12、算法与数据结构 - 实战:查集
并查集解析
并查集:
有若干样本,类型为T,
一开始每个都是自己为一个集合。
有两个方法:isSameSet、union,
isSameSet(T a, T b),返回两个样本是否在一个集合中,
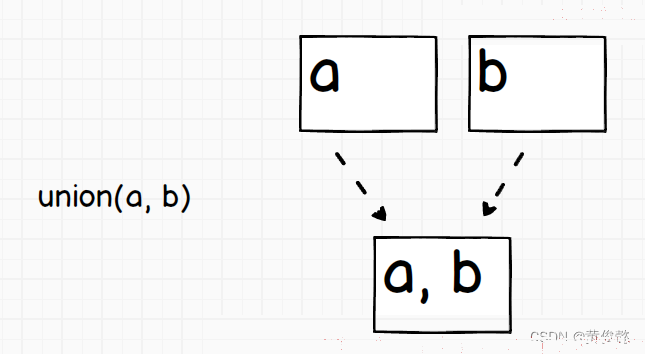
union(T a, T b),把a样本和b样本所在的集合合并成一个集合。
用最小代价实现isSameSet、union两个方法。
比如有样本集{a, b, c, d, e, f, g}
一开始a自己是一个集合,b自己是一个集合

调用isSameSet(a, b),返回a样本和b样本是否在一个集合中
调用union(a, b),则把a样本和b样本所在的集合,合成一个集合,那么a和b就在同一个集合中
解法:
1、 根据样本生成节点,存放到key为样本值,value为Node的映射表nodeMap;
2、 建立一个节点与父节点的映射表parentMap,一开始每个节点指向自己;
3、 建立一个集合代表节点(每个集合都有一个代表节点)与集合大小的映射表sizeMap;
4、 调union(a,b)方法合并两个集合时,从parentMap一直往上找,直到不能再往上,找到两个节点的代表节点(一直往上找的操作放到findRootNode方法中);
5、 如果两个代表节点是同一个节点,代表a和b已经在一个集合中;
6、 如果两个代表节点不是同一个,则从sizeMap中找到代表节点所在集合对应的size;
7、 小集合的代表节点指向大集合的代表节点,映射关系记录到parentMap;
8、 sizeMap中remove调小集合的代表节点的记录;
findRootNode方法优化:
把沿途的所有节点重定向,修改parentMap中指向的父节点都变成集合代表节点。具体做法是用一个栈记录沿途节点,找到集合代表节点后,从栈中依次弹出节点,修改parentMap中以该节点为key对应的value为代表节点,表示修改了指向的父节点为集合代表节点(其实就是一个扁平化处理)

下次再调findRootNode寻找代表节点,就是直接找到,时间复杂度O(1)
/**
* 并查集
* 有如果样本,类型为T
* 一开始每个都是自己为一个集合
* 有两个方法:isSameSet、union
* isSameSet(T a, T b),返回两个样本是否在一个集合中
* union(T a, T b),把a样本和b样本所在的集合合并成一个集合
* 用最小代价实现isSameSet、union两个方法
*/
public class UnionSet01<T> {
/**
* 存放value到Node的映射
*/
private Map<T, Node<T>> nodeMap = new HashMap();
/**
* 存放子Node到父Node的映射
*/
private Map<Node<T>, Node<T>> parentMap = new HashMap<>();
/**
* 存放根Node与集合大小的映射
*/
private Map<Node<T>, Integer> sizeMap = new HashMap<>();
public UnionSet01(List<T> values) {
for (T value : values) {
Node<T> node = new Node<>(value);
nodeMap.put(value, node);
parentMap.put(node, node);
sizeMap.put(node, 1);
}
}
public Node<T> findRootNode(Node<T> node) {
Stack<Node<T>> stack = new Stack<>();
//一直往上寻找,找到找到根Node,沿途的Node记录到stack
while (parentMap.get(node) != node) {
stack.push(node);
node = parentMap.get(node);
}
//修改沿途的Node的父节点,使得下次findRootNode的代价更小(扁平化)
while (!stack.isEmpty()) parentMap.put(stack.pop(), node);
return node;
}
public boolean isSameSet(T a, T b) {
//如果a和b有其中一个没有被记录过,返回false
if (!nodeMap.containsKey(a) || !nodeMap.containsKey(b)) return false;
//a对应的Node,和b对应的Node,同时找到根Node,如果是同一个根Node,代表a和b在一个集合中
return findRootNode(nodeMap.get(a)) == findRootNode(nodeMap.get(b));
}
public void union(T a, T b) {
if (!nodeMap.containsKey(a) || !nodeMap.containsKey(b)) return;
//a对应的Node,和b对应的Node,同时往上找到根Node
Node<T> rootNodeA = findRootNode(nodeMap.get(a));
Node<T> rootNodeB = findRootNode(nodeMap.get(b));
//在同一个集合中,不用合并
if (rootNodeA == rootNodeB) return;
int sizeA = sizeMap.get(rootNodeA);
int sizeB = sizeMap.get(rootNodeB);
//数量小的集合的根Node的父Node指向数量大的集合的跟Node
