01、Spring Data JPA 实战 - 基于SpringBoot2.0.3+ MySQL5.7
SpringDatajpa是我很久之前使用的一款持久层框架了,个人感觉这个框架非常好使。虽然很多公司目前还是以mybatis为主,但是如果小公司或者个人想写一个小项目或者分工比较明确的分布式项目的话springDatajpa是个不二的选择
一、必要的前言
下面是springdatajpa的官方介绍:

说实话看这些介绍意义不大,还是先带大家体验下使用吧,相信大家会喜欢上的!!!
二、废话不多说了,开始创建项目
额。。。创建一个基于springboot2.0.3的项目即可,相信能看我这篇文章的人都应该会吧!—JKD1.8
创建完成之后这样,eclipse版的可能目录结构显示有不小的差异,但是只要<version>标签中为2.0.3.RELEASE即可
注意:版本尽量与我保持一致,不一致会出现不可预估的错误,基本2.0以上随意!
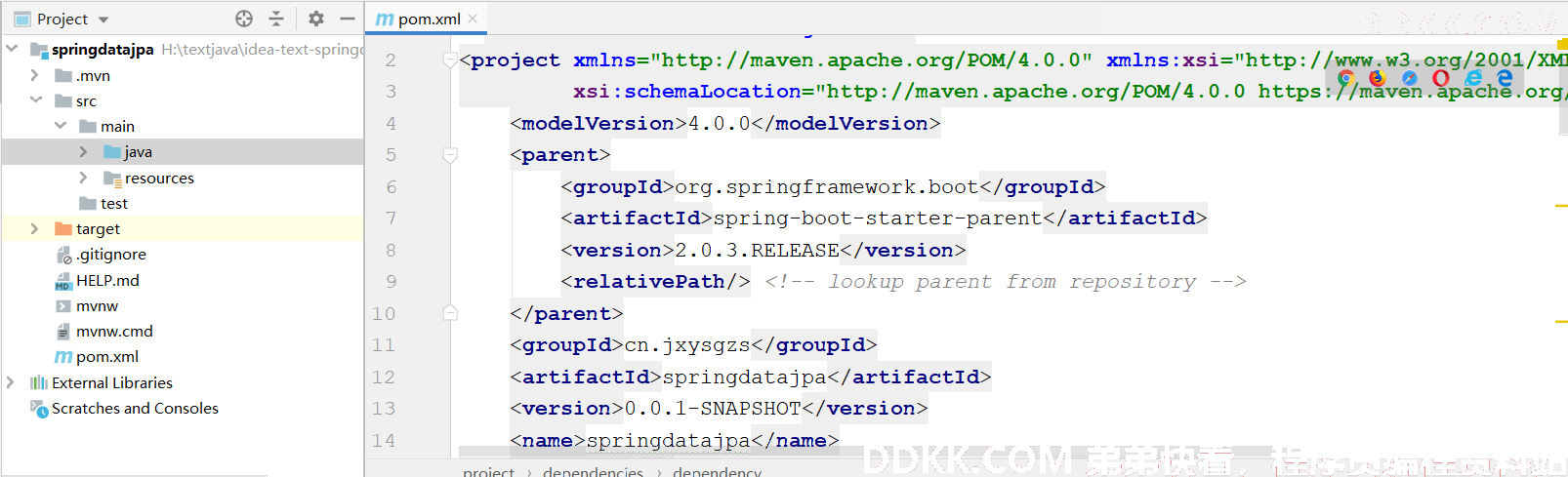
三、添加pom.xml与application.properties配置文件
注意:习惯使用application.yml的自己转换即可,因为笔者这个项目是spring快速构建工具构建,所以我直接使用现有的东西了!
1. pom.xml
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!--MVC-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- springData的启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- mysql数据库驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- druid数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.9</version>
</dependency>
</dependencies>
除了加上一个springData的启动器之外,其他的都是基本的使用mysql的环境
2.application.properties
####基础配置
#端口号
server.port=8080
####MySQL数据库连接源
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/springdatajpa?useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=《你的数据库密码》
####数据库连接池
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
####JPA配置
spring.jpa.hibernate.ddl-auto=update
#控制台输出sql语句
spring.jpa.show-sql=true
这个配置文件就有不少可说的了:
1、 这里我们需要指定一个名叫springdatajpa的数据库,编码utf-8,然后替换上你的数据库密码;
2、 JPA配置配置中spring.jpa.hibernate.ddl-auto共有4种参数,分别对应的含义我给大家列出来;
#ddl-auto:create----每次运行该程序,没有表格会新建表格,表内有数据会清空
#
#ddl-auto:create-drop----每次程序结束的时候会清空表
#
#ddl-auto:update----每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
#
#ddl-auto:validate----运行程序会校验数据与数据库的字段类型是否相同,不同会报错
通过上面的描述,大家应该能明白使用update的功能了吧,这样也算是提高JPA性能的一种方式哦!
