26、Kubernetes 实战 - 之Schedule
Schedule
调度器是主节点上的组件,该组件监视那些新创建的未指定运行节点的 Pod,并选择节点让 Pod 在上面运行。
kube-scheduler 是 Kubernetes 集群的默认调度器,并且是集群 控制面 的一部分。如果你真的希望或者有这方面的需求,kube-scheduler 在设计上是允许你自己写一个调度组件并替换原有的 kube-scheduler。
对每一个新创建的 Pod 或者是未被调度的 Pod,kube-scheduler 会选择一个最优的 Node 去运行这个 Pod。然而,Pod 内的每一个容器对资源都有不同的需求,而且 Pod 本身也有不同的资源需求。因此,Pod 在被调度到 Node 上之前,根据这些特定的资源调度需求,需要对集群中的 Node 进行一次过滤。
在一个集群中,满足一个 Pod 调度请求的所有 Node 称之为 可调度节点。如果没有任何一个 Node 能满足 Pod 的资源请求,那么这个 Pod 将一直停留在未调度状态直到调度器能够找到合适的 Node。
调度器先在集群中找到一个 Pod 的所有可调度节点,然后根据一系列函数对这些可调度节点打分,然后选出其中得分最高的 Node 来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做 绑定。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局域性、负载间的干扰等等。
调度过程
predicate
预选:过滤掉不满足条件的节点,过滤阶段会将所有满足 Pod 调度需求的 Node 选出来。例如,PodFitsResources 过滤函数会检查候选 Node 的可用资源能否满足 Pod 的资源请求。在过滤之后,得出一个 Node 列表,里面包含了所有可调度节点;通常情况下,这个 Node 列表包含不止一个 Node。如果这个列表是空的,代表这个 Pod 不可调度。
预选算法
- PodFitsResources :节点上剩余的资源是否大于 pod 请求的资源
- PodFitsHost :如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配
- PodFitsHostPorts :节点上已经使用的 port 是否和 pod 申请的 port 冲突
- PodSelectorMatches :过滤掉和 pod 指定的 label 不匹配的节点
- NoDiskConflict :已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非它们都是只读
如果在predicate 过程中没有合适的节点,pod 会一直在 pending 状态,不断重试调度,直到有节点满足条件。经过这个步骤,如果有多个节点满足条件,就继续 priority过程
priority:
优选:调度器会为 Pod 从所有可调度节点中选取一个最合适的 Node。根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。最后,kube-scheduler 会将 Pod 调度到得分最高的 Node 上。如果存在多个得分最高的 Node,kube-scheduler 会从中随机选取一个。
优先级选项包括
- LeastRequestedPriority :通过计算 CPU 和 Memory 的使用率来决定权重,使用率越低权重越高。换句话说,这个优先级指标倾向于资源使用比例更低的节点 BalancedResourceAllocation :节点上 CPU 和 Memory 使用率越接近,权重越高。这个应该和上面的一起使用,不应该单独使用
- ImageLocalityPriority :倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高
通过算法对所有的优先级项目和权重进行计算,得出最终的结果
将容器组调度到指定的节点
你可以约束一个 Pod 只能在特定的 Node(s) 上运行,或者优先运行在特定的节点上。有几种方法可以实现这点,推荐的方法都是用标签选择器来进行选择。通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将 pod 分散到节点上,而不是将 pod 放置在可用资源不足的节点上等等),但在某些情况下,你可能需要更多控制 pod 停靠的节点,例如,确保 pod 最终落在连接了 SSD 的机器上,或者将来自两个不同的服务且有大量通信的 pod 放置在同一个可用区。常见方式有:
- 指定节点 nodeName
- 节点选择器 nodeSelector (推荐用法)
- Node isolation/restriction
- Affinity and anti-affinity
nodeSelector
nodeSelector 是节点选择约束的最简单推荐形式。nodeSelector 是 PodSpec 的一个字段。 它包含键值对的映射。为了使 pod 可以在某个节点上运行,该节点的标签中必须包含这里的每个键值对(它也可以具有其他标签)。最常见的用法的是一对键值对。
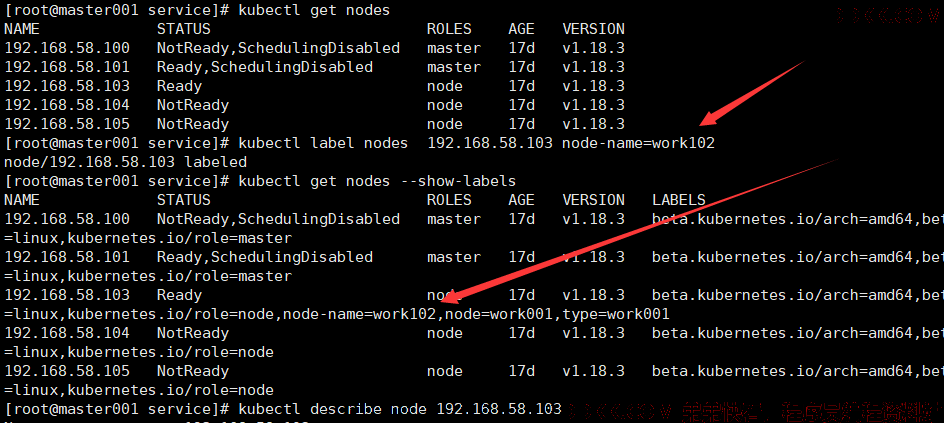
1、 添加标签到节点;
# 获取集群的节点名称
kubectl get nodes
# 节点增加标签
kubectl label nodes 192.168.58.103 node-name=work102
# 查看标签
kubectl get nodes --show-labels
# 查看标签详情
kubectl describe node 192.168.58.103
1、 添加nodeSelector字段到Pod配置中;
# 、
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx
spec:
restartPolicy: Never
containers:
- name: nginx-001
image: daocloud.io/library/nginx:1.7.11
nodeSelector:
添加节点选择标签
node-name: work102
1、 验证,查看pod已被分配到指定node节点;
kubectl get pods -o wide
亲和性与反亲和性
nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。亲和/反亲和功能极大地扩展了你可以表达约束的类型。关键的增强点是