//然后更新sizeMap信息,sizeMap只需要存储根Node与集合大小的映射
if (sizeA <= sizeB) {
parentMap.put(rootNodeA, rootNodeB);
sizeMap.put(rootNodeB, sizeA + sizeB);
sizeMap.remove(rootNodeA);
} else {
parentMap.put(rootNodeB, rootNodeA);
sizeMap.put(rootNodeA, sizeA + sizeB);
sizeMap.remove(rootNodeB);
}
}
public static class Node<T> {
private T value;
public Node(T value) {
this.value = value;
}
}
}
并查集应该:省份数量
力扣547题:
有n个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
解法:
1、 初始化一个大小为n的并查集;
2、 遍历isConnected数组;
3、 如果isConnected[i][j]=1,那么调用unionSet.union(i,j),进行合并;
4、 遍历完毕,返回并查集中的集合数量,就是省份数量;
/**
* https://leetcode.cn/problems/number-of-provinces/description/
* Created by huangjunyi on 2022/11/26.
*/
public class UnionSet03 {
class Solution {
public int findCircleNum(int[][] isConnected) {
UnionSet unionSet = new UnionSet(isConnected.length);
int N = isConnected.length;
// 遍历矩阵,如果是1,则进行union合并
// 但是只需要遍历上半区,下半区不需要遍历,因为是对等的
for (int i = 0; i < N; i++) {
for (int j = i; j < isConnected[i].length; j++) {
if (isConnected[i][j] == 1) unionSet.union(i, j);
}
}
return unionSet.setNum;
}
private class UnionSet {
int[] parent; // 相当于parentMap
int[] size; // 相当于sizeMap
int setNum; // 集合个数
public UnionSet(int n) {
// 初始化并查集
parent = new int[n];
size = new int[n];
for (int i = 0; i < n; i++) {
// 一开始父亲都是自己
parent[i] = i;
// 自己为一个集合
size[i] = 1;
}
// 初始集合数
setNum = n;
}
private void union(int a, int b) {
int head1 = findHead(a); // 寻找a所在集合的代表节点
int head2 = findHead(b); // 寻找b所在集合的代表节点
if (head1 == head2) return;
int size1 = size[head1]; // a节点所在集合的大小
int size2 = size[head2]; // b节点所在集合的大小
// 小集合代表节点指向大节点代表节点,两个集合合并在一起
if (size1 <= size2) {
parent[head1] = head2;
size[head2] = size1 + size2;
} else {
parent[head2] = head1;
size[head1] = size1 + size2;
}
// 集合数--
setNum--;
}
private int findHead(int a) {
LinkedList<Integer> stack = new LinkedList<>();
while (a != parent[a]) {
// 收集沿途经过的节点
stack.push(a);
a = parent[a];
}
// 修改沿途节点指向的父节点为代表节点(扁平化)
while (!stack.isEmpty()) parent[stack.pop()] = a;
return a;
}
}
}
}
岛问题(动态添加)
给定一个整形m,和整形n,代表m行n列的二维矩阵,
起初矩阵中所有元素都是0。
再给定一个列数为2的二维数组positions,positions中的每个一维数组,表示矩阵的某个位置,要把该位置修改为1。
遍历positions数组,依次修改矩阵中对应位置为1,
然后返回每次修改后的岛数量。
解法:
- 也是用并查集求解,但是因为是每一步收集一个答案,所以要改成动态添加的并查集
- 每遍历positions中的一个一维数组,就unionSet.add(i, j)添加到并查集中,然后尝试于上下左右进行union
- 另外,因为并查集里面需要做二维转一维的处理
/**
* 给定一个整形m,和整形n,代表m行n列的二维矩阵
* 起初矩阵中所有元素都是0
* 再给定一个列数为2的二维数组positions,positions中的每个一维数组,表示矩阵的某个位置,要把该位置修改为1
* 遍历positions数组,依次修改矩阵中对应位置为1
* 然后返回每次修改后的岛数量
* Created by huangjunyi on 2022/11/26.
