用定时规则控制 Job,Job 使用并发数量控制 Pod,Pod 再定义参数控制容器,容器再隔离控制进程,进程最终实现业务功能,层层递进的形式有点像设计模式里的 Decorator(装饰模式),链条里的每个环节都各司其职,在 Kubernetes 的统一指挥下完成任务。
1、 Pod是Kubernetes的最小调度单元,但为了保持它的独立性,不应该向它添加多余的功能;
2、 Kubernetes为离线业务提供了Job和CronJob两种API对象,分别处理“临时任务”和“定时任务”;
3、 Job的关键字段是spec.template,里面定义了用来运行业务的Pod模板,其他的重要字段有completions、parallelism等;
4、 CronJob的关键字段是spec.jobTemplate和spec.schedule,分别定义了Job模板和定时运行的规则;