四、创建springdatajpa数据库(MySQL)
创建数据库的方法我就不说了,命令或者图形化界面都可以,记得编码集要选utf-8
还有一个更值得注意的地方: 只需创建数据库即可,无需创建表,这样是jpa提供的一大好处,看了上面配置文件大家应该能明白一些,jpa是自动为我们创建表的,这样也很好的防止我们字段创建时写出错这种问题的,如果还是不太明白继续跟着操作下去即可,保证你写完本片之后一定可以弄懂的,否则笔者直播倒立吃*
创建库完成后:

五、创建对象映射类-——users
创建一个非常基本的用户类,一个id 一个账号 一个密码字段即可:
创建users.java
import javax.persistence.*;
/**
* 用户类。用于与数据users表映射
* @Date:2022/1/28
* @Description:cn.ddkk.springdatajpa.pojo
* @Version:1.0
*/
@Entity
@Table(name="t_users")
public class Users {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="userId")
private int userId;
@Column(name="userName")
private String userName;
@Column(name="userPwd")
private String userPwd;
public int getUserId() {
return userId;
}
public void setUserId(int userId) {
this.userId = userId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getUserPwd() {
return userPwd;
}
public void setUserPwd(String userPwd) {
this.userPwd = userPwd;
}
@Override
public String toString() {
return "Users{" +
"userId=" + userId +
", userName='" + userName + '\'' +
", userPwd='" + userPwd + '\'' +
'}';
}
}
一些注释的解释:
- @Entity 标注一下该类为对象类,并无实际用处
- @Table(name="t_users") 定义该类在数据库中对应的表 name属性为表名称
- @Id 定义该字段为主键
- @GeneratedValue(strategy=GenerationType.IDENTITY) 主键生成策略,这里也有不少的参数,给大家列举一下:
TABLE:使用一个特定的数据库表格来保存主键。
SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
IDENTITY:主键由数据库自动生成(主要是自动增长型)
AUTO:主键由程序控制。
所以,这里我们一般用数据库自动增长类型,符合大家的编程风格!
- @Column(name="userName") 定义该属性与数据库中的哪一表字段对应,name属性为表字段名称。
经过如上的各种定义,改类的对应表就基本生成了,表名称,属性名称,主键,主键生成策略。
六、创建一个dao
web项目一般都是controller–>service–>dao这三层,(现在也有四层的了)。
这里我们就不弄service层了,毕竟只是体验一下,没必要太麻烦!
创建usersJpaDao.java接口
package cn.ddkk.springdatajpa.dao;
import cn.ddkk.springdatajpa.pojo.Users;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
/**
* @author DDKK.COM 弟弟快看,程序员编程资料站
* @Date:2022/1/28
* @Description:cn.ddkk.springdatajpa.dao
* @Version:1.0
*/
public interface UsersJpaDao extends JpaSpecificationExecutor<Users>, JpaRepository<Users, Integer> {
}
你没看错,dao层就这些东西,但是增删改查各种特殊查询分页之类的已经可以实现了,如果还有实现不了的只需要在加一点点东西就可以实现,这里先不演示太复杂的了,先插入一个用户试试吧!
关于继承的两个父类我稍微解释一下吧,深层一点的后面在介绍:
- . JpaRepository
<Users, Integer>
参数一 T :当前需要映射的实体
参数二 ID :当前映射的实体中的OID的类型
该父类中继承了很多的CURD操作,继承关系比较复杂,后期剖析一下!