*/
public class UnionSet04 {
public static List<Integer> numIslands(int m, int n, int[][] positions) {
UnionSet unionSet = new UnionSet(m, n);
List<Integer> res = new ArrayList<>();
// 遍历positions,添加每个元素到并查集中,并且每一步收集一个答案
for (int i = 0; i < positions.length; i++) {
for (int j = 0; j < positions[i].length; j++) {
unionSet.add(i, j);
res.add(unionSet.sizeNum);
}
}
return res;
}
private static class UnionSet {
int[] parent; // parentMap
int[] size; // sizeMap
int[] help; // 代替扁平化时使用的栈
int sizeNum; // 集合数,相当于岛数量
int cols; // 列数
int rows; // 行数
public UnionSet(int m, int n) {
// 初始化并查集,二维数组转一维数组
int len = m * n;
parent = new int[len];
size = new int[n];
help = new int[n];
sizeNum = 0;
cols = n;
rows = m;
}
public int index(int r, int c) {
// 二维数组到一位数组的下标换算
return r * cols + c;
}
private int findHead(int a) {
int top = 0;
while (a != parent[a]) {
// 用数组代替栈,收集沿途经过的节点
help[top++] = a;
a = parent[a];
}
// 扁平化处理
for (int i = top-1; i >= 0; i--) {
parent[help[i]] = a;
}
return a;
}
private void union(int r1, int c1, int r2, int c2) {
// 判断是否越界
if (r1 < 0 || r1 == rows || r2 < 0 || r2 == rows || c1 < 0 || c1 == cols || c2 < 0 || c2 == cols) return;
int index1 = index(r1, c1);
int index2 = index(r2, c2);
// 判断两个节点是否都在并查集中
if (size[index1] == 0 || size[index2] == 0) return;
// 找到两个节点的代表节点
int head1 = findHead(index1);
int head2 = findHead(index2);
if (head1 == head2) return;
// 合并
if (size[head1] <= size[head2]) {
parent[head1] = head2;
size[head2] += size[head1];
} else {
parent[head2] = head1;
size[head1] += size[head2];
}
sizeNum--;
}
public void add(int r, int c) {
int index = index(r, c);
// 已经加入过,直接返回
if (size[index] != 0) return;
// 节点加入并查集
parent[index] = index;
size[index] = 1;
sizeNum++;
// 尝试跟它的上下左右合并
union(r, c, r - 1, c);
union(r, c, r + 1, c);
union(r, c, r, c - 1);
union(r, c, r, c + 1);
}
}
}
另一个并查集的应用例子
一个人Person有三个id,两个Person只要有其中一个id相同,就认为是同一个人
给定一个Person数组,将其合并,并返回里面有几个人
/**
* 一个并查集的使用例子
* 一个人有三个id,只有其中一个id相同,就认为是同一个人
* 给定一个Person数组,将其合并,并返回里面有几个人
*/
public class UnionSet02 {
private static class Person {
private int id1;
private int id2;
private int id3;
}
public static class UnionSet<T> {
/**
* 存放value到Node的映射
*/
private Map<T, Node<T>> nodeMap = new HashMap();
/**
* 存放子Node到父Node的映射
*/
private Map<Node<T>, Node<T>> parentMap = new HashMap<>();
/**
* 存放根Node与集合大小的映射
*/
private Map<Node<T>, Integer> sizeMap = new HashMap<>();
public UnionSet(T[] values) {
for (T value : values) {