1、 语言更具表现力(不仅仅是“完全匹配的AND”);
2、 你可以发现规则是“软”/“偏好”,而不是硬性要求,因此,如果调度器无法满足该要求,仍然调度该pod;
3、 你可以使用节点上(或其他拓扑域中)的pod的标签来约束,而不是使用节点本身的标签,来允许哪些pod可以或者不可以被放置在一起;
亲和功能包含两种类型的亲和,即“节点亲和”和“pod 间亲和/反亲和”。节点亲和就像现有的 nodeSelector(但具有上面列出的前两个好处),然而 pod 间亲和/反亲和约束 pod 标签而不是节点标签(在上面列出的第三项中描述,除了具有上面列出的第一和第二属性)
节点亲和性
节点亲和概念上类似于 nodeSelector,它使你可以根据节点上的标签来约束 pod 可以调度到哪些节点。
目前有两种类型的节点亲和,分别为 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution。你可以视它们为“硬”和“软”,意思是,前者指定了将 pod 调度到一个节点上必须满足的规则(就像 nodeSelector 但使用更具表现力的语法),后者指定调度器将尝试执行但不能保证的偏好。名称的“IgnoredDuringExecution”部分意味着,类似于 nodeSelector 的工作原理,如果节点的标签在运行时发生变更,从而不再满足 pod 上的亲和规则,那么 pod 将仍然继续在该节点上运行。将来我们计划提供 requiredDuringSchedulingRequiredDuringExecution,它将类似于 requiredDuringSchedulingIgnoredDuringExecution,除了它会将 pod 从不再满足 pod 的节点亲和要求的节点上驱逐。
因此,requiredDuringSchedulingIgnoredDuringExecution 的示例将是“仅将 pod 运行在具有 Intel CPU 的节点上”,而 preferredDuringSchedulingIgnoredDuringExecution 的示例为“尝试将这组 pod 运行在 XYZ 故障区域,如果这不可能的话,则允许一些 pod 在其他地方运行”。
节点亲和通过 PodSpec 的 affinity 字段下的 nodeAffinity 字段进行指定。
实例:
#
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx
spec:
restartPolicy: Never
亲和性设置
affinity:
节点亲和性
nodeAffinity:
硬性要求
requiredDuringSchedulingIgnoredDuringExecution:
节点选择器规则
nodeSelectorTerms:
匹配表达式
- matchExpressions:
标签键值对
- key: node-name
操作符 (In,NotIn,Exists,DoesNotExist,Gt,Lt)
operator: In
对应key的值
values:
- work102
- work103
软性要求
preferredDuringSchedulingIgnoredDuringExecution:
权重, 1-100
- weight: 1
preference:
matchExpressions:
- key: node-name
operator: In
values:
- work102
containers:
- name: nginx-001
image: daocloud.io/library/nginx:1.7.11
Pod亲和性与反亲和性
Pod之间的亲和性与反亲和性(inter-pod affinity and anti-affinity)可以基于已经运行在节点上的 Pod 的标签(而不是节点的标签)来限定 Pod 可以被调度到哪个节点上。此类规则的表现形式是:
- 当 X 已经运行了一个或者多个满足规则 Y 的 Pod 时,待调度的 Pod 应该(或者不应该 - 反亲和性)在 X 上运行规则 Y 以 LabelSelector 的形式表述,附带一个可选的名称空间列表
- 与节点不一样,Pod 是在名称空间中的(因此,Pod的标签是在名称空间中的),针对 Pod 的 LabelSelector 必须同时指定对应的名称空间
X是一个拓扑域的概念,例如节点、机柜、云供应商可用区、云供应商地域,等。X 以 topologyKey 的形式表达,该 Key代表了节点上代表拓扑域(topology domain)的一个标签。
示例:
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
# Pod 亲和性规则
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
Pod 反亲和性规则
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
污点/容忍
节点亲和性(详见这里) 是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点。 这可能出于一种偏好,也可能是硬性要求。 Taint(污点)则相反,它使节点能够排斥一类特定的 Pod。
容忍度(Tolerations)是应用于 Pod 上的,允许(但并不要求)Pod 调度到带有与之匹配的污点的节点上。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod,是不会被该节点接受的。
添加污点
# 给节点192.168.58.101增加一个污点,它的键名是 key,键值是 value,效果是 NoSchedule。 这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到这个节点
kubectl taint nodes 192.168.58.101 key=value:NoSchedule
删除污点
#
kubectl taint nodes 192.168.58.101 key:NoSchedule-
添加容忍
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx
spec:
restartPolicy: Never
containers:
- name: nginx-001
image: daocloud.io/library/nginx:1.7.11
容忍设置
tolerations:
- key: "key"
operator: "Exists"
effect: "NoSchedule"