- JpaSpecificationExecutor
<Users>
该父类最主要是提供了多条件查询的支持,并且可以在查询中添加分页与排序
注意:此接口单独存在的,没有任何集成,所以要配合JpaRepository一起使用
七、写一个controller
这个controller直接写到启动类上即可,大家可一定要看清啊
import cn.ddkk.springdatajpa.dao.UsersJpaDao;
import cn.ddkk.springdatajpa.pojo.Users;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
@RestController
public class SpringdatajpaApplication {
@Autowired
private UsersJpaDao usersJpaDao;
public static void main(String[] args) {
SpringApplication.run(SpringdatajpaApplication.class, args);
}
@GetMapping("/insertUser")
public Users insertUser(@RequestParam("userName")String userName,@RequestParam("userPwd")String userPwd){
Users users=new Users();
users.setUserName(userName);
users.setUserPwd(userPwd);
return this.usersJpaDao.save(users);
}
}
使用UsersJpaDao接口时可以看到里面有很多的方法,save()便是jpa提供的插入方法,也可以用于修改,至于到底如何使用决定用于参数对象中是否有重复主键
八、大功告成,测试
1.启动之前咱们先看下数据库

可以看到这里是没有表也不可能有任何数据的
2.启动springboot项目出现如下打印信息即为成功
3.这时我们在看一下数据库,数据中多了一个我们在第五步骤中@Table(name="t_users")所命名的表
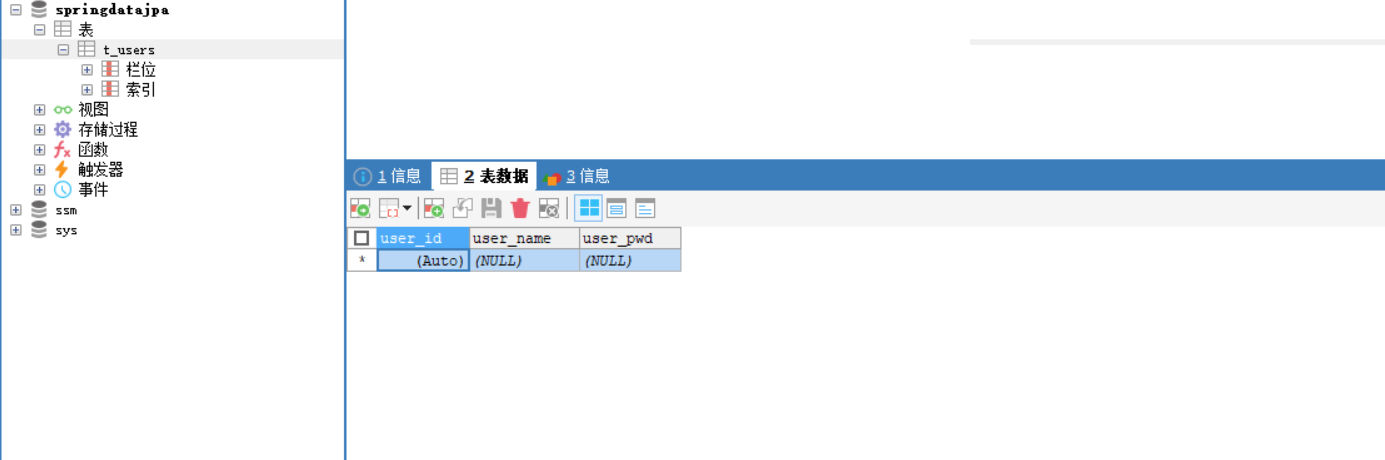 眼下这个表还没有任何数据,我们来调用一下我们写的接口试试
眼下这个表还没有任何数据,我们来调用一下我们写的接口试试
4、调用接口,插入数据.
浏览器输入 http://localhost:8080/insertUser?userName=zhangsan&userPwd=123456接口
这里可以看到我们插入对象是没有userId这个字段的,大家在看一下返回值
 返回如上信息表示成功了。可以看到返回信息中userId出现了,则可以证明我们配置的主键生成策略也成功了。
返回如上信息表示成功了。可以看到返回信息中userId出现了,则可以证明我们配置的主键生成策略也成功了。
5、最后在搂一眼数据库吧
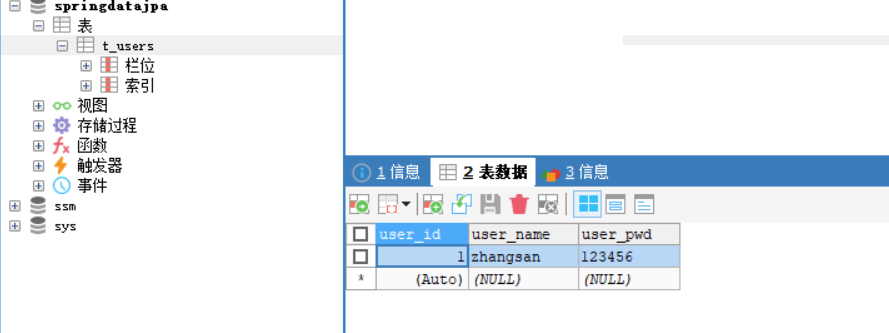 数据库也有值了。
数据库也有值了。
九、小结
这便是基础的体验一下springDataJpa的功能了,可能大家暂时还感受不到它的巨大魔力,可能只是觉得少写了一点sql语句而已,其实它不仅仅只有这些用处,还会在你突然想增加或者修改字段名称的时候提供巨大帮助,有兴趣的朋友可以亲自试试。
另外,笔者这是第一次写教程,抱着帮大家一点是一点和闲来无事莫打游戏的态度为大家写下的教程,希望大家可以受益,另外笔者若有失误或者本身就是错误的地方欢迎指正,笔者会第一时间查看且修改的。