Node<T> node = new Node<>(value);
nodeMap.put(value, node);
parentMap.put(node, node);
sizeMap.put(node, 1);
}
}
public Node<T> findRootNode(Node<T> node) {
Stack<Node<T>> stack = new Stack<>();
//一直往上寻找,找到找到根Node,沿途的Node记录到stack
while (parentMap.get(node) != node) {
stack.push(node);
node = parentMap.get(node);
}
//修改沿途的Node的父节点,使得下次findRootNode的代价更小
while (!stack.isEmpty()) parentMap.put(stack.pop(), node);
return node;
}
public boolean isSameSet(T a, T b) {
//如果a和b有其中一个没有被记录过,返回false
if (!nodeMap.containsKey(a) || !nodeMap.containsKey(b)) return false;
//a对应的Node,和b对应的Node,同时找到根Node,如果是同一个根Node,代表a和b在一个集合中
return findRootNode(nodeMap.get(a)) == findRootNode(nodeMap.get(b));
}
public void union(T a, T b) {
if (!nodeMap.containsKey(a) || !nodeMap.containsKey(b)) return;
//a对应的Node,和b对应的Node,同时往上找到根Node
Node<T> rootNodeA = findRootNode(nodeMap.get(a));
Node<T> rootNodeB = findRootNode(nodeMap.get(b));
//在同一个集合中,不用合并
if (rootNodeA == rootNodeB) return;
int sizeA = sizeMap.get(rootNodeA);
int sizeB = sizeMap.get(rootNodeB);
//数量小的集合的根Node的父Node指向数量大的集合的跟Node
//然后更新sizeMap信息,sizeMap只需要存储根Node与集合大小的映射
if (sizeA <= sizeB) {
parentMap.put(rootNodeA, rootNodeB);
sizeMap.put(rootNodeB, sizeA + sizeB);
sizeMap.remove(rootNodeA);
} else {
parentMap.put(rootNodeB, rootNodeA);
sizeMap.put(rootNodeA, sizeA + sizeB);
sizeMap.remove(rootNodeB);
}
}
public int countSet() {
return sizeMap.size();
}
}
public static class Node<T> {
private T value;
public Node(T value) {
this.value = value;
}
}
public static int merge(Person[] persons) {
UnionSet<Person> unionSet = new UnionSet<>(persons);
Map<Integer, Person> id1Map = new HashMap<>(); //记录id1和person的映射关系
Map<Integer, Person> id2Map = new HashMap<>(); //记录id2和person的映射关系
Map<Integer, Person> id3Map = new HashMap<>(); //记录id3和person的映射关系
/**
* 用三个map,分表记录id1、id2、id3与person的映射关系
* 遍历给定的person数组,如果map里面没有包含该id,则添加其映射关系
* 如果已经包含该id,则调用并查集UnionSet的union方法,把这两个person合并
*/
for (Person person : persons) {
if (id1Map.containsKey(person.id1)) {
unionSet.union(person, id1Map.get(person.id1));
} else {
id1Map.put(person.id1, person);
}
if (id2Map.containsKey(person.id2)) {
unionSet.union(person, id2Map.get(person.id2));
} else {
id2Map.put(person.id2, person);
}
if (id3Map.containsKey(person.id3)) {
unionSet.union(person, id3Map.get(person.id3));
} else {
id3Map.put(person.id3, person);
}
}
//返回并查集中集合的数目,id相同的都通过union方法合并了,所以一个集合代表一个人
return unionSet.countSet();
